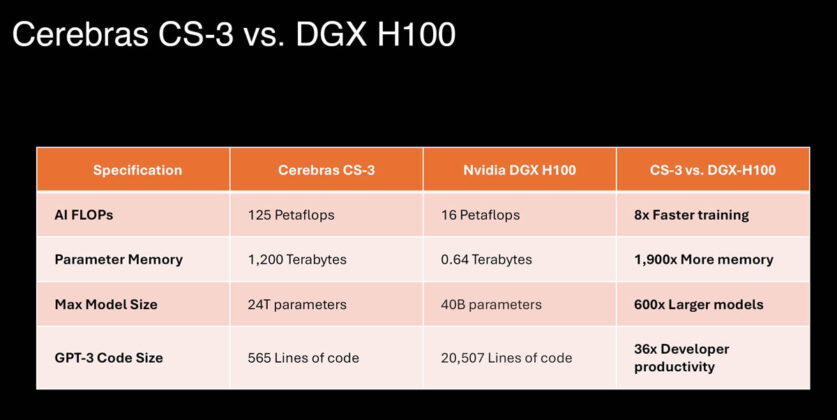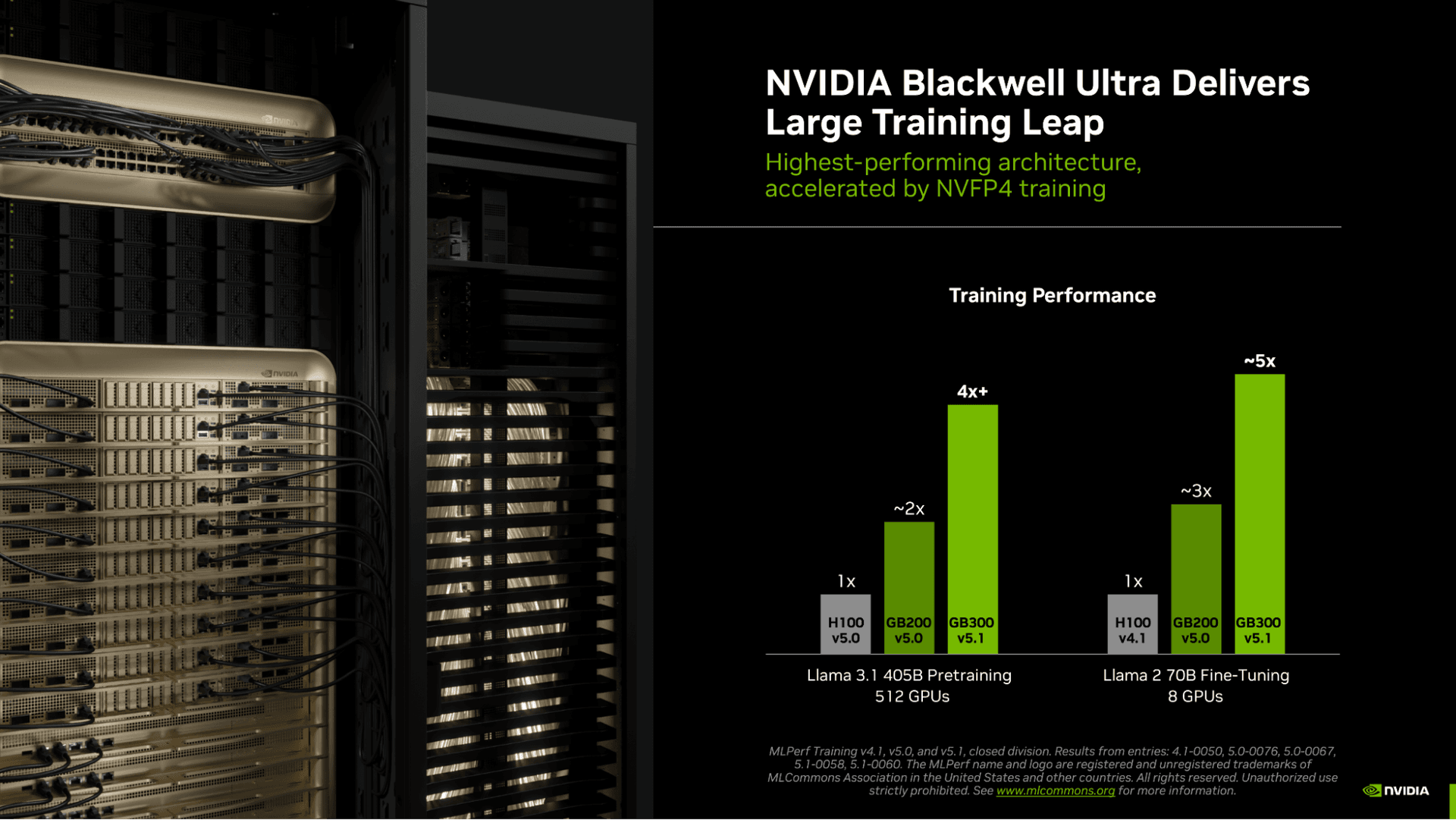
NVIDIA's NVFP4 4-bit format on Blackwell GPUs delivers up to 1.8x training speedup over FP8 in JAX/MaxText. The company claims no accuracy loss versus FP8 for models up to 70B parameters.
Key facts
- NVFP4 delivers 1.8x training speedup over FP8 on Blackwell.
- Format packs two 4-bit values into a single 8-bit register.
- No accuracy loss claimed for models up to 70B parameters.
- MaxText now includes native FP4 support.
- Blackwell has dedicated FP4 tensor cores, absent in H100.
NVIDIA announced NVFP4, a 4-bit floating-point precision format for Blackwell GPUs, integrated into Google's MaxText LLM training library built on JAX. According to the NVIDIA Technical Blog the format packs two 4-bit values into a single 8-bit register, effectively doubling arithmetic density versus FP8 while maintaining dynamic range through a shared exponent scheme. NVIDIA benchmarked NVFP4 on a GPT-3 175B model training run, achieving the 1.8x throughput improvement with no accuracy degradation reported for models up to 70B parameters. The company did not disclose results for larger models or provide full ablation tables.
Why FP4 Matters Now
The timing aligns with NVIDIA's broader push into lower-precision training as model sizes cross trillion-parameter thresholds. Blackwell's architecture includes dedicated FP4 tensor cores, a hardware feature absent from Hopper (H100) GPUs. This gives Blackwell a concrete advantage for pre-training and fine-tuning workloads where memory bandwidth is the bottleneck — reducing per-parameter memory footprint by 2x versus FP16 and 1.5x versus FP8. For a 175B model, that translates to roughly 87 GB saved at FP4 versus FP16, potentially enabling larger batch sizes or reduced pipeline parallelism.
The JAX Ecosystem Angle
MaxText, Google's open-source LLM training library, now supports NVFP4 natively. This is notable because MaxText is the primary training framework for Gemini models at Google DeepMind. [Per Google's relationship graph] Google is both a major NVIDIA customer and a competitor in AI hardware via TPUs. By baking NVFP4 into MaxText, NVIDIA ensures that Google's internal training stack — and any external user of MaxText — can immediately leverage Blackwell's lower precision without custom kernel development. The integration covers both forward and backward passes, according to the blog.
Accuracy Claims Under Scrutiny
NVIDIA's claim of "no accuracy loss versus FP8" warrants skepticism. The company tested on models up to 70B parameters but did not release perplexity scores, downstream task evaluations, or convergence curves. For comparison, FP8 training often requires loss scaling and gradient clipping to maintain stability; FP4 compounds quantization noise. Without independent reproduction — especially for models in the 100B+ range — the safe assumption is that FP4 will introduce some degradation that may be acceptable for certain workloads (e.g., fine-tuning) but not others (e.g., pre-training from scratch).
What to watch

Independent reproduction of FP4 accuracy at 175B scale, ideally by Google DeepMind using MaxText on Blackwell clusters. Also watch for FP4 support in PyTorch and whether AMD's MI400 series counters with its own 4-bit format.
Source: news.google.com