What Happened
A significant new study from arXiv:2603.11245, titled "Mind the Sim2Real Gap in User Simulation for Agentic Tasks," provides the first rigorous, large-scale validation of LLM-based user simulators against real human behavior. As NLP evaluation shifts from static benchmarks to multi-turn interactive settings, LLM simulators have become ubiquitous as user proxies for two purposes: generating realistic user turns during development and providing evaluation signals for agent performance.
The research team formalized the concept of the "Sim2Real" gap in this context and conducted a comprehensive benchmark involving 451 real human participants completing 165 interactive tasks. They evaluated 31 different LLM simulators across proprietary, open-source, and specialized model families using a new metric they introduced: the User-Sim Index (USI), which quantifies how closely an LLM simulator's interactive behavior and feedback resemble that of a real human user.
Technical Details & Key Findings
The study reveals systematic and significant deviations between simulated and real user behavior, challenging a core assumption in current agentic AI development pipelines.
1. Behavioral Divergence: The "Easy Mode" Problem
LLM simulators exhibit patterns that create an artificially favorable environment for the AI agent being tested:
- Excessive Cooperativeness: Simulated users are far more compliant, helpful, and easier to satisfy than real humans. They rarely express frustration, give up, or become ambiguous in ways that complicate the agent's task.
- Stylistic Uniformity: While real humans display a wide variety of conversational styles, tones, and levels of detail, LLM simulators produce homogenized, "average" responses lacking in personality or idiosyncrasy.
- Lack of Realistic Ambiguity & Frustration: Real user interactions are messy. Humans get confused, change their minds mid-task, provide incomplete information, and express irritation. Current simulators largely sanitize these complexities away.
The consequence is that an agent's success rate when tested against LLM simulators is inflated above the true human baseline. An agent that performs well in simulation may fail or struggle when deployed with real customers.
2. Evaluation Signal Divergence
The gap extends beyond behavior to the quality of feedback used for evaluation and training:
- Nuance vs. Uniform Positivity: Real humans provided nuanced judgments across eight different quality dimensions (e.g., helpfulness, correctness, efficiency). In contrast, simulated users produced uniformly more positive, less discriminative feedback.
- Failure of Rule-Based Rewards: The study found that simple, rule-based reward signals (common in reinforcement learning setups for agents) fail to capture the rich, multi-dimensional feedback signals generated by human users.
3. Capability Does Not Equal Fidelity
A critical and perhaps counterintuitive finding is that higher general model capability (e.g., a larger, more powerful base LLM) does not necessarily yield a more faithful user simulator. Specialized fine-tuning or simulation architectures appear necessary to close the Sim2Real gap.
Retail & Luxury Implications
The findings of this study are not abstract; they strike at the heart of the burgeoning investment in agentic AI for retail and luxury. The industry is rapidly exploring AI agents for personalized shopping assistants, concierge services, complex customer support, and interactive recommendation systems (as hinted at in the accompanying news snippets about Shopify's "agentic storefronts" for ChatGPT and Blue Yonder's supply chain agents).

The Core Risk: Building on a Faulty Foundation
If luxury brands develop and evaluate these high-stakes, customer-facing agents primarily using flawed LLM simulators, they risk:
- Launching Agents That Annoy High-Value Clients: An agent trained in an "easy mode" simulator may lack the robustness to handle a VIP client's nuanced requests, frustration with an out-of-stock item, or ambiguous description of a desired style. The result could be a brand-damaging interaction.
- Misallocating R&D Resources: Teams may iterate on and "improve" an agent based on simulation metrics that do not correlate with real-world success, wasting time and capital.
- Overestimating Readiness: The inflated success rates from simulation could lead to premature deployment of agents that are not yet ready for prime time, especially in the high-touch, expectation-heavy luxury sector.
The Path Forward: Human-in-the-Loop Validation
The paper's primary recommendation is unambiguous: human validation is non-negotiable in the agent development cycle. For retail AI leaders, this translates to:
- Phased Testing: Use cost-effective LLM simulators for early-stage prototyping and stress-testing, but mandate human-in-the-loop evaluation in later stages, especially for use cases involving direct customer interaction.
- Invest in Specialized Simulation: Consider investing in or developing simulation environments fine-tuned on proprietary, de-identified customer interaction data to better capture brand-specific customer language and behavior.
- Redefine Success Metrics: Move beyond simple task completion rates. Develop evaluation frameworks that measure the nuanced qualities of a luxury interaction—empathy, style discernment, proactive problem-solving—which are precisely what current simulators fail to assess.
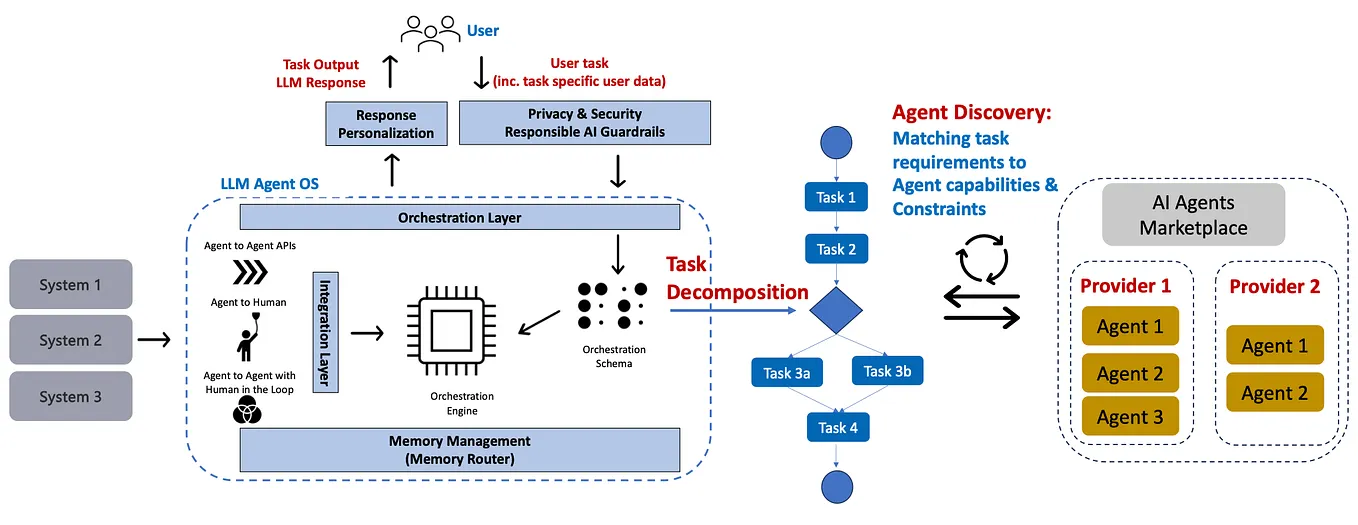
The accompanying news about Verified Multi-Agent Orchestration (VMAO) from arXiv:2603.11445 is highly relevant here. It demonstrates a framework where an LLM-based "verifier" agent coordinates specialized agents, improving answer completeness and quality. This points to a future architecture where a dedicated "realism verifier" or "human-behavior emulator" agent, trained on high-quality human interaction data, could be integrated into the development loop to pressure-test other agents, helping to close the Sim2Real gap from within the system itself.
In essence, this research is a crucial reality check. The promise of agentic AI in retail is immense, but its responsible and effective deployment depends on acknowledging and systematically addressing the gap between convenient simulation and complex human reality.