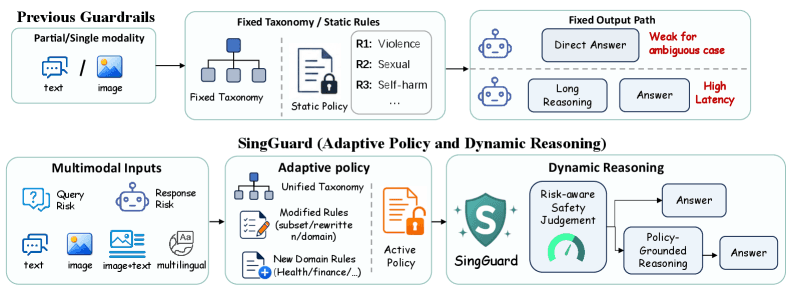
SingGuard treats safety rules as runtime inputs rather than fixed taxonomies. The system judges text, image, and cross-modal content with fast or slow reasoning, achieving state-of-the-art across 6 families and 35 datasets.
Key facts
- Treats safety rules as runtime inputs, not fixed taxonomies.
- Judges text, image, and cross-modal content.
- Uses fast or slow reasoning pathways.
- SOTA across 6 model families and 35 datasets.
Most safety guardrails for multimodal AI rely on static taxonomies: predefined categories like hate speech, violence, or NSFW imagery. SingGuard, introduced in a preprint per the arXiv paper, flips this paradigm by treating safety rules as runtime inputs. The system accepts policy definitions at inference time, allowing operators to dynamically adjust what constitutes unsafe content without retraining.
How it works
SingGuard processes text, images, and cross-modal inputs through two reasoning pathways. A fast reasoning path applies lightweight classifiers for low-latency filtering, while a slow reasoning path uses chain-of-thought evaluation for ambiguous or context-sensitive cases. The arXiv preprint (no ID provided in the source) reports that SingGuard achieves state-of-the-art performance across 6 model families and 35 datasets, though specific benchmark numbers are not disclosed in the source tweet.
Why this matters
Current guardrails like OpenAI's moderation endpoint or Anthropic's constitutional AI embed safety rules into model weights or fixed classifiers. SingGuard's approach decouples policy from model architecture, enabling deployment-specific safety rules — a hospital might block medical advice while a creative tool bans violent imagery, all from the same underlying model. The trade-off is latency: runtime policy parsing adds inference overhead, though the fast/slow reasoning split mitigates this for common cases.
Limitations
The source does not specify which 6 model families or 35 datasets were used, nor the exact performance deltas over prior methods. Without ablation studies on the fast vs. slow reasoning pathways, it's unclear how much of the gain comes from runtime policies versus the reasoning architecture itself. The paper also does not address adversarial robustness — whether policies can be bypassed by manipulating the runtime input.
What to watch
Watch for open-source release of SingGuard's code and policy specification language. If the authors publish a benchmark suite with the 35 datasets, runtime overhead numbers will determine whether enterprises adopt runtime policies over fixed classifiers.








