
A Medium post argues that training ML models is the easy part. Production deployment reveals data drift, monitoring gaps, and infrastructure debt that most tutorials skip.
Key facts
- Training framed as 'the easy part' of ML lifecycle.
- Data drift identified as primary production failure mode.
- Monitoring called out as under-invested discipline.
- No specific tools, vendors, or benchmarks referenced.
The post, published by Squadit on Medium, opens with a claim that resonates across engineering teams: training a machine learning model is, relatively speaking, the easy part. What comes next — deploying it to production, maintaining it — reveals a different set of challenges. [According to the post] the common failure patterns are not algorithmic but operational: data drift, model degradation, and the absence of robust monitoring pipelines.
The unique take: The piece frames MLOps not as a technology problem but as a people-and-process problem. It argues that the industry over-indexes on training frameworks and under-indexes on the engineering discipline required to keep a model serving correctly after launch. This mirrors a pattern visible across 2025–2026: companies like Uber, DoorDash, and Netflix have all published postmortems showing that production ML failures trace to data quality and monitoring gaps, not model architecture.
The post does not provide specific numbers, benchmark results, or named frameworks. It offers no concrete failure case studies, no cost estimates for monitoring infrastructure, and no empirical data on drift frequency. For a practitioner looking for actionable guidance, the piece reads more as a warning than a playbook.
Key facts from the post:
- Training is framed as "the easy part" relative to production.
- Data drift is identified as a primary failure mode.
- Monitoring is called out as an under-invested discipline.
- The piece does not reference specific tools, vendors, or benchmarks.
What to watch: Watch for follow-up posts from Squadit that include specific monitoring architectures, drift detection thresholds, or cost breakdowns. The MLOps community will benefit from empirical data on how often models degrade in production and what infrastructure spend is required to catch it.
What to watch
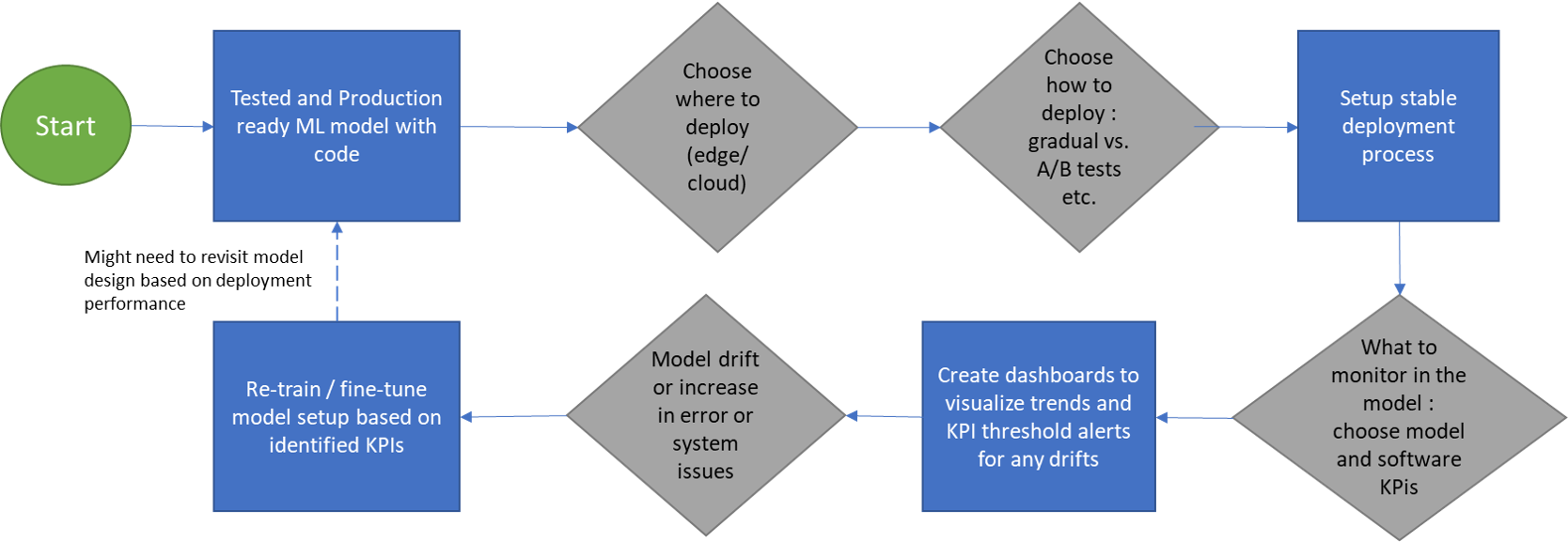
Watch for Squadit to publish a follow-up with specific monitoring architectures, drift detection thresholds, or cost breakdowns. The MLOps community needs empirical data on model degradation frequency and infrastructure spend to catch it.








