
A new research paper titled "On the Theoretical Limitations of Embedding-Based Retrieval" presents a sobering analysis of the fundamental constraints facing vector embedding systems that power modern search and recommendation engines. Published on arXiv, the work challenges the prevailing industry assumption that embedding limitations are merely practical problems solvable through more data and larger models.
What the Research Reveals
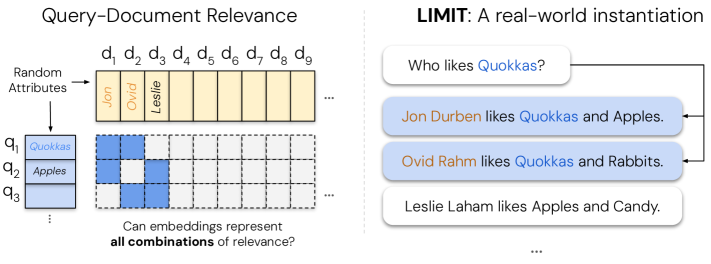
The paper establishes a direct connection between the dimensionality of embeddings and their expressive power for retrieval tasks. The core theoretical finding shows that the number of possible top-k document subsets that can be returned by any query is mathematically limited by the embedding dimension. This isn't just a theoretical curiosity—the researchers demonstrate that these limitations manifest even with "extremely simple queries" in realistic settings.
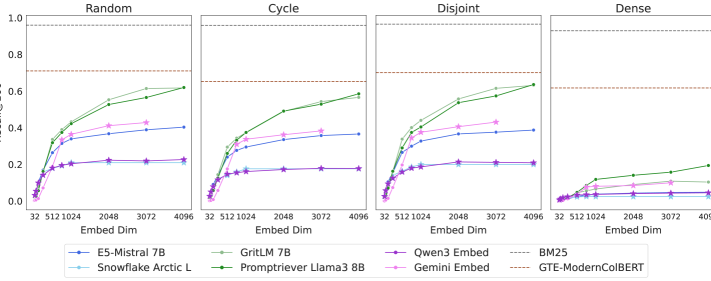
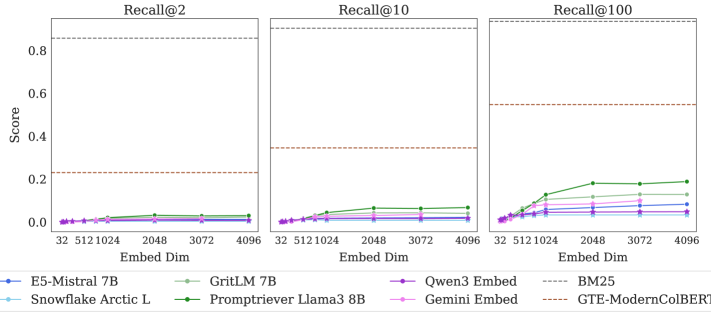
To validate their theoretical analysis, the researchers created a specialized dataset called LIMIT designed to stress-test embedding models against these theoretical boundaries. Even state-of-the-art embedding models failed on this dataset, despite the tasks being conceptually simple. The researchers further demonstrated that even when directly optimizing embeddings on test data (using "free parameterized embeddings"), the fundamental dimensional limitations persist.
One particularly striking finding: returning all possible pairs of documents as relevant results requires relatively high-dimensional embeddings, suggesting that complex multi-faceted relevance relationships may exceed the representational capacity of practical embedding systems.
Technical Implications for Retrieval Systems
The research points to a fundamental constraint in the "single vector paradigm" where both queries and documents are represented as fixed-dimensional vectors. While this approach has powered remarkable advances in semantic search and recommendation systems, the paper suggests there may be inherent ceilings to what can be achieved within this framework.
The authors connect their findings to established results in learning theory, providing a rigorous mathematical foundation for understanding these limitations. This represents a significant departure from the empirical, trial-and-error approach that often dominates embedding model development.
Retail & Luxury Implications
For retail and luxury companies that increasingly rely on embedding-based systems for:
- Semantic product search (understanding "summer evening dress for gala")
- Personalized recommendations (finding complementary items)
- Visual search (finding similar products from images)
- Customer intent understanding (matching queries to complex product attributes)
This research suggests there may be inherent limitations to how well these systems can understand and represent the nuanced relationships that define luxury retail. The challenge isn't just about having enough training data or sufficiently large models—there are mathematical boundaries to what can be expressed through fixed-dimensional vectors.
Consider a luxury fashion retailer trying to implement a sophisticated recommendation system that understands:
- Seasonal appropriateness
- Occasion suitability
- Style compatibility
- Price tier matching
- Brand aesthetic alignment
- Material complementarity
The research indicates that representing all these dimensions of relevance simultaneously through a single embedding vector may encounter fundamental representational limits. This could explain why even the most advanced recommendation systems sometimes produce puzzling or suboptimal suggestions.
The Path Forward
The paper concludes with a call for "future research to develop new techniques that can resolve this fundamental limitation." This suggests that the next generation of retrieval systems may need to move beyond the single-vector paradigm entirely.
Potential directions include:
- Multi-vector representations where documents and queries are represented by multiple embeddings
- Hierarchical embedding structures that can capture relationships at different levels of abstraction
- Hybrid systems that combine embeddings with symbolic or rule-based approaches
- Dynamic dimensionality where embedding size adapts to query complexity
For retail AI practitioners, this research serves as an important reminder that while embeddings have revolutionized information retrieval, they are not a panacea. Understanding their theoretical limitations is crucial for setting realistic expectations and guiding future system architecture decisions.
Practical Takeaways for Retail AI Teams
Benchmark against realistic complexity: The LIMIT dataset approach suggests that retail companies should develop their own stress tests that reflect the true complexity of their product relationships and customer queries.
Manage expectations: Recognize that embedding-based systems may have inherent accuracy ceilings for certain types of complex, multi-faceted retrieval tasks common in luxury retail.
Plan for hybrid approaches: Consider architectures that combine embedding-based retrieval with other techniques (rules, knowledge graphs, explicit metadata) for the most critical use cases.
Monitor for failure patterns: Be alert to systematic failure modes in your retrieval systems that might indicate hitting these theoretical limitations rather than mere data or model quality issues.
The research represents an important step toward more rigorous understanding of embedding systems' capabilities and limitations—knowledge that's essential for making informed architectural decisions in retail AI applications.








