
Peter Steinberger, the creator of the popular open-source AI agent framework OpenClaw, has issued a pointed critique of current trends in building autonomous AI workflows. In a recent statement, he argues that the "real failure" occurs when developers remove human oversight too early, expecting quality results without what he calls "human taste in the loop."
Key Takeaways
- Peter Steinberger, creator of the OpenClaw AI agent framework, argues that the core failure in agentic workflows is removing human judgment too soon.
- He asserts that strong output requires continuous human vision, steering, and questioning.
What Happened

Steinberger's core argument, shared via social media, is that successful agentic workflows—where AI agents perform multi-step tasks—cannot be fully automated from the start. He identifies three critical, human-driven components for "strong output":
- Vision: The overarching goal and creative direction.
- Steering: Continuous guidance and course-correction.
- The Right Questions: The ability to interrogate and refine the agent's process and output.
The warning suggests a growing tension in the AI engineering community between the push for full autonomy and the practical reality that complex, high-quality tasks still require human judgment.
Context: The Rise and Limits of AI Agents
Steinberger's OpenClaw is a significant player in the burgeoning field of AI agent frameworks. These systems, which chain together reasoning, tool use, and action, have been a major focus of development in 2025 and 2026. Projects like OpenAI's o1, Anthropic's Claude 3.5 Sonnet with its high tool-use capabilities, and numerous open-source efforts have pushed the boundaries of what agents can accomplish autonomously on benchmarks like SWE-Bench for coding.
However, Steinberger's comment highlights a recurring theme in practical deployments: benchmark performance doesn't always translate to reliable, high-quality real-world results. The failure mode he describes—premature removal of human oversight leading to subpar or unusable outputs—is a common pain point for teams integrating agents into production pipelines for design, content creation, or complex analysis.
gentic.news Analysis
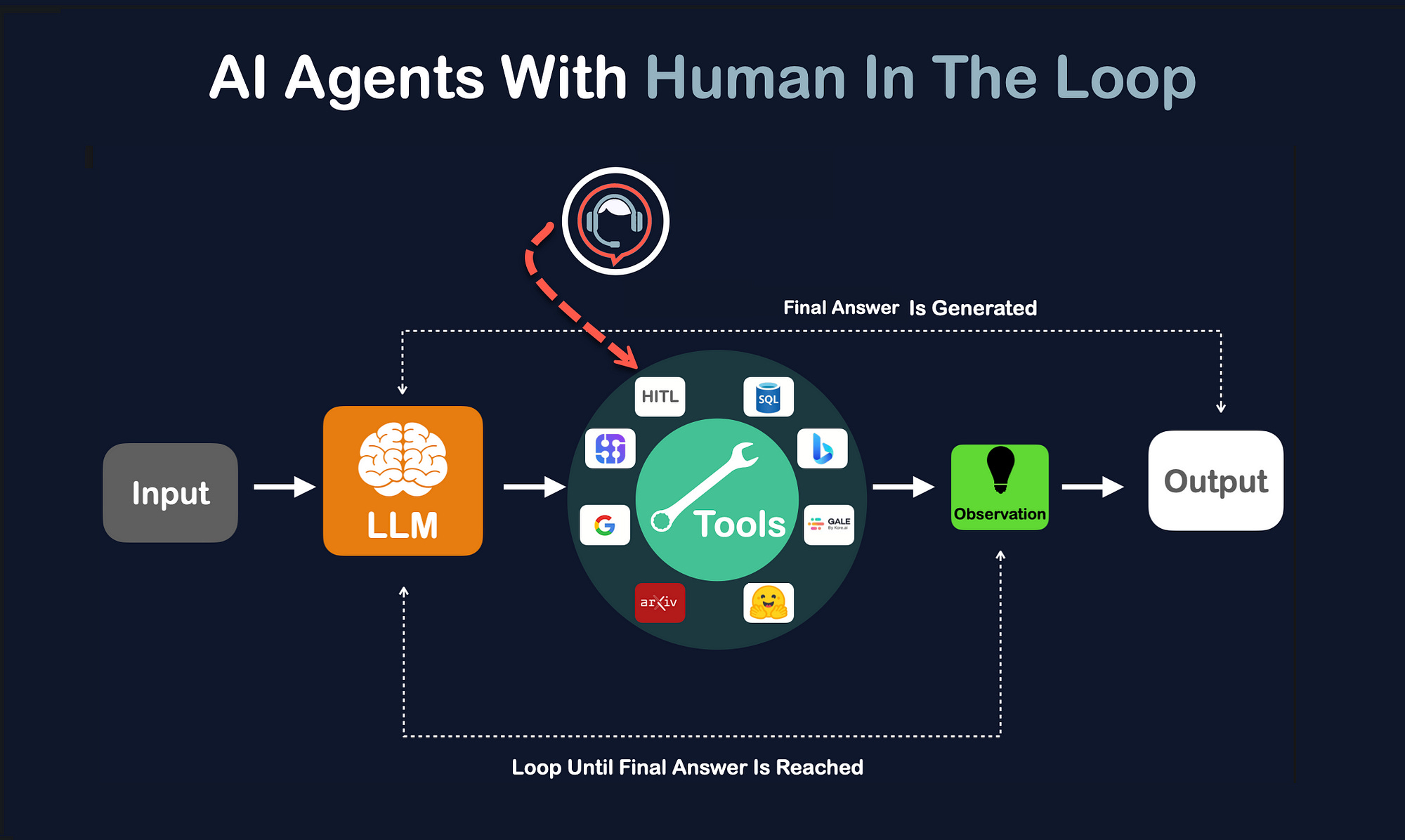
Steinberger's critique is not an isolated opinion but reflects a maturing phase in agent development. Throughout 2025, our coverage noted a shift from pure autonomy hype toward human-in-the-loop (HITL) and human-on-the-loop paradigms, especially for mission-critical tasks. This aligns with findings from research labs like Meta's FAIR, which have published on the limitations of fully autonomous agents in dynamic environments.
The mention of "human taste" is particularly salient. It moves beyond simple correctness (which agents are getting better at) to the nuanced domain of quality, style, and strategic fit—areas where AI still struggles. This is evident in fields like marketing copy, UI design, and strategic planning, where the best AI tools act as powerful co-pilots rather than autopilots.
Steinberger's position as the creator of OpenClaw gives this warning weight. It suggests that even the architects of the tools enabling greater autonomy are cautioning against its over-application. This pragmatic stance may influence how the next generation of agent frameworks is designed, potentially baking in more structured interfaces for human feedback and steering, rather than treating full autonomy as the sole end goal.
Frequently Asked Questions
What is OpenClaw?
OpenClaw is an open-source framework for building and deploying AI agents. It provides tools to chain together reasoning, access to external APIs and tools, and manage multi-step workflows, making it easier for developers to create sophisticated autonomous or semi-autonomous AI systems.
What does "human taste in the loop" mean?
It refers to the need for human judgment, aesthetic sense, and strategic oversight within an AI agent's workflow. It's not just about verifying factual correctness, but about guiding the style, creativity, and overall quality of the output to meet nuanced, often subjective, standards that AI cannot yet fully replicate on its own.
Are AI agents failing?
Not failing, but hitting practical limits. AI agents excel at well-defined, procedural tasks with clear benchmarks (like solving a coding issue from a GitHub ticket). They struggle more with open-ended, creative, or highly contextual tasks where the definition of "good" is complex and requires human experience and sensibility to evaluate and guide.
How should developers implement this advice?
Developers should architect agentic workflows with explicit checkpoints, review stages, and feedback mechanisms. Instead of aiming for an agent that completes a task start-to-finish, design it to present intermediate results, ask clarifying questions, and incorporate human feedback for key decision points, especially those involving quality and strategic direction.








