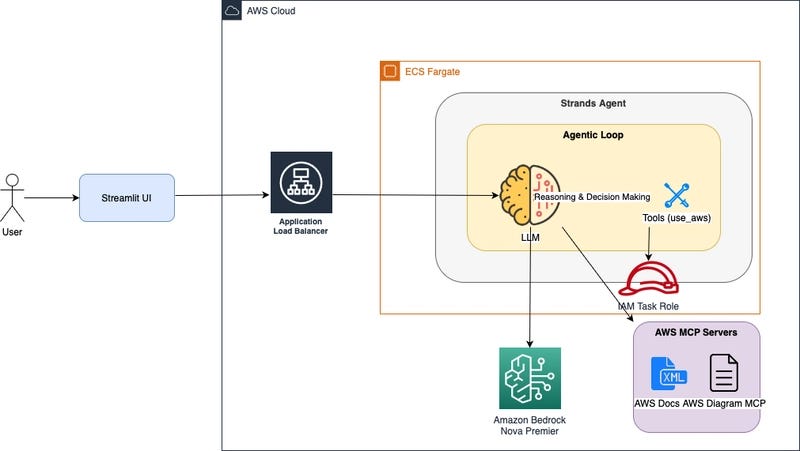
A developer on X (formerly Twitter) has reported a notable output from OpenAI's GPT-5.5 model, claiming it generated "the best SVG I've seen so far" from a single prompt. The user, @kimmonismus, shared their reaction with the post: "im speechless. GPT-5.5 created the best SVG i've seen so far. One shot. We are in for a wild ride."
Key Takeaways
- A developer shared that OpenAI's GPT-5.5 produced a sophisticated SVG image from a single prompt.
- This suggests improvements in the model's ability to generate precise, structured visual code.
What Happened
The report is anecdotal and based on a single user's experience. The attached image in the tweet shows a detailed and aesthetically complex SVG (Scalable Vector Graphics) graphic. SVGs are XML-based vector image formats that define graphics using code—shapes, paths, text, and filters. Generating coherent, functional, and visually appealing SVG code from a natural language prompt is a challenging multimodal task, requiring the model to translate abstract descriptions into precise, hierarchical markup.
The key claim here is the "one shot" nature of the generation, implying the model produced a satisfactory, complex output without requiring iterative refinement or debugging from the user—a common hurdle with earlier code-generation models.
Context: The Evolution of Multimodal Code Generation
This report fits into the ongoing trajectory of large language models (LLMs) expanding beyond pure text into code and structured data generation. OpenAI's models have progressively improved their coding capabilities, with GPT-4 demonstrating strong proficiency in languages like Python and JavaScript.
SVG generation sits at a specific intersection: it requires understanding of visual design principles, spatial relationships, color theory, and the strict syntax of XML-based markup. Success here suggests a model is not just stitching together code snippets but may be building a internal representation of the desired visual output and then expressing it correctly in code.
Previous state-of-the-art for this task often involved specialized models or multi-step processes using image generation models paired with vectorization tools. A general-purpose LLM performing well in a single step would represent a significant consolidation of capabilities.
Limitations of the Report
It is crucial to note this is a single, unsourced anecdote. Without access to:
- The exact prompt used
- The full generated SVG code
- Comparative benchmarks against other models (e.g., GPT-4, Claude 3.5, Gemini 1.5 Pro)
- Systematic testing across a range of SVG complexity levels
it is impossible to quantify GPT-5.5's true capability or improvement over its predecessors. The evaluation is subjective ("the best I've seen") and may reflect the particular prompt or the user's specific use case.
gentic.news Analysis
This user report, while anecdotal, points to a critical, under-discussed frontier in AI: the generation of precise, structured output formats beyond prose and simple code. If validated, GPT-5.5's apparent proficiency in SVG generation signals a deeper mastery of syntax and semantics for descriptive markup languages. This isn't just about writing a function; it's about constructing a visual hierarchy in code form, which requires a more robust spatial and compositional understanding.
This development aligns with the broader industry trend of models becoming more capable "generalist practitioners." As we covered in our analysis of Claude 3.5 Sonnet's Artifacts feature, the frontier is shifting from mere conversation to the creation of complex, usable digital artifacts. SVG generation is a natural extension of this, bridging the gap between descriptive instruction and functional, renderable asset creation. It also hints at potential future capabilities in generating other structured formats like LaTeX for complex documents, circuit diagrams in SVGs, or even 3D scene descriptors.
For practitioners, the implication is to start stress-testing these newer models on tasks that require precise structural output. The benchmark is moving from "does the code run?" to "does the generated structure produce the intended, complex artifact correctly on the first try?" This report, if indicative of a broader capability, suggests we may be closer to that threshold for certain formats.
Frequently Asked Questions
What is SVG generation, and why is it difficult for AI?
SVG (Scalable Vector Graphics) is an XML-based format for defining two-dimensional vector graphics. Generating it requires an AI to understand a text description of a visual scene, then translate that into correctly nested XML elements with precise coordinates, shapes, paths, and styling attributes. It's difficult because it combines visual reasoning with strict, error-intolerant syntax—a single misplaced tag can break the entire image.
How does GPT-5.5's reported SVG capability compare to other AI image generators?
Traditional AI image generators like DALL-E 3 or Midjourney output raster images (pixel grids). GPT-5.5 is reportedly generating the source code (SVG) for an image. This is fundamentally different: the output is editable, scalable to any size without quality loss, and often much smaller in file size. It's a code generation task with a visual output, not an image synthesis task.
Should I use GPT-5.5 for generating SVG graphics based on this report?
This is a single, unverified user experience. For production work, you should conduct your own systematic tests. Provide the model with your specific prompts, evaluate the correctness and cleanliness of the generated SVG code, and compare its performance and cost against other available models or specialized tools. Anecdotes are useful for spotting trends, but not for making technical decisions.
What would be a more rigorous test of an AI's SVG generation ability?
A rigorous evaluation would involve a benchmark dataset of diverse prompts (e.g., "a red bicycle with a basket," "a technical architecture diagram," "a stylized logo of a fox"). Each model's output would be scored on: 1) Syntax Validity (does the SVG parse correctly?), 2) Visual Fidelity (does the rendered image match the prompt, scored by humans or a vision model?), and 3) Code Efficiency (is the SVG code reasonably compact and well-structured?).