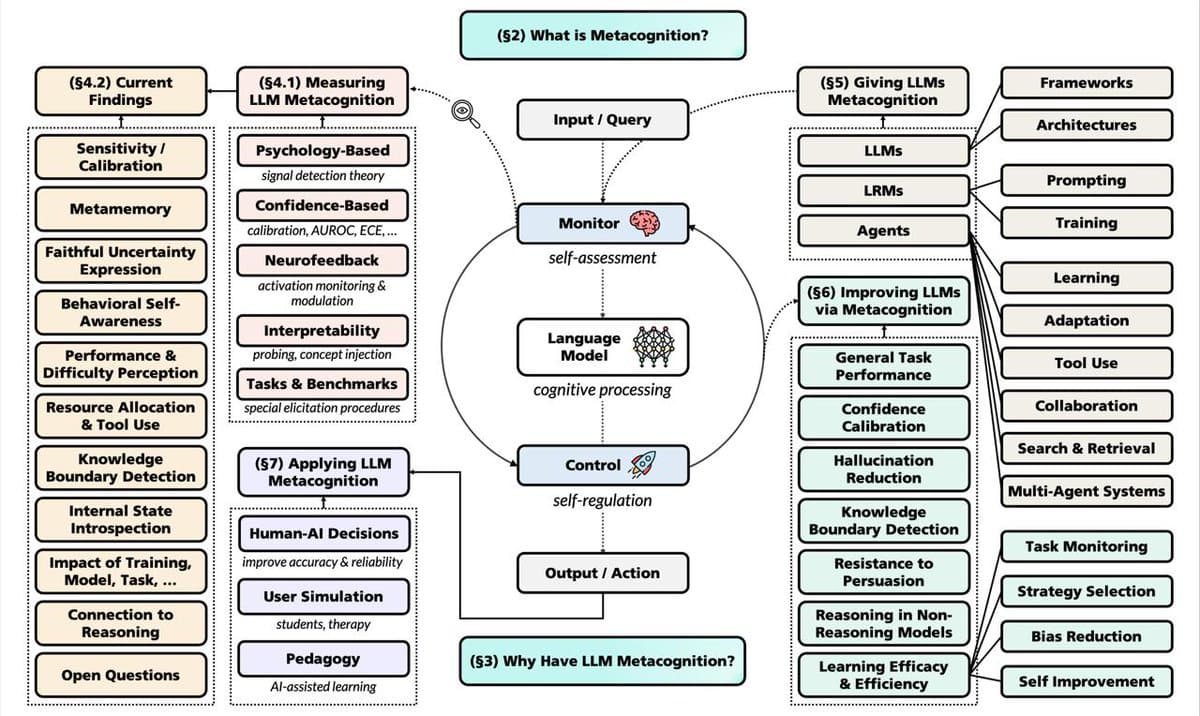
Key Takeaways
- Microsoft researchers introduced MEMENTO, a method where LLMs generate structured 'notes' during multi-step reasoning, reducing the memory footprint of the reasoning process by 3x while maintaining performance.
- This addresses a key bottleneck in deploying complex reasoning models.
What Happened

Microsoft Research has published a new paper detailing MEMENTO, a novel method designed to dramatically reduce the memory consumption of large language models (LLMs) during complex, multi-step reasoning tasks. The core innovation is teaching the model to generate concise, structured summaries—or "notes"—of its own intermediate reasoning steps, rather than retaining the full, verbose chain of thought. This approach compresses the reasoning context, reportedly achieving a 3x reduction in memory usage without a corresponding drop in task performance.
The problem MEMENTO tackles is fundamental: advanced reasoning techniques like Chain-of-Thought (CoT) or Tree-of-Thoughts require the model to generate and then process many intermediate tokens. Storing this entire internal "scratchpad" consumes significant memory, which becomes a major bottleneck for deploying these powerful reasoning models in resource-constrained or cost-sensitive environments.
Technical Details
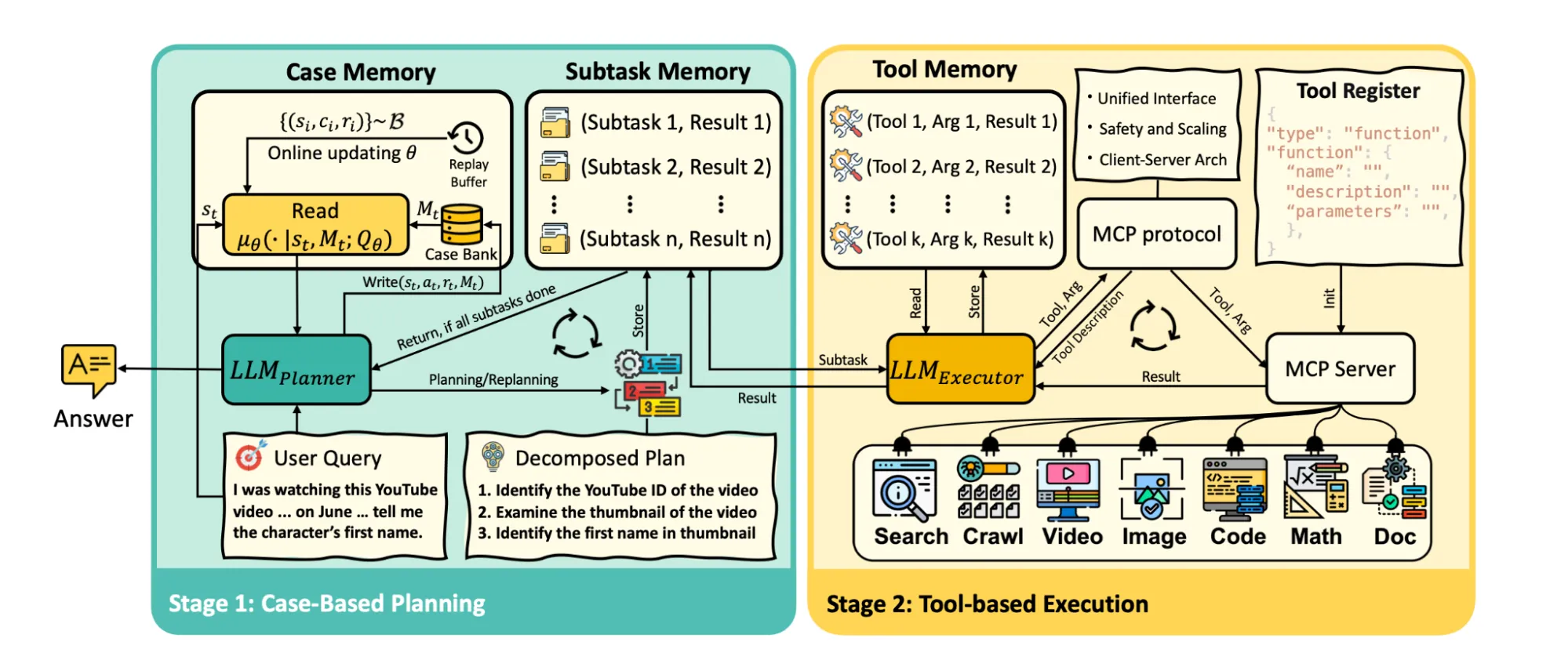
MEMENTO operates by integrating a note-taking mechanism into the reasoning process. Instead of appending every raw reasoning step to the context, the model is trained or prompted to periodically pause and produce a condensed summary of what it has deduced so far. These summaries act as checkpoints, capturing the essential logical state. The model then uses these notes, rather than the full history, to continue its reasoning.
This is distinct from simply truncating context. The notes are semantically rich, preserving the crucial information needed for accurate continuation. The method is model-agnostic and can be applied to various reasoning frameworks. The reported 3x memory reduction directly translates to the ability to handle longer, more complex reasoning chains within the same hardware constraints or to significantly lower the cost of operation.
Retail & Luxury Implications
The immediate implication for retail and luxury AI teams is cost and scalability for advanced reasoning applications. Many high-value use cases in the sector require complex logic:
- Hyper-personalized Campaign Reasoning: An LLM that reasons through a customer's lifetime value, past purchases, real-time browsing behavior, and campaign goals to generate a perfect offer requires multi-step logic. MEMENTO could make running hundreds of thousands of these reasoning jobs per hour more viable.
- Supply Chain & Demand Forecasting Analysis: Models that reason over disparate data sources (historical sales, weather, social sentiment, economic indicators) to provide narrative explanations for forecast adjustments are memory-intensive. Reducing this cost lowers the barrier to implementation.
- Automated Customer Service Escalation: Systems that reason through a complex customer complaint, policy documents, and past interactions to determine the optimal resolution path could be deployed more broadly.
Currently, many of these applications are either simplified or run at high cost. MEMENTO, as a research concept, points a path toward making them more economical. However, it is not a plug-and-play solution. Integrating such a note-taking protocol into existing production pipelines would require careful engineering and validation to ensure the note compression does not degrade quality in subtle ways specific to a brand's domain.