In a post on X, Wharton professor and AI researcher Ethan Mollick proposed that AI labs should begin publishing a new type of document with each major model release: a detailed "changelog."
This document would go beyond the standard model card—which typically covers high-level capabilities, training data, and safety evaluations—to provide a granular, task-by-task breakdown of how a new model version changes, breaks, or improves upon its predecessor.
Key Takeaways
- AI researcher Ethan Mollick argues labs should release a 'changelog' alongside model cards, detailing performance changes on individual tasks.
- This would increase transparency as model updates become more frequent.
What's Being Proposed?
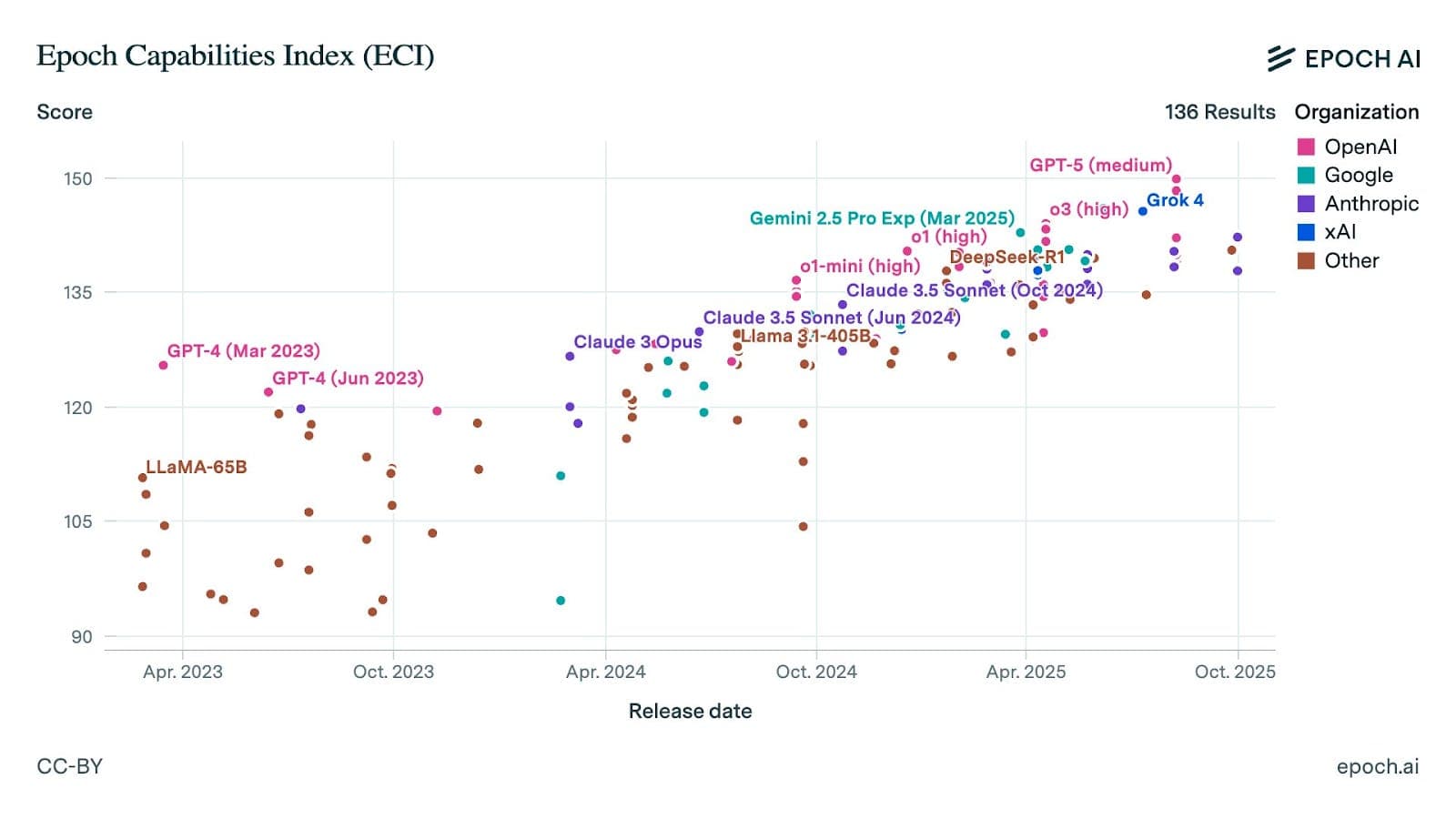
Mollick's core argument is that as AI models are updated with increasing frequency, users and developers need clearer visibility into what exactly changes between versions. A model might show an overall improvement on aggregate benchmarks but could simultaneously regress on specific, critical tasks that are vital for certain applications.
A proper changelog would answer practical questions:
- Does the new model write Python code better but become worse at summarizing legal documents?
- Has its ability to follow complex, multi-step instructions improved, or has it become more verbose?
- Are there new, unexpected failure modes on previously reliable tasks?
This level of detail is increasingly important for enterprises and developers building on top of these models, where unexpected regressions can break production systems or alter user experience.
The Current Transparency Gap
Today, when a lab like OpenAI, Anthropic, or Google DeepMind releases a new model (e.g., GPT-4.5, Claude 3.7, or Gemini 2.0), they typically publish a technical report or blog post highlighting key improvements and showcasing performance on standard academic benchmarks like MMLU, GPQA, or MATH.
However, these benchmarks are often broad aggregates that mask performance on narrower, real-world tasks. A model's score might increase from 88% to 89% on MMLU, but that 1-point gain doesn't tell a developer whether its performance on their specific use case—like generating API documentation or translating technical jargon—has improved, stayed the same, or gotten worse.
Mollick's proposal seeks to close this gap by mandating a more application-oriented disclosure that maps progress (and regressions) at the task level.
Why This Matters Now
The push for changelogs comes as the pace of model releases accelerates. In 2024-2025, major labs moved from releasing new flagship models every 12-18 months to shipping updates every few months. This rapid iteration, while driving progress, creates evaluation fatigue and makes it difficult for downstream users to keep up with what each version actually does differently.
Without standardized changelogs, users are left to either:
- Run their own extensive (and costly) evaluation suites on every new model.
- Rely on anecdotal evidence from community forums.
- Blindly update and hope nothing breaks.
A formal changelog would shift some of this evaluation burden back to the labs, which have the resources to conduct comprehensive testing.
Implementation Challenges

Creating a useful changelog is not trivial. It requires:
- Defining a standard set of tasks: What constitutes a "task" worthy of tracking? Labs would need to agree on a taxonomy covering coding, reasoning, creative writing, summarization, instruction following, and domain-specific skills.
- Measuring performance consistently: Establishing reliable, automated evaluation for each task to ensure comparisons are fair across versions.
- Avoiding information overload: A changelog with thousands of micro-tasks would be unusable. It would need to be curated to highlight the most significant changes.
Despite these challenges, the concept aligns with broader industry movements toward AI transparency and accountability, similar to how software libraries use semantic versioning and detailed release notes.
gentic.news Analysis
Mollick's proposal taps into a growing and critical tension in AI deployment: the need for stable, predictable APIs versus the reality of rapidly evolving underlying models. As we covered in our analysis of Anthropic's Claude 3.5 Sonnet release, labs are fiercely competing on benchmark leadership, but these leaderboard scores often correlate poorly with developer experience and real-world utility. A model can top a benchmark while introducing subtle regressions that disrupt workflows.
This call for changelogs follows a pattern of increasing scrutiny on AI lab reporting practices. In late 2025, researchers from Stanford's Center for Research on Foundation Models criticized the trend of "benchmark cherry-picking", where labs highlight only their best-performing evaluations. A standardized changelog would be a concrete step toward more holistic reporting.
Furthermore, this aligns with regulatory trends. The EU AI Act and similar frameworks emerging in the US emphasize transparency for general-purpose AI models. A detailed changelog could become a compliance tool, providing auditable evidence of a model's evolution and its impact on downstream systems.
For practitioners, the adoption of changelogs would be a major win. It would enable more informed decisions about when to upgrade, help pinpoint the cause of sudden performance drops in applications, and provide a clearer map of a model's strengths and weaknesses over time. The onus is now on the major labs to respond. Will they see this as an unnecessary burden or as an opportunity to build greater trust with their developer ecosystems?
Frequently Asked Questions
What is an AI model changelog?
An AI model changelog is a proposed document that would detail, task by task, how a new version of a model performs compared to its immediate predecessor. It would explicitly list improvements, regressions, and new capabilities, functioning like detailed software release notes but for AI model behavior.
How is a changelog different from a model card?
A model card is a static document describing a model's high-level characteristics, intended uses, limitations, and ethical considerations at its initial release. A changelog would be a comparative document released with each new version, focusing specifically on what has changed since the last model, with granular detail on individual tasks and capabilities.
Why don't AI labs already do this?
Creating a comprehensive, task-level changelog requires significant additional evaluation work. Labs may be hesitant due to the resource cost, the potential to highlight regressions (which could be seen as a negative), and the lack of an industry standard. Currently, competitive pressure focuses more on touting aggregate benchmark wins than on documenting nuanced changes.
Would a changelog slow down AI development?
It's unlikely to slow core research, but it could encourage more deliberate and thoroughly tested releases. The extra evaluation overhead might slightly extend the time between public releases, but it would likely lead to more stable and predictable models for developers, potentially reducing downstream breakage and saving ecosystem-wide debugging time.