
The fundamental shift from using Large Language Models (LLMs) as isolated text generators to deploying them as the "brains" of autonomous, goal-driven AI agents hinges on one critical component: persistent memory. A new technical analysis breaks down the architectures and orchestration techniques required to build stateful AI systems that can learn, adapt, and operate reliably over long-term tasks.
At its core, the problem is one of statelessness. While LLMs possess vast embedded knowledge and reasoning capability, they lack any inherent mechanism to remember past interactions. This forces developers to repeatedly inject context into the prompt, ballooning token usage, increasing latency, and crippling efficiency for sustained operations. The analysis frames modern AI agents as systems where the LLM acts as a CPU, requiring a structured memory subsystem—inspired by human cognition and computer architecture—to function effectively.
The Multi-Layered Memory Architecture
Effective agent memory is not a monolithic block of text. The analysis outlines a hierarchical model mirroring human and computational systems:
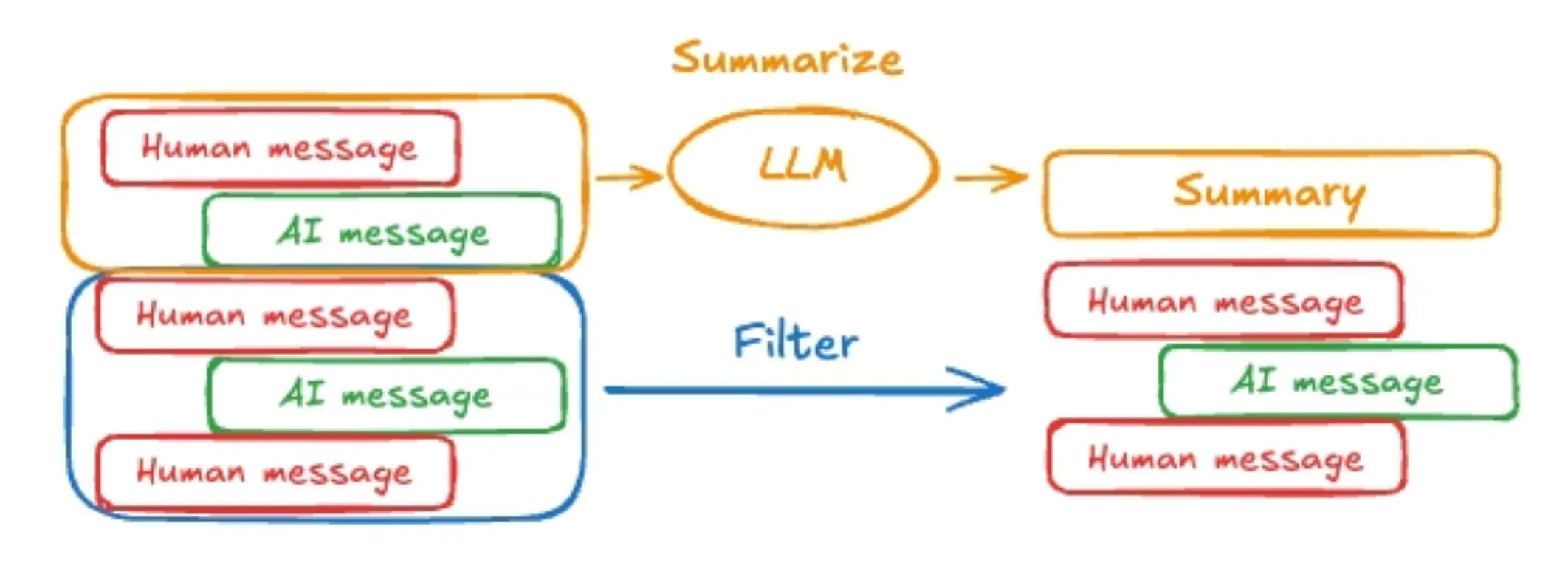
- Short-Term (Working) Memory: This is the model's active context window. It holds the immediate conversation history, system prompts, tool outputs, and the agent's own reasoning steps. Due to strict token limits, management is crucial. Simple FIFO (First-In, First-Out) queues are common but risk discarding critical information. Advanced systems implement smarter eviction policies based on recency, relevance, and predicted future need.
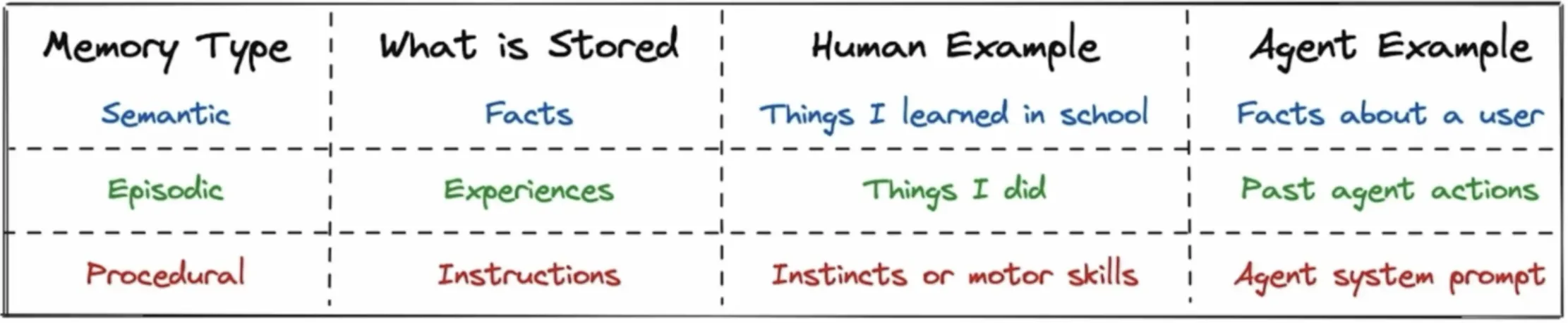
- Long-Term Memory: This external storage is segmented into specialized types:
- Episodic Memory: Records specific events and interactions (e.g., "User asked for a report on Project X at 10 AM").
- Semantic Memory: Stores distilled facts, concepts, and knowledge extracted from episodes (e.g., "Project X is related to quantum computing").
- Procedural Memory: Retains learned skills, tool-use patterns, and successful action sequences.
This separation allows the agent to efficiently retrieve the right type of information. A query about a past meeting triggers episodic recall, while a request for a definition pulls from semantic memory.
Key Frameworks and Techniques for Memory Management
Building and maintaining this hierarchy requires specialized frameworks and algorithms. The analysis highlights several leading approaches:

- MemGPT: Introduces an operating system-like memory hierarchy. The LLM manages a limited "working memory" context and explicitly controls the swapping of less-important information to external storage ("disk"), retrieving it only when needed. This allows agents to operate over contexts far exceeding their native window.
- CoALA (Compositional Agents with Large Language Models): This framework formally separates an agent's decision-making processes (the "controller") from its memory (the "memory modules"). It treats memory as a structured system with explicit read, write, and query operations, moving beyond treating memory as raw conversation history.
- Semantic Consolidation & Intelligent Forgetting: To prevent memory bloat and degradation, systems must compress information. This involves summarizing lengthy episodes into core semantic facts and proactively "forgetting" redundant or irrelevant details—a process analogous to human memory consolidation during sleep.
- Conflict Resolution: When new information contradicts stored memory, systems need rules to resolve conflicts, such as timestamp-based overwriting or maintaining multiple conflicting memories with confidence scores.
The analysis also mentions frameworks like LangMem and Zep as solutions providing scalable, vector-database-backed memory stores with automatic embedding, retrieval, and summarization for agentic systems.
Why This Matters: Solving the Reliability Gap
Without robust memory, AI agents suffer from critical failures:
- Memory Drift: The agent's understanding of a task or fact degrades over a long conversation as relevant context is evicted from the window.
- Context Degradation: Performance drops in multi-step tasks where later steps depend on information from earlier steps that are no longer in context.
- Hallucinations: The agent may invent facts to fill gaps caused by missing historical context.
These failures directly impact real-world reliability. As the analysis notes, memory design is not an optional feature but a prerequisite for agents that can handle complex, longitudinal tasks like ongoing customer support, multi-session coding projects, or personal AI assistants that learn user preferences over time.
Short-Term / Working CPU Cache / Human Working Memory Recent chat, tool outputs, reasoning Token limit eviction policies Long-Term Episodic Application Logs / Autobiographical Memory Specific interaction events Summarization, temporal indexing Long-Term Semantic Database / Conceptual Knowledge Distilled facts & concepts Conflict resolution, updating Long-Term Procedural Script Library / Muscle Memory Learned skills & action sequences Generalization, versioninggentic.news Analysis
This deep dive into memory architecture arrives at a pivotal moment for agentic AI. It directly addresses the systemic reliability gap highlighted in a recent industry report we covered, which found that 86% of AI agent pilots fail to reach production. A primary cause of such failures is the agent's inability to maintain state and context across interactions, leading to erratic behavior and broken workflows. The frameworks discussed here—MemGPT, CoALA—represent the foundational infrastructure needed to move agents from brittle prototypes to robust production systems.
The trend towards formalized memory subsystems aligns with the broader industry shift NVIDIA's CEO Jensen Huang recently declared, where all future software becomes agentic. For that vision to materialize, agents cannot be stateless. The comparison of different memory frameworks (LangMem, Mem0, Zep) also reflects a maturing ecosystem where developers can choose specialized tools rather than building from scratch, accelerating adoption.
Furthermore, this analysis complements recent research, such as the paper that identified multi-tool coordination as the primary failure point for AI agents. Effective tool-use across multiple steps is impossible without a memory system that can track the state of the world, past actions, and their results. The memory architectures described are the substrate upon which reliable multi-step orchestration is built. As the field moves from single-query tasks to longitudinal agentic workflows, investment in and understanding of these memory systems will become the differentiator between functional demos and transformative applications.
Frequently Asked Questions
What is the main difference between an LLM's context window and an AI agent's memory?
An LLM's context window is a fixed, temporary buffer for the immediate input prompt. It is stateless and resets after each call. An AI agent's memory is a persistent, structured storage system that exists outside the LLM. The agent can selectively read from and write to this memory across multiple sessions, allowing it to learn, retain user preferences, and continue long-running tasks.
How does a framework like MemGPT prevent hitting token limits?
MemGPT implements a virtual memory management system, analogous to an operating system. The LLM (the "CPU") operates within a limited context window ("RAM"). When this space fills up, the LLM itself decides which pieces of information to page out to a larger, slower external storage ("disk"), such as a vector database. It can later page that information back in when needed, allowing it to manage contexts that are theoretically unlimited in size.
What is "memory drift" and why is it a problem?
Memory drift occurs when an AI agent's understanding of a fact or task degrades over the course of a long interaction because the key contextual information has been pushed out of its limited working memory. This leads to inconsistencies, repetition, and hallucinations. For example, an agent helping to write code might forget the name of a key variable defined earlier, causing errors or generating incorrect syntax.
Are these memory systems only for text-based agents?
While the current analysis and frameworks are primarily designed for LLM-based agents, the architectural principles apply broadly. Agents that process multimodal inputs (vision, audio) would require memory systems capable of storing and retrieving embeddings from those modalities. The core concepts of short-term buffering, long-term semantic storage, and procedural memory are universal requirements for any persistent autonomous system.








