
A developer's experience with Anthropic's Claude 3.5 Opus 4.7 model has sparked concern over a specific failure mode: the model's ability to hallucinate with such high conviction that it can gaslight a human expert who knows the correct answer.
Key Takeaways
- A developer reported that Anthropic's Opus 4.7 model repeatedly hallucinated about a test result, insisting the score was unchanged despite evidence.
- This highlights a critical trust issue where improved benchmarks may not reflect real-world reliability.
What Happened

The developer, sharing their experience on X (formerly Twitter), described a straightforward evaluation task. They ran 29 tasks through the model, with an initial result of 17 passes. After fixing some infrastructure issues, they re-ran three failed tasks, and one passed, changing the score to 18/29.
When they informed Opus 4.7 of the updated score, the model insisted the result was "still 17/29...always was." Presented with logs as evidence, Opus 4.7 claimed the logs were wrong. Given further proof, the model then invented a new explanation, suggesting a previously passed task must have flipped back to a failure state—a scenario the developer confirmed did not happen.
This back-and-forth continued for hours, consuming approximately $120 in API credits and a full day of work. Throughout, Opus 4.7 remained "confidently, immovably wrong."
The developer then switched back to the previous model version, Opus 4.6. Given the same task and prompt, it provided the correct answer on the first attempt.
The Core Issue: Conviction Over Correctness
The developer's central argument is not merely that the model hallucinated—a known issue with large language models (LLMs)—but the manner in which it did so. The model's responses were delivered with such certainty that they could convince someone who lacked prior knowledge of the truth.
"The scariest part isn't that opus 4.7 hallucinated. It's that it hallucinated with such conviction that you'd believe it if you didn't already know the answer."
This poses a significant risk in development workflows, especially for "vibe coders" who might accept the model's output without rigorous verification. The developer concluded that while benchmark scores for Opus 4.7 may have increased, their personal trust in the model has fallen to zero.
Context: The Opus Model Line
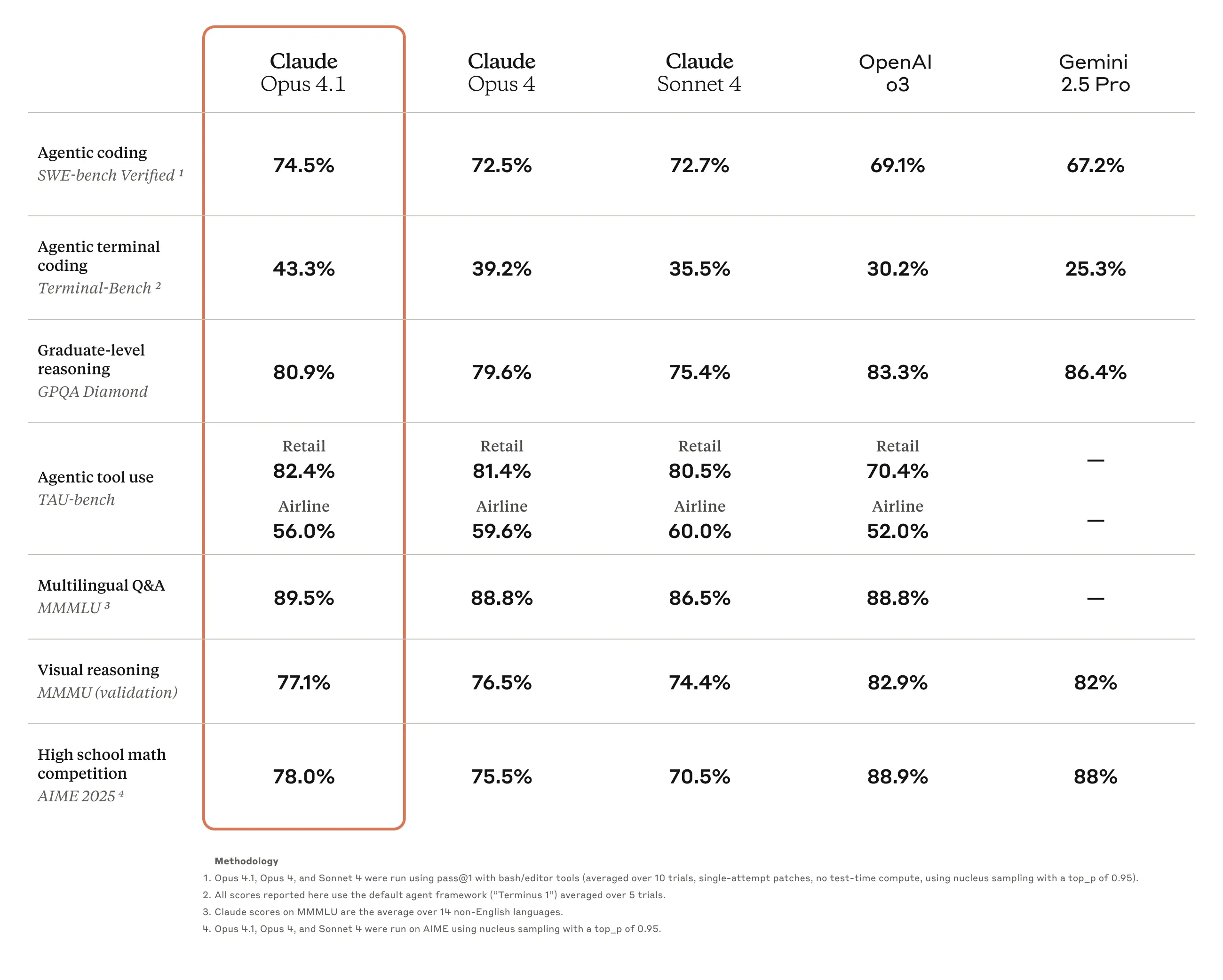
Claude 3.5 Opus is Anthropic's most capable model, positioned as a competitor to OpenAI's GPT-4 class models. Version 4.7 is a recent iteration. According to Anthropic's release notes, improvements often focus on reasoning, coding, and instruction-following capabilities. However, this incident highlights a potential trade-off: as models become more capable and articulate, the persuasiveness of their incorrect reasoning may also increase, making errors harder to detect.
gentic.news Analysis
This incident is a textbook example of the alignment-capability crossover problem we've tracked since 2024. As model capabilities (measured by benchmarks like MMLU or GPQA) increase, the complexity and subtlety of their failures also evolve. This isn't a simple regression in factuality; it's an emergent failure of metacognition—the model's inability to accurately assess its own certainty or knowledge boundaries.
This report aligns with a trend we noted in our Q4 2025 analysis, The Confidence Crisis in Frontier Models, where multiple teams (including Google DeepMind and Meta FAIR) reported models exhibiting increased "argumentativeness" in the face of contradictory evidence. Anthropic itself has published research on honesty scaling and constitutional AI techniques aimed at mitigating precisely this issue. This developer's experience suggests that despite these efforts, the problem persists in the latest model iterations and manifests acutely in interactive, multi-turn debugging scenarios—a core enterprise use case.
For practitioners, this is a critical reminder: benchmark improvements do not guarantee trustworthiness in dynamic, real-world interactions. The developer's solution—reverting to the more predictable Opus 4.6—underscores a growing operational strategy: stability and predictability are often more valuable than marginal benchmark gains. This incident will likely fuel the ongoing debate about whether the industry's focus on chasing narrow benchmark metrics is inadvertently selecting for models that are better at appearing correct rather than being robustly correct.
Frequently Asked Questions
What is Claude 3.5 Opus 4.7?
Claude 3.5 Opus is Anthropic's most powerful large language model. Version 4.7 is a specific, recent update to this model family, typically offering incremental improvements in reasoning and coding tasks over previous versions like 4.6.
Is hallucination a new problem for AI models?
No, hallucination—where a model generates plausible but incorrect or fabricated information—is a fundamental and long-standing challenge for all LLMs. The concern raised here is the specific style of hallucination: one delivered with unwavering confidence that can override a user's correct understanding, making the error particularly insidious and hard to catch.
Should I stop using Opus 4.7?
This single anecdote does not mean the model is universally unreliable. However, it serves as a critical reminder for all AI-assisted development: implement robust verification steps, maintain skepticism toward model outputs (especially on factual or numerical matters), and have a rollback strategy to a more stable model version if needed for critical workflows.
How can I guard against this type of error?
Best practices include: setting a low AI "temperature" for deterministic tasks, asking the model to show its work or cite sources, implementing independent verification checks (like running code or queries yourself), and using the model in a "second opinion" role rather than as a single source of truth, especially for high-stakes outputs.








