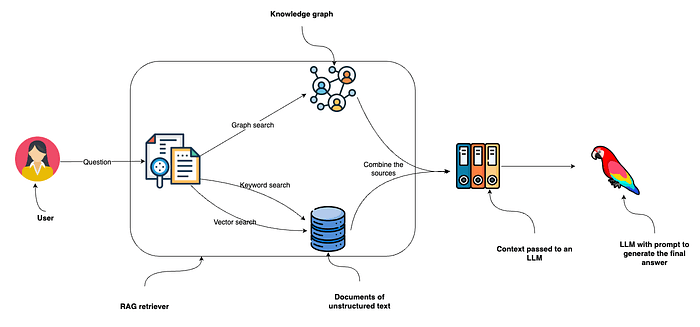
A new research paper from a collaboration including MIT, Oxford University, and Carnegie Mellon University presents a counterintuitive finding: AI assistance can improve human performance on tasks initially, but may subsequently lead to a degradation in performance as reliance on the AI grows.
The work, highlighted in a social media post by researcher Rohan Paul, investigates the dynamics of human-AI collaboration over time, moving beyond single-interaction studies to examine longitudinal effects.
Key Takeaways
- A collaborative paper from MIT, Oxford, and Carnegie Mellon reports AI assistance can improve human performance initially, but may lead to degradation over time due to over-reliance.
- This challenges the assumption that AI augmentation yields monotonic benefits.
What the Research Found

The core claim, as summarized, is that AI can boost performance at first and then lead to a decline. This suggests a non-monotonic relationship between AI assistance and human outcomes, where the benefits of augmentation are not guaranteed to persist. The decline is attributed to a potential erosion of human skill or critical engagement, a phenomenon often described as "automation complacency" or "skill atrophy."
While the specific tasks, AI systems, and performance metrics are not detailed in the brief source, the implication is clear: the researchers have identified a scenario where the long-term effect of AI assistance is negative, even if the short-term effect is positive.
The Broader Context of Human-AI Teaming
This research taps into a critical and growing subfield of AI safety and human-computer interaction (HCI) focused on effective human-AI teaming. Prior work has often focused on optimizing AI for a single decision or outcome. This paper shifts the focus to the temporal dimension of the interaction, asking how the human partner evolves when working alongside an AI over repeated engagements.
Key questions this line of research addresses include:
- Calibration of Trust: Do users correctly calibrate their trust in the AI based on its performance?
- Complementarity vs. Substitution: Does the AI complement human strengths or simply substitute for human effort, allowing skills to decay?
- Learning Dynamics: Can the AI be designed to teach the human, rather than just perform the task?
The finding of a performance decline aligns with concerns about over-reliance, where users uncritically accept AI suggestions without maintaining situational awareness or their own problem-solving capabilities. This is a known risk in fields like aviation, medicine, and driving, where automation can lead to degraded manual skills.
What This Means in Practice
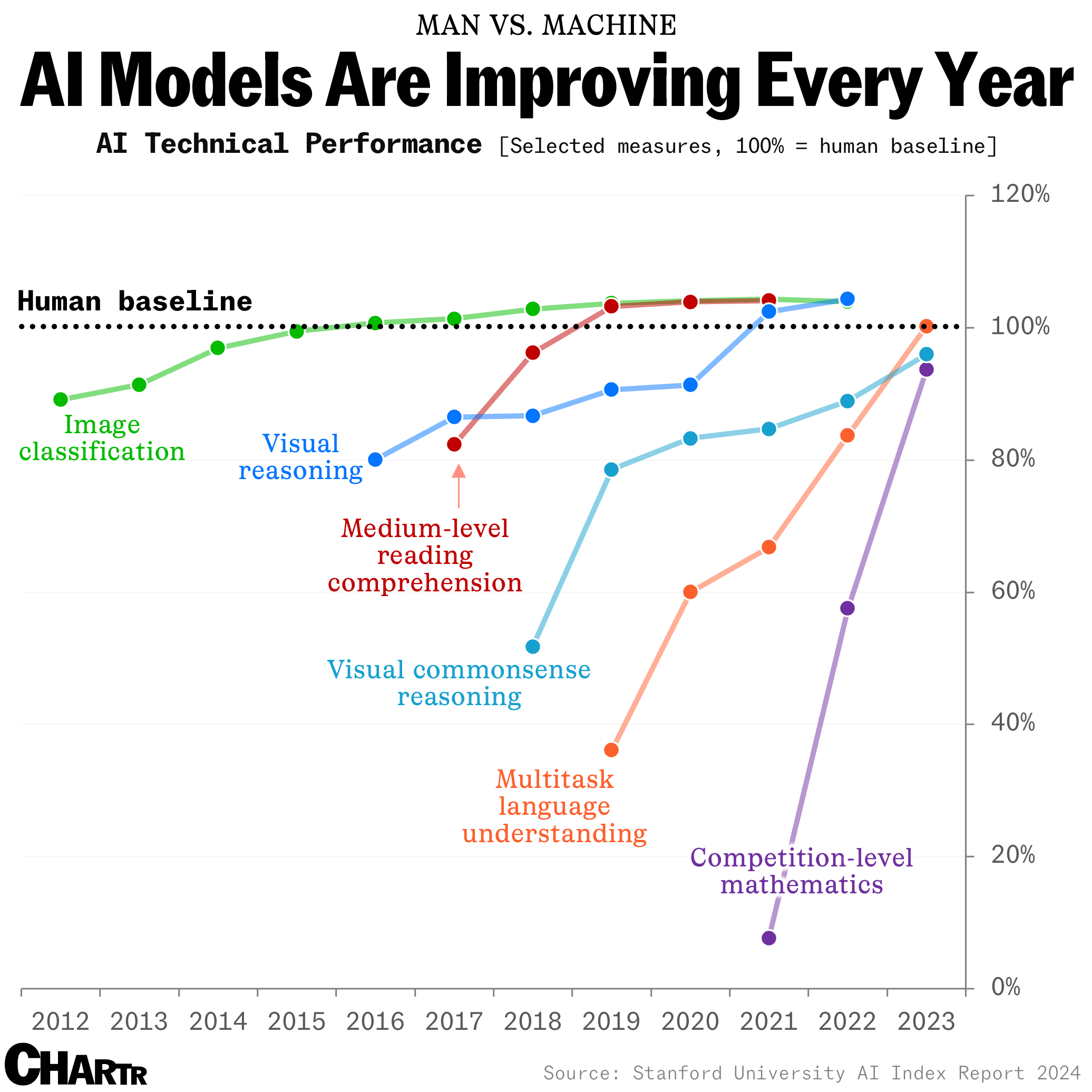
For developers and product managers building AI-assisted tools, this research is a cautionary note. Simply demonstrating that an AI tool improves task completion time or accuracy in a one-off lab study is insufficient. The long-term impact on the human user's independent capability must be considered. The optimal design might involve AI that fades support over time (scaffolding), actively identifies and corrects user errors to promote learning, or requires periodic manual execution of tasks to maintain proficiency.
gentic.news Analysis
This research from MIT, Oxford, and CMU directly intersects with a core tension in applied AI: the trade-off between efficiency and resilience. As we covered in our analysis of Google's "Project Ellmann" last December, the industry push is overwhelmingly towards deeper, more pervasive AI integration into human workflows. This paper serves as a crucial academic counterweight, providing empirical evidence for a risk that has been largely theoretical in many software domains.
The involvement of Carnegie Mellon is particularly notable. CMU's Human-Computer Interaction Institute (HCII) has been a leader in studying the longitudinal effects of technology, and this work fits squarely within that tradition. It also contrasts with the prevailing narrative from many AI labs, which often highlight only the performance-boosting aspects of their tools. For instance, our reporting on Anthropic's Claude 3.5 Sonnet detailed its benchmark gains but also noted user reports of its persuasive, conversational style potentially encouraging over-trust—a related concern.
Looking at the broader KG context, this paper adds a critical data point to the Human-AI Collaboration trend line, which has seen increased research activity throughout 2025 and into 2026. It suggests the next wave of AI product innovation won't just be about more capable models, but about smarter interaction paradigms that sustain human capability. Developers should watch for the full paper's release, which will likely propose and test specific mitigation strategies, potentially informing a new generation of "human-centric AI" design principles.
Frequently Asked Questions
What tasks did the MIT/Oxford/CMU study use?
The brief source does not specify the exact tasks. However, research in this domain typically uses structured decision-making tasks (e.g., medical diagnosis from images, financial forecasting, writing or coding assistance) where both the AI and human performance can be quantitatively measured over multiple trials.
Does this mean we shouldn't use AI assistants?
No, it does not suggest avoiding AI assistants altogether. The finding emphasizes the need for thoughtful design and usage. The goal is to create AI systems that augment human intelligence without eroding it—systems that collaborate as a "teammate" rather than act as a crutch. Users should remain actively engaged and periodically verify their understanding independently.
How can AI be designed to avoid this performance decline?
Potential design strategies include: implementing confidence scoring that requires user review for low-confidence AI suggestions, creating learning-focused interfaces that explain the AI's reasoning, designing adaptive assistance that reduces help as user proficiency increases, and building in mandatory "unassisted" practice modes to reinforce core skills.
Where can I find the full research paper?
The source is a social media post highlighting the finding. The full academic paper, once published, will likely be available on preprint servers like arXiv or through the digital libraries of the participating institutions (MIT, Oxford, Carnegie Mellon). Searching for key terms like "longitudinal AI assistance," "skill atrophy," and the authors' names will help locate it.