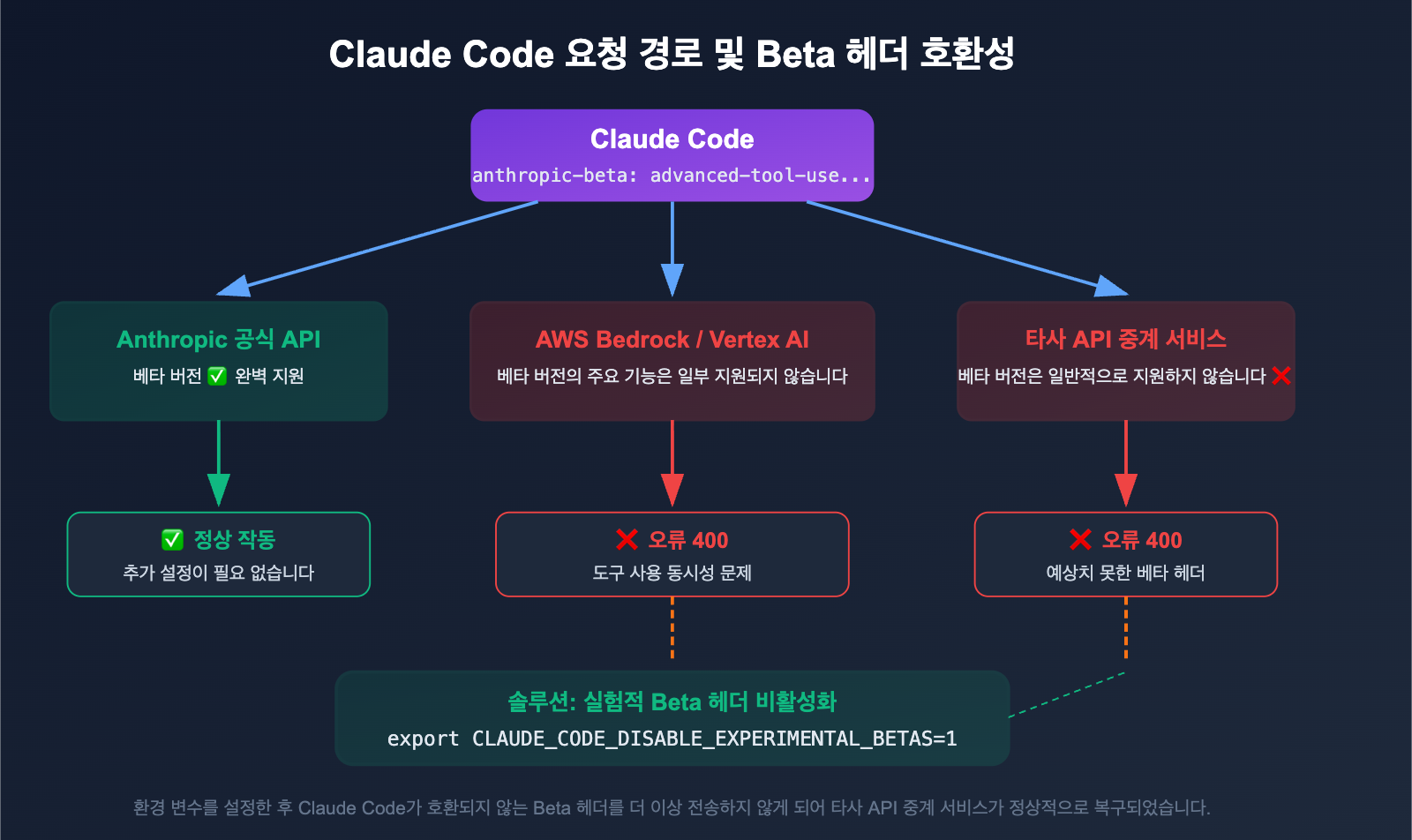
LLM-powered data pipelines beat regex for structured extraction from unstructured documents at scale, a CodeToDeploy technical report argues. The method handles 20+ invoice formats without per-format rule maintenance.
Key facts
- LLM handles 20+ invoice formats without per-format rules.
- Regex passes unit tests but breaks on unseen formats.
- Compute cost vs. developer time is the key trade-off.
- Report does not disclose throughput or cost per document.
- Pipeline fits MLOps paradigm for production ML reliability.
Your regex-based extraction pipeline is lying to you. It passes every unit test, handles the twenty invoice formats your team has seen. But the twenty-first format arrives, or a vendor tweaks a field, and suddenly your extraction breaks silently. LLM-powered data pipelines extract structured data from unstructured documents at scale. The method reduces maintenance cost of manual parsing rules.
How It Works
The pipeline uses a large language model (LLM) to parse document text into structured fields—e.g., invoice number, date, total amount. Instead of writing regex patterns per format, the LLM interprets the document's semantic structure. The report claims this approach generalizes across 20+ invoice formats without per-format tuning.
The key trade-off: compute cost per document versus developer time maintaining regex rules. The report does not disclose exact throughput or cost per document. But for high-volume extraction (thousands of invoices daily), the compute cost may offset engineering hours spent on rule maintenance.
MLOps Context
This fits into the broader MLOps paradigm of deploying and maintaining ML models in production reliably and efficiently. The pipeline requires monitoring for drift—if invoice formats shift, the LLM's extraction quality may degrade. The report does not discuss drift detection or retraining schedules. MLOps practitioners would need to add observability layers.
Unique Take
The AP wire would frame this as "AI improves document processing." The actual story: LLM pipelines shift maintenance burden from rule-writing to compute cost and model monitoring. The long-term cost comparison—engineering time vs. inference API fees—is the real decision point, not raw accuracy. The report is thin on that comparison. [Source: CodeToDeploy]
What to watch
Watch for real-world cost-per-document benchmarks from companies deploying LLM extraction pipelines at scale. If inference costs drop below $0.001 per document, regex-based systems will become legacy for most enterprise document processing.