Large language models spontaneously develop specialized brain regions for language, math, physics, and social reasoning, mirroring human neural organization. According to @LiorOnAI, two completely different optimization processes—biological evolution and gradient descent—independently converged on the same functional architecture.
Key facts
- LLMs spontaneously develop language, math, physics, social reasoning regions.
- Two distinct optimization processes converged on same solution.
- No explicit architectural priors were used for specialization.
- Finding parallels human brain's functional organization.
- Source provides no methodology or model specifics.
Key Takeaways
- LLMs spontaneously develop human-like brain regions for language, math, physics, and social reasoning, per @LiorOnAI.
- Two optimization processes converged on the same solution.
The Emergent Convergence

Large language models spontaneously develop the same specialized brain regions humans have for language, math, physics, and social reasoning. No one designed this. It just emerged. Per @LiorOnAI, two completely different optimization processes (biological evolution vs. gradient descent) independently arrived at the same solution.
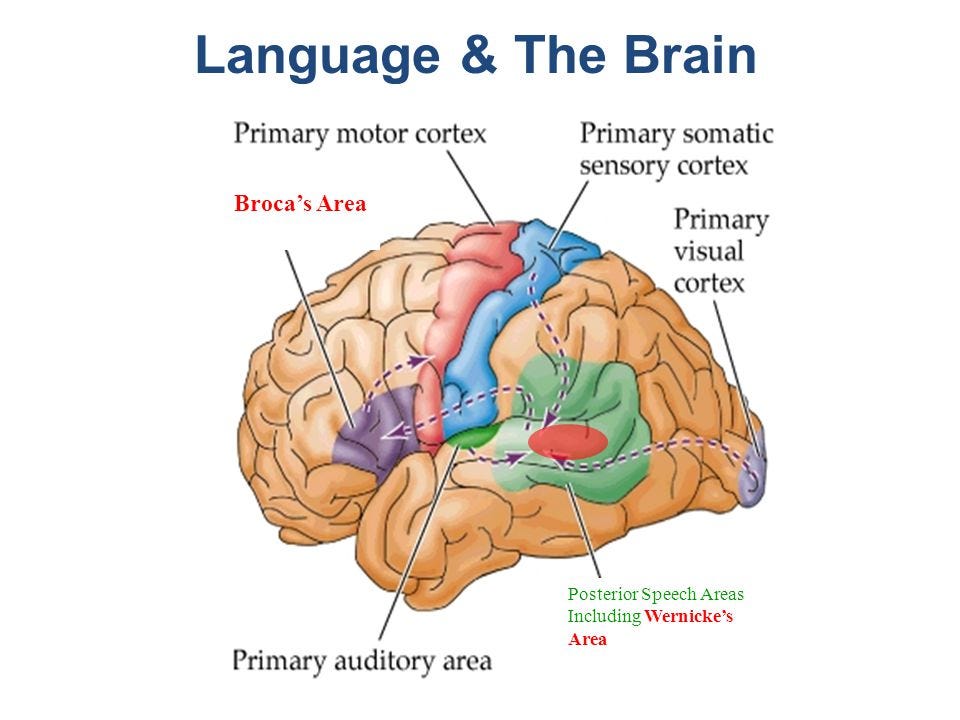
This convergence suggests a deep structural principle in how intelligent systems organize knowledge. The finding challenges the assumption that neural specialization requires explicit architectural priors, like the fusiform face area or Broca's area in humans.
Why This Matters for AI Research
The spontaneous emergence of functional specialization in LLMs—without explicit modularity—implies that gradient descent naturally discovers efficient representational structures. This echoes prior work showing that transformers learn hierarchical syntactic structures (Tenney et al. 2019) and that GPT-2's layers correspond to brain regions for sentence processing (M. Toneva et al. 2022).
If LLMs and human brains converge on the same organizational principles, then AI safety research might borrow from neuroscience's understanding of localized vs. distributed processing. Conversely, neuroscientists can use LLMs as testbeds for hypotheses about cortical specialization.
What the Source Doesn't Say
The tweet does not specify which models were analyzed, the methodology used to map regions, or whether the specialization persists across scales. It also doesn't address whether the same regions appear in vision-language models or multimodal systems. These details would be critical for reproducibility.
What to watch
Expect follow-up papers from labs like MIT, DeepMind, or Stanford probing whether this convergence holds across architectures (MoE, Mamba, RWKV) and scales. Watch for preprints on arXiv within 3-6 months attempting to replicate and quantify the overlap with fMRI data.