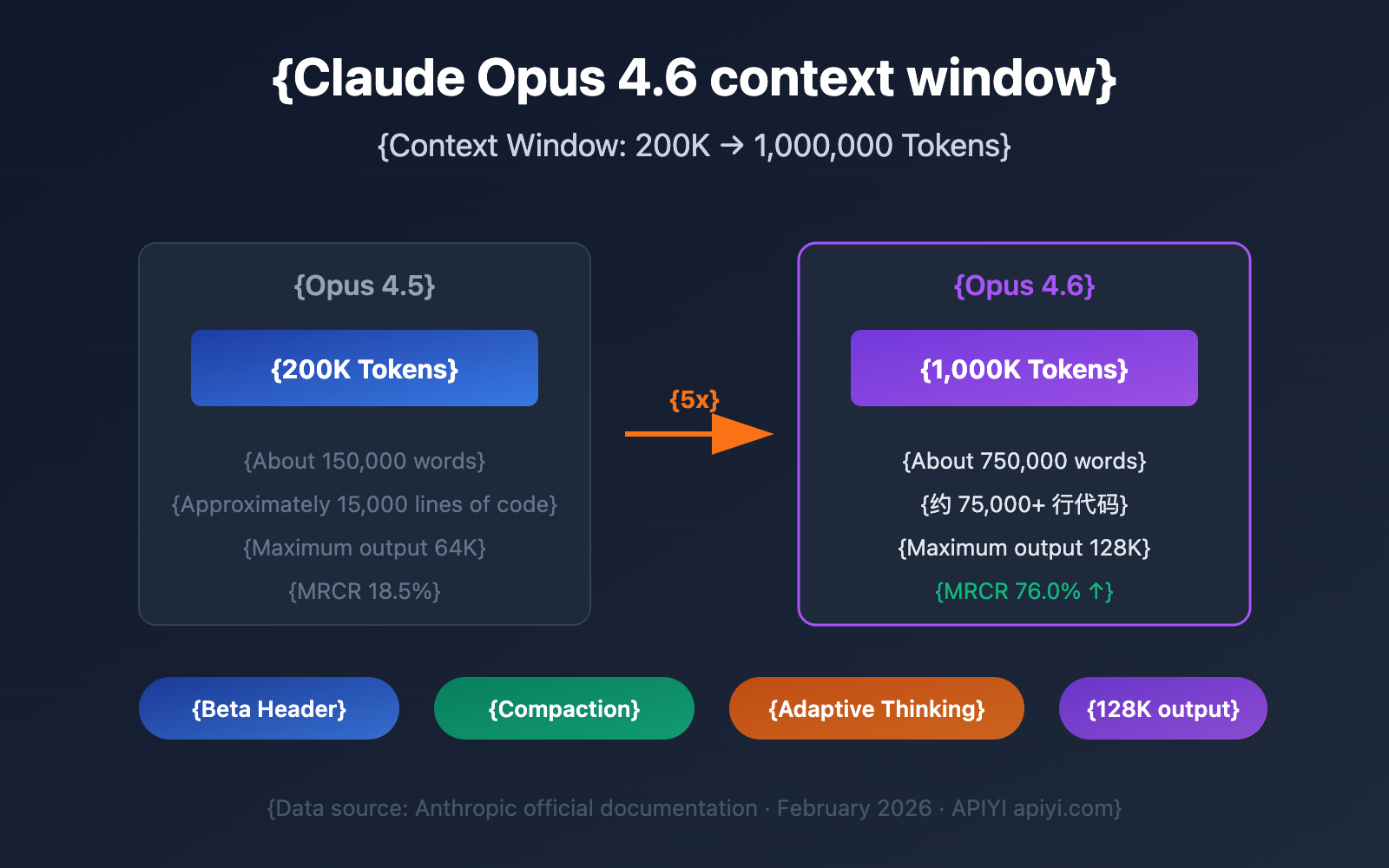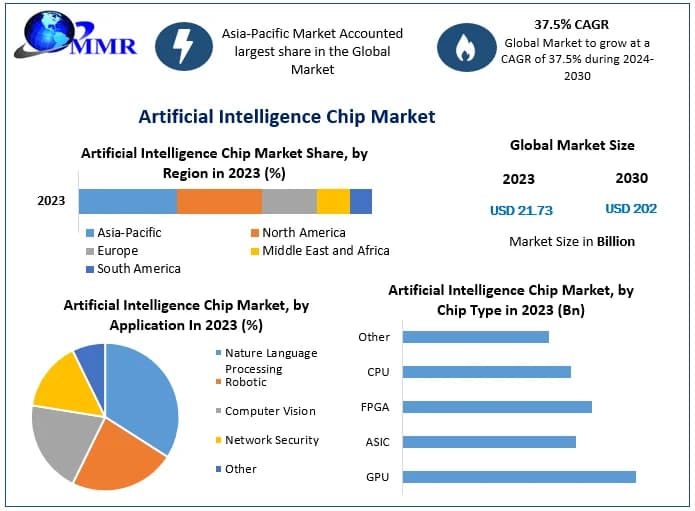
Key Takeaways
- The AI accelerator market has only 10 gigawatts of capacity left for contract through 2030, with 100GW already under contract.
- Prices are rising double digits as one competitor has stopped taking orders entirely.
What Happened

The market for AI accelerator chips—the specialized processors powering large language models and AI training—has reached a critical supply shortage. According to industry analysis from SemiAnalysis, 100 gigawatts of capacity are already under contract, leaving only 10 gigawatts of capacity available for new contracts through 2030. This extreme scarcity has triggered double-digit percentage price increases across the market.
One unnamed competitor has reportedly stopped taking new orders entirely, unable to meet demand. The market tightness is reflected in financials: one major player generated more free cash flow in the last 90 days than in the prior 365 days combined.
Context: The AI Compute Arms Race
This supply crisis emerges from the explosive demand for AI training and inference compute. Each new generation of foundation models—from GPT-4 to Claude 3 to Gemini Ultra—requires exponentially more computational power. Training runs that consumed thousands of GPUs in 2023 now require tens of thousands of specialized accelerators.
The "gigawatt" metric refers to the total power capacity allocated to chip manufacturing—a proxy for production volume. With advanced AI chips requiring cutting-edge semiconductor processes (TSMC's 3nm and below), capacity is fundamentally constrained by the number of wafer starts per month at these leading-edge nodes.
Market Implications
Immediate Impact on AI Developers
- New AI projects face 2-3 year wait times for dedicated accelerator capacity
- Cloud providers (AWS, Azure, Google Cloud) will prioritize existing commitments, making spot instances scarce and expensive
- Startups without long-term contracts may be locked out of necessary compute for model training
- Prices for reserved instances and dedicated hardware are rising 10-20%+
Strategic Consequences
This capacity crunch creates significant competitive advantages for:
- Companies with existing capacity contracts (OpenAI, Anthropic, Microsoft, Google)
- Cloud providers who secured early capacity (AWS with Trainium/Inferentia, Google with TPU)
- Alternative architecture developers who can use less advanced nodes
The Capacity Timeline

With only 10GW available through 2030:
- 2026-2027: Remaining capacity will likely be allocated to hyperscalers and largest AI labs
- 2028-2030: New fabs coming online may provide relief, but AI demand continues growing exponentially
- Beyond 2030: Next-generation fabs (TSMC Arizona, Intel Ohio) will add capacity but face 2-3 year construction timelines
gentic.news Analysis
This capacity crisis represents the physical bottleneck in the AI revolution. While algorithmic improvements continue (as covered in our analysis of Mamba-2's state space models), hardware constraints now dictate the pace of AI advancement. The 100GW under contract likely includes commitments from all major players: NVIDIA's Blackwell platform (following their record-breaking H100 sales), AMD's Instinct MI300X, and custom silicon from Google's TPU v5, AWS Trainium2, and Microsoft's Maia.
The competitor who "stopped taking orders" is almost certainly one of the smaller players—possibly Groq with their LPU or Cerebras with their wafer-scale engine—who lack the capital to secure multi-year capacity commitments at TSMC. This aligns with our previous reporting on the capital intensity of AI hardware, where only well-funded incumbents can compete.
This supply-demand imbalance creates a winner-take-most dynamic in AI development. Organizations without guaranteed compute access through 2030 face existential risk—they cannot train next-generation models. Expect increased vertical integration: AI labs acquiring chip design teams, cloud providers buying chip startups, and unprecedented investment in alternative compute paradigms (optical, neuromorphic, quantum).
The financial implications are staggering. If one player generated more cash in 90 days than the prior year, we're witnessing margin expansion of historic proportions. This will fuel even more investment in capacity, but with 4-5 year lead times for new fabs, relief won't arrive until the 2030s.
Frequently Asked Questions
What does "gigawatts under contract" mean in chip manufacturing?
In semiconductor manufacturing, "gigawatts" refers to the total power capacity allocated to fabrication facilities (fabs). Since chip production is energy-intensive and fabs operate at fixed power budgets, this metric serves as a proxy for production volume. 100GW under contract means customers have committed to purchase chips requiring that total manufacturing capacity through 2030.
Which companies are most affected by this shortage?
AI startups and research institutions without existing contracts face the greatest risk. They cannot secure the compute needed to train competitive models. Established players like OpenAI, Anthropic, Google, and Microsoft secured multi-year capacity agreements years ago. Cloud providers will allocate remaining capacity to their largest enterprise customers first.
Will this shortage delay AI progress?
Yes, but unevenly. Well-funded organizations with guaranteed capacity will continue advancing state-of-the-art. The gap between "haves" and "have-nots" will widen dramatically. We may see more efficient model architectures (like recent Mixture-of-Experts approaches) that deliver capability gains without proportional compute increases.
Are there any alternatives to TSMC's advanced nodes?
Some companies are exploring alternatives: Intel Foundry Services offers competitive nodes, Samsung has advanced packaging capabilities, and specialized architectures (like Groq's deterministic LPU) can use older nodes efficiently. However, TSMC dominates the <5nm market where leading AI chips are manufactured, making substitution difficult.
Source: SemiAnalysis via X/Twitter