Key Takeaways
- A new arXiv paper introduces SID-Coord, a framework that integrates trainable Semantic IDs (SIDs) with traditional Hashed IDs (HIDs) in ranking models.
- It aims to solve the memorization-generalization trade-off, improving performance on long-tail items.
- Online A/B tests in a production short-video search system showed statistically significant improvements in engagement metrics.
What Happened
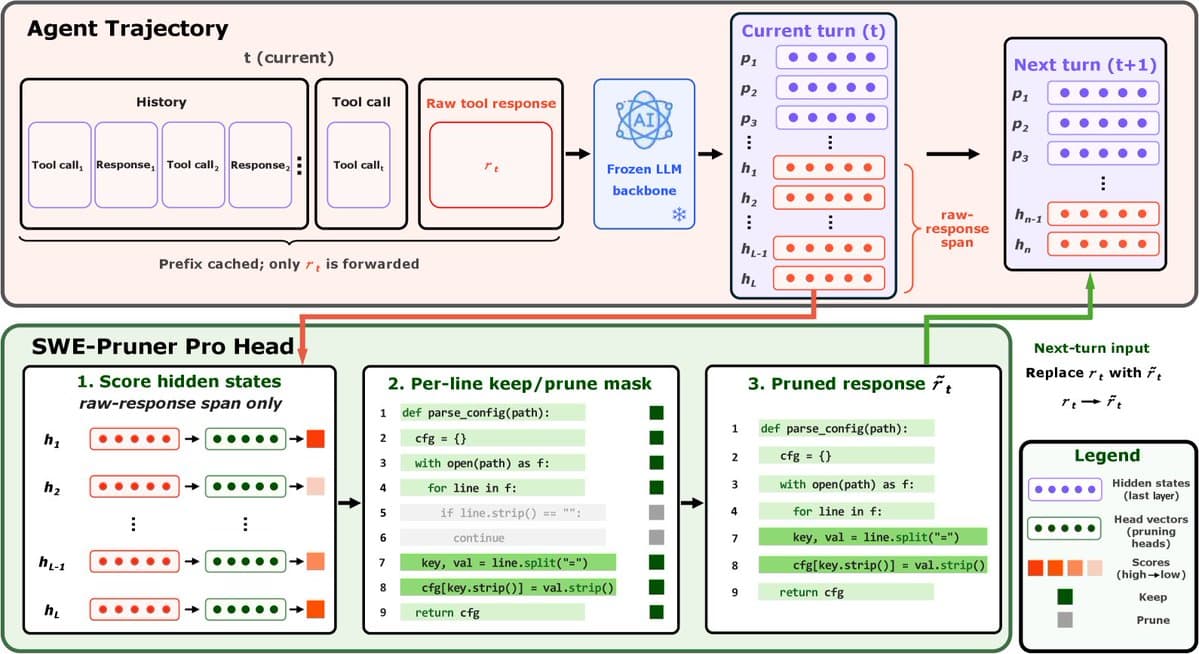
A new research paper, "SID-Coord: Coordinating Semantic IDs for ID-based Ranking in Short-Video Search," was posted to the arXiv preprint server on April 12, 2026. The work addresses a core, persistent problem in large-scale industrial recommendation and search systems: the memorization-generalization trade-off.
In such systems, ranking models are often trained using Hashed Item Identifiers (HIDs). These are unique, discrete tokens for each item (like a video or product). Models learn from sparse user interaction signals (clicks, watches, purchases) associated with these IDs. This approach excels at "memorizing" patterns for popular, frequently interacted-with items. However, it fails catastrophically for long-tail items—those with limited or zero exposure in the training data. The model cannot generalize to them because it has never seen their HID before.
The authors propose SID-Coord, a lightweight framework designed to be integrated into existing production ranking systems without modifying the core backbone model. Its central innovation is the introduction of trainable Semantic IDs (SIDs).
Technical Details
Instead of treating semantic information (like video content features or product attributes) as auxiliary dense feature vectors fed alongside the HID, SID-Coord represents semantics as structured, discrete identifiers. This creates a dual-identifier system: the HID for memorization and the SID for generalization.
The framework's power lies in how it "coordinates" these two signals through three novel components:
- Hierarchical SID Attention Fusion: Semantic IDs are structured hierarchically (e.g., broad category → subcategory → style attributes). An attention module learns to fuse information from these different semantic levels dynamically.
- Target-Aware HID-SID Gating: A gating mechanism automatically and adaptively balances the influence of the HID (memorization) and the SID (generalization) for each specific target item. For a popular item, the gate might favor the HID; for a novel long-tail item, it shifts weight to the SID.
- SID-Driven Interest Alignment: This module explicitly models the semantic similarity distribution between the target item's SID and the SIDs of items in the user's historical interaction sequence. It answers: "How semantically aligned is this new item with the user's past interests?"
The result is a model that can leverage precise memorization where data exists and intelligent generalization where it doesn't. The authors report results from online A/B experiments in a real-world, large-scale short-video search production environment. The improvements, while presented as percentage gains, are noted as statistically significant:
- +0.664% gain in long-play rate (a key engagement metric indicating users watched a significant portion of the video).
- +0.369% increase in search playback duration.
Retail & Luxury Implications
The paper's context is short-video search (e.g., TikTok, Instagram Reels), but the underlying technology is directly transferable to e-commerce search and recommendation systems. Luxury and retail face an acute form of the long-tail problem:

- New Season & Limited Editions: A new handbag collection or limited-edition sneaker drop has zero historical interaction data (HID). A pure ID-based model cannot rank it effectively. SID-Coord could rank it based on its semantic similarity (materials, designer, silhouette) to items a user has loved in the past.
- High-Value, Low-Volume Items: A rare vintage watch or a haute couture piece may sell only a few times a year. SID-based generalization could connect it to users interested in similar brands, complications, or eras.
- Personalization Beyond Purchase History: A user's history may show purchases of "business casual" attire. SID-driven interest alignment could effectively recommend a semantically similar "smart casual" blazer they haven't seen before, broadening their discovery while staying on-topic.
The framework's stated advantage of being a lightweight add-on to existing systems is crucial for retail. It suggests a potentially lower-risk, incremental path to improving core ranking infrastructure compared to a full model overhaul.
AI Analysis
For AI practitioners in retail and luxury, this paper is a significant contribution to the practical toolkit for next-generation ranking. It moves beyond the academic debate of "ID vs. feature-based models" and provides a concrete, production-tested architecture for a hybrid approach. The reported online gains, while modest in percentage terms, represent substantial business value at the scale of a major platform and validate the core premise.

The timing is notable. This follows a recent flurry of activity on arXiv focused on improving recommender systems, including a paper on the "Unreasonable Effectiveness of Data for Recommender Systems" (April 7) and our own coverage of the "DITaR" defense method for sequential recommenders (April 13). It indicates a concentrated research push to solve the next set of hard problems in industrial-scale personalization. The memorization-generalization challenge is perhaps the most business-critical of these, as it directly impacts revenue from new and niche inventory.
However, implementation is non-trivial. It requires a robust pipeline to generate meaningful, hierarchical semantic identifiers (SIDs) for all products. For luxury, this isn't just category and color; it must capture nuanced attributes like craftsmanship, heritage, and aesthetic sensibility. Building this semantic taxonomy and the models to assign SIDs is a major prerequisite investment. The promise of SID-Coord is that once this foundational layer is built, the integration into ranking can be relatively lightweight.
This research aligns with the broader industry trend of moving from purely behavioral models to hybrid semantic-behavioral understanding. It provides a specific, engineered pathway to get there, which may be more immediately actionable for retail engineering teams than waiting for a monolithic foundation model to solve the problem.