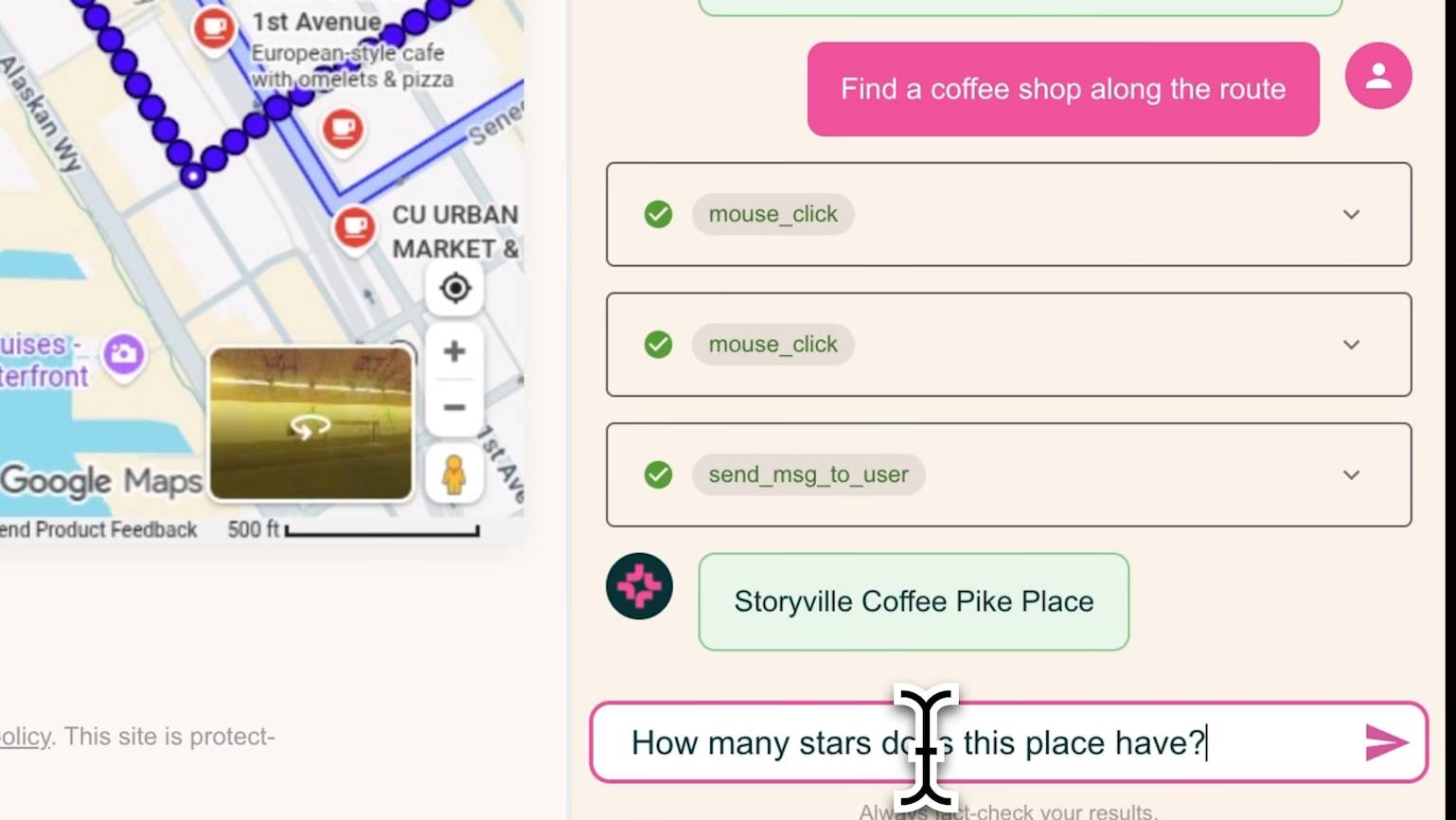
MolmoWeb operating a browser interface using only visual input. Source: AI2/The Decoder
The Allen Institute for AI (AI2) has released MolmoWeb, a fully open-source web agent that navigates websites using only screenshots, without accessing underlying page structure or source code. The release includes two model sizes (4B and 8B parameters), training data, and evaluation tools—positioning it as an open foundation for web agent development.
"Web agents today are where LLMs were before OLMo," the AI2 team states, referencing the open language model initiative. The release directly challenges the current landscape where the most capable web agents—like those from OpenAI—remain proprietary, with training data and methods undisclosed.
What the System Does
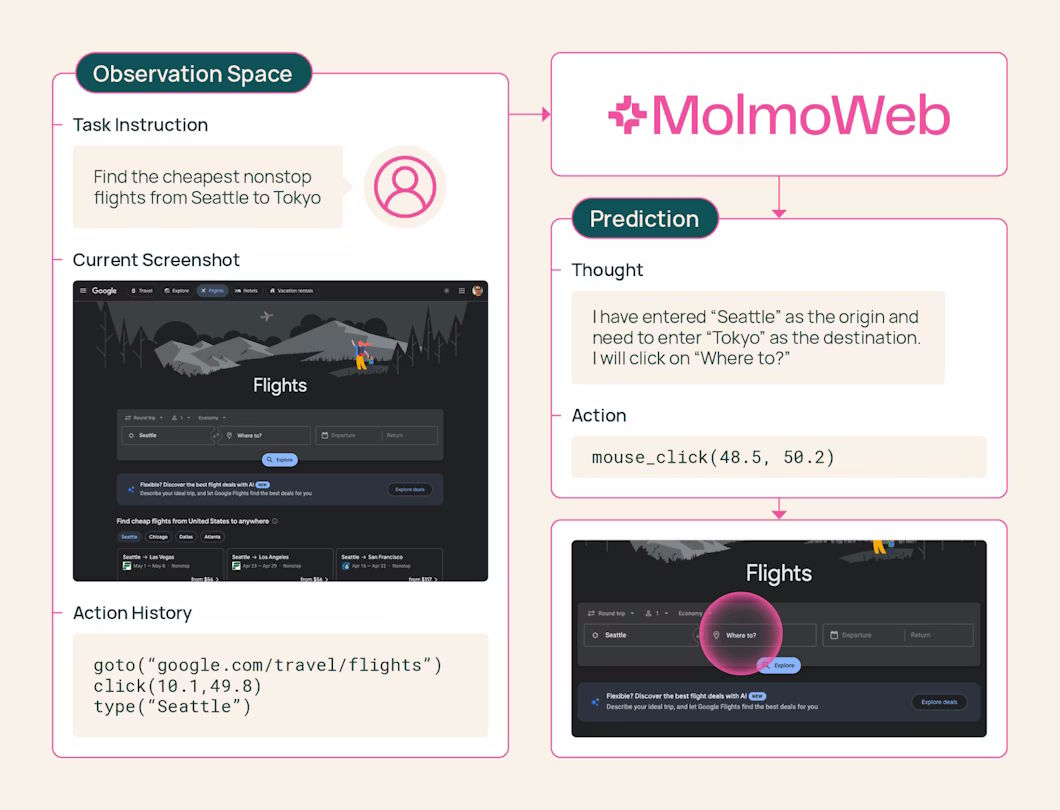
MolmoWeb operates through a simple but robust visual loop:
- Takes a screenshot of the current browser view
- Decides what action to perform (click, tap, scroll, switch tabs, go to URL)
- Executes the action
- Captures a new screenshot and repeats
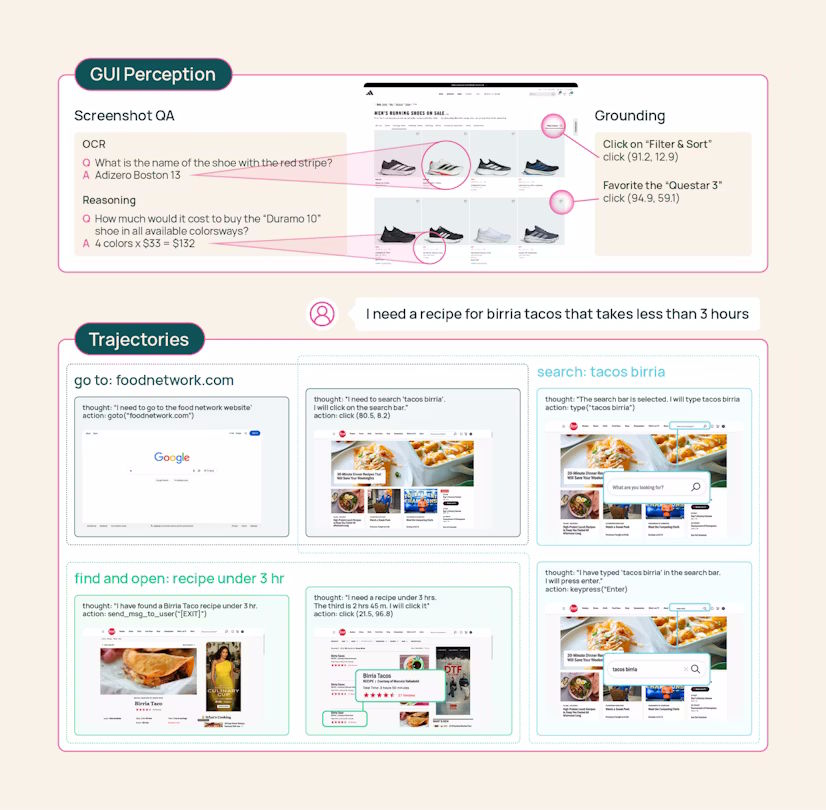
The agent works exclusively with visual information—what a human would see on screen—rather than parsing HTML, CSS, or JavaScript. This approach offers two key advantages: robustness (website appearance changes less frequently than underlying code) and interpretability (decisions map directly to what users see).
Technical Architecture and Training
MolmoWeb builds on the Molmo2 architecture with Qwen3 as the language model and SigLIP2 as the vision encoder. Training occurred on 64 H100 GPUs using supervised fine-tuning only—no reinforcement learning and no distillation from proprietary systems.
The training methodology combines:
- Human demonstrations: 36,000 complete task runs across 1,100+ websites recorded from crowdworkers
- Automated generation: A three-role system (planner, operator, verifier) using Gemini 2.5 Flash and GPT-4o to scale beyond human annotation
- Screenshot-question-answer pairs: Millions of examples for visual understanding
This combination creates MolmoWebMix, which the team describes as "the largest public dataset of human web task execution available."
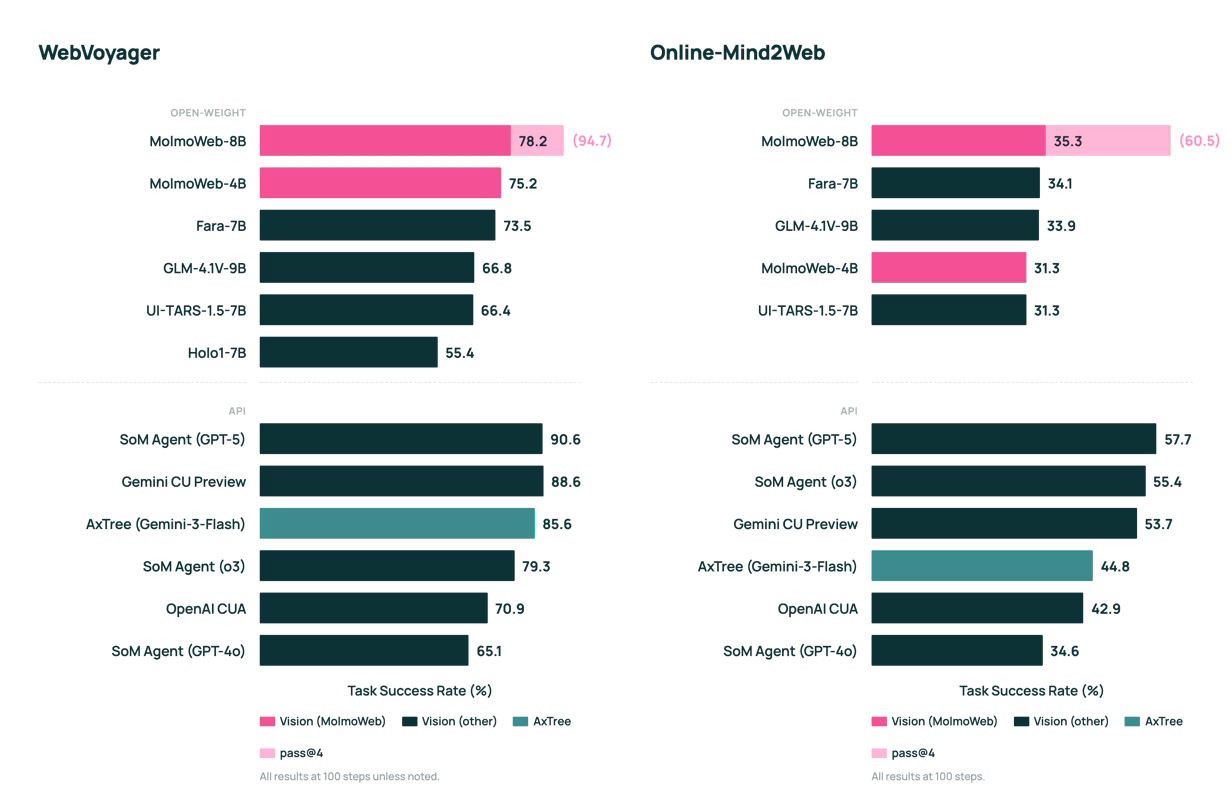
Performance and Benchmarks
Despite its compact size (8B parameters maximum), MolmoWeb reportedly:
- Outperforms the best open web agent on all tested benchmarks
- Approaches the performance of proprietary systems from OpenAI
- Demonstrates superior efficiency compared to larger models
The source doesn't provide specific benchmark numbers but emphasizes that the 8B-parameter model competes with significantly larger proprietary systems. This efficiency suggests the visual-only approach may reduce model complexity requirements.
The Open-Source Package
AI2 releases everything needed to reproduce and build upon MolmoWeb:
- Model weights for both 4B and 8B parameter versions
- MolmoWebMix dataset with human demonstrations and auto-generated runs
- Evaluation tools and benchmarks
- Training code and architecture specifications
This complete openness addresses what the team identifies as the main blocker for open web agent development: "a lack of good data."
gentic.news Analysis
MolmoWeb arrives at a pivotal moment in AI agent development. OpenAI—mentioned in 282 prior articles on gentic.news—recently signaled a strategic shift toward specialized applications, including product discovery and commerce. Just days ago, we reported on OpenAI's commercial pivot to "product discovery" and the consolidation of its video AI into ChatGPT. MolmoWeb's web navigation capabilities directly intersect with this commerce-focused future where agents browse, compare, and purchase.
The release also contrasts with the broader industry trend toward increasingly closed systems. While OpenAI expands its funding round to $120B ahead of a potential 2026 IPO, and competitors like Anthropic (which competes with OpenAI according to our entity relationships) develop proprietary agents, AI2 is betting on open foundations. This mirrors the early days of language models before open initiatives like OLMo changed the landscape.
Technically, the screenshot-only approach is noteworthy. By avoiding DOM parsing, MolmoWeb sidesteps the fragility of web scraping tools that break with minor code changes. This aligns with research into more human-like interaction patterns. However, the approach may face limitations with complex single-page applications or dynamically loaded content where visual changes don't correspond directly to actionable elements.
The timing is particularly interesting given recent benchmark revelations. Our coverage of the ARC-AGI v3 benchmark showed frontier models scoring below 1%, suggesting current approaches have fundamental limitations. MolmoWeb's specialized, visually-grounded architecture might offer a more tractable path toward practical agent capabilities than general intelligence approaches.
Frequently Asked Questions
How does MolmoWeb differ from other web automation tools?
MolmoWeb operates exclusively through visual input (screenshots) rather than parsing HTML or interacting with the DOM. This makes it more robust to website changes and more interpretable, as its decisions map directly to what users see. Traditional automation tools like Selenium or Puppeteer interact with page structure, which breaks when websites update their code.
What tasks can MolmoWeb perform?
The agent can complete common web browsing tasks including clicking buttons, filling forms, scrolling, switching tabs, and navigating to URLs. It was trained on 36,000 human task executions across 1,100+ websites covering activities like flight searches, form completion, and product browsing—essentially any task a human could complete visually.
Why is the training dataset (MolmoWebMix) significant?
High-quality, diverse training data has been the primary bottleneck for developing capable web agents. MolmoWebMix combines human demonstrations with auto-generated tasks at unprecedented scale, creating the largest public dataset of its kind. This enables reproducible research and allows the community to build upon rather than recreate foundational work.
How does MolmoWeb's performance compare to OpenAI's web agents?
While specific benchmark numbers aren't provided, the AI2 team states MolmoWeb "approaches the performance of proprietary systems from OpenAI" despite being much smaller (8B vs. likely 100B+ parameters). This suggests the visual-only approach may be more parameter-efficient for web navigation tasks than multimodal architectures that process both vision and page structure.