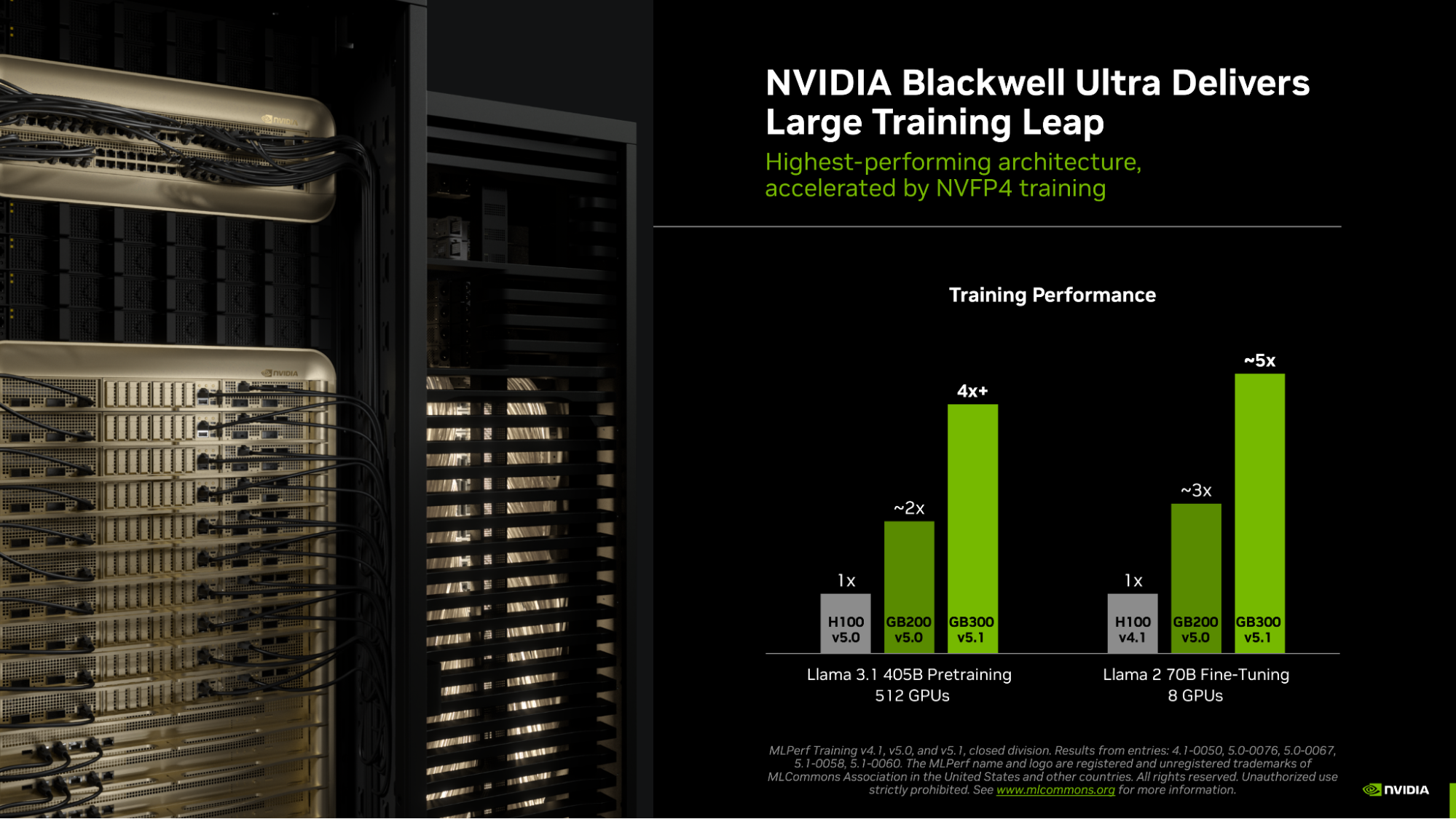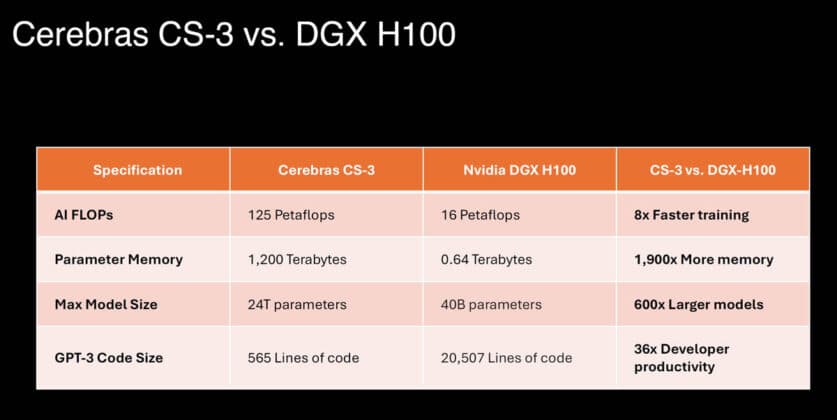
Cerebras Systems claims its wafer-scale chips match Nvidia H100 GPU performance on AI training workloads. The company reported comparable throughput per watt in internal benchmarks, challenging Nvidia's hardware dominance.
Key facts
- Cerebras CS-2 has 2.6 trillion transistors on a single wafer
- Nvidia H100 delivers 1,979 TFLOPS FP8 tensor performance
- Cerebras claims comparable throughput per watt to H100
- Google and Microsoft each consumed >20 TWh in 2025 data centers
- Cerebras software ecosystem lags CUDA's 15-year head start
Cerebras Systems, the Sunnyvale-based AI chipmaker, has released a video demonstrating its wafer-scale processors rivaling Nvidia's H100 GPUs on AI training tasks [According to the YouTube video from Cerebras]. The company claims its CS-2 system achieves throughput per watt comparable to Nvidia's flagship accelerator, a metric increasingly critical as AI data-center power costs soar.
The Wafer-Scale Advantage

Cerebras' approach differs radically from Nvidia's. Instead of stitching together thousands of small GPU dies via high-bandwidth interconnects, Cerebras builds a single enormous chip — the size of an entire silicon wafer — with 2.6 trillion transistors and 850,000 AI-optimized cores. This eliminates the need for complex distributed training setups for models that fit on one chip, reducing both latency and energy overhead. The company claims this architecture delivers linear scaling for models up to the chip's memory capacity, avoiding the communication bottlenecks that plague multi-GPU clusters.
How the Benchmark Stacks Up
Cerebras did not disclose exact benchmark numbers or the specific model architectures tested, making direct comparison difficult. Nvidia's H100, based on the Hopper architecture, has been the de facto standard for large-scale AI training since its 2022 launch, powering most of the industry's leading models including GPT-4 and Gemini. The H100 delivers 1,979 TFLOPS of FP8 tensor-core performance and has been validated across thousands of production deployments. Cerebras' claim of parity, if independently verified, would mark a significant milestone for alternative AI hardware — but the lack of third-party benchmarks leaves the assertion unproven.
The Ecosystem Challenge
Even if Cerebras matches H100 performance, it faces a steeper climb: software ecosystem. Nvidia's CUDA platform, now over 15 years old, has accumulated hundreds of thousands of optimized libraries, frameworks, and trained engineers. Cerebras relies on its own Cerebras Software Platform (CSoft), which supports common frameworks like PyTorch and TensorFlow but lacks the depth of CUDA's ecosystem. Google, a major Nvidia customer and competitor with its own TPU line, has publicly stated that moving workloads off CUDA requires significant engineering investment — a hurdle Cerebras must overcome to win enterprise customers.
Power Efficiency as the Real Battleground
While raw performance parity is noteworthy, the more consequential claim in Cerebras' video is throughput per watt. AI data centers now consume as much electricity as entire countries — Google and Microsoft each reported data-center energy consumption exceeding 20 TWh in 2025. If Cerebras' wafer-scale architecture delivers true power efficiency advantages, it could upend the cost calculus for hyperscale deployments. Nvidia's H100 has a 700W TDP; Cerebras' CS-2 draws 15 kW for the entire system, including cooling. The relevant metric is not just flops but flops per watt per dollar — and on that front, Cerebras may have a structural advantage that Nvidia's GPU-cluster architecture cannot easily replicate.
What to watch
Watch for independent benchmarks from MLPerf or a major cloud provider like Google Cloud or Microsoft Azure. If Cerebras secures a public deployment with a hyperscaler and publishes third-party training throughput numbers, the Nvidia-vs-Cerebras comparison will shift from marketing claim to credible alternative. Also monitor Cerebras' IPO plans — the company filed confidentially in 2025.
Source: youtube.com