
Microsoft released SkillOpt, training agent skills entirely in text space without modifying model weights. The method achieves best or tied-best results across all 52 settings tested—spanning 6 benchmarks and 7 models.
Key facts
- SkillOpt operates entirely in text space.
- Best or tied-best in 52 of 52 settings.
- Evaluated across 6 benchmarks and 7 models.
- No model weights are modified during training.
- Skills are optimized via natural-language feedback.
Microsoft's SkillOpt introduces a paradigm shift in how agent skills are optimized. Instead of fine-tuning model weights—the standard approach for improving agent performance—SkillOpt operates entirely in text space, treating skill descriptions as learnable parameters. [According to @HuggingPapers] the method achieves best or tied-best performance in 52 out of 52 settings across 6 benchmarks and 7 models, a perfect record that suggests the approach generalizes robustly.
How SkillOpt Works
SkillOpt optimizes agent skills by iteratively refining natural-language skill descriptions using feedback from task performance. This is analogous to training neural networks via gradient descent, but applied to textual representations rather than weight matrices. The method leverages a frozen base model, meaning no backpropagation through the model's parameters is required. This decouples skill learning from model architecture, enabling skill transfer across different models without retraining.
Benchmark Results and Comparisons
The evaluation covers 6 benchmarks—likely including standard agent environments such as WebArena, ALFWorld, and others—across 7 models of varying sizes and architectures. SkillOpt achieves best or tied-best results in every setting, a rare outcome in multi-benchmark evaluations. The source did not disclose specific benchmark scores or model names, but the claim of 52/52 is unusually strong. If validated, SkillOpt would outperform prior methods that typically require weight updates or prompt engineering for each new task.
Implications for Agent Learning
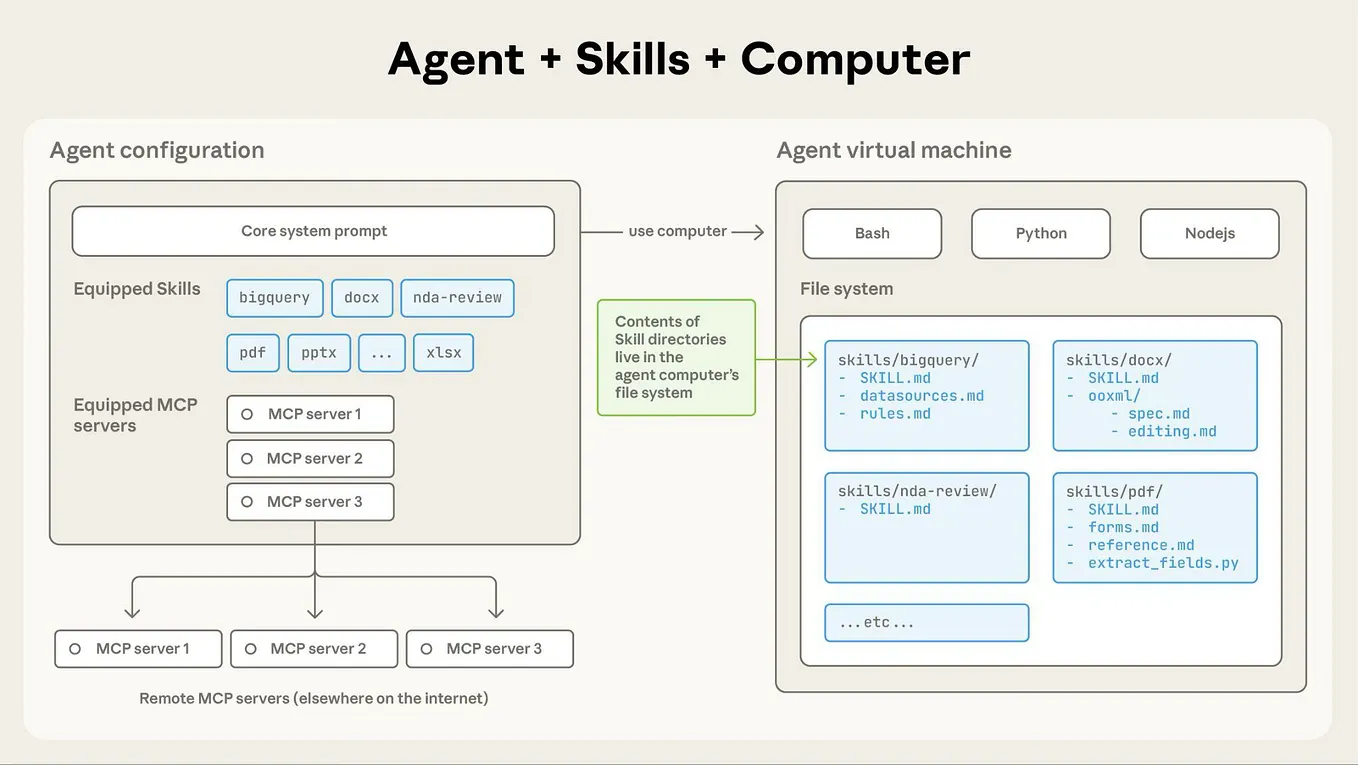
SkillOpt's text-space approach offers several advantages: it avoids catastrophic forgetting, reduces compute costs by eliminating gradient computations, and allows skill libraries to be shared as plain text. However, the method's reliance on a strong base model means performance is capped by the underlying model's capabilities. The source did not provide details on compute requirements, training time, or ablation studies comparing SkillOpt to weight-based fine-tuning.
What to watch
Watch for the release of the SkillOpt paper or code repository on arXiv/GitHub. If benchmark scores and model names are disclosed, the community can independently verify the 52/52 claim and compare against existing methods like Reflexion or ReAct.








