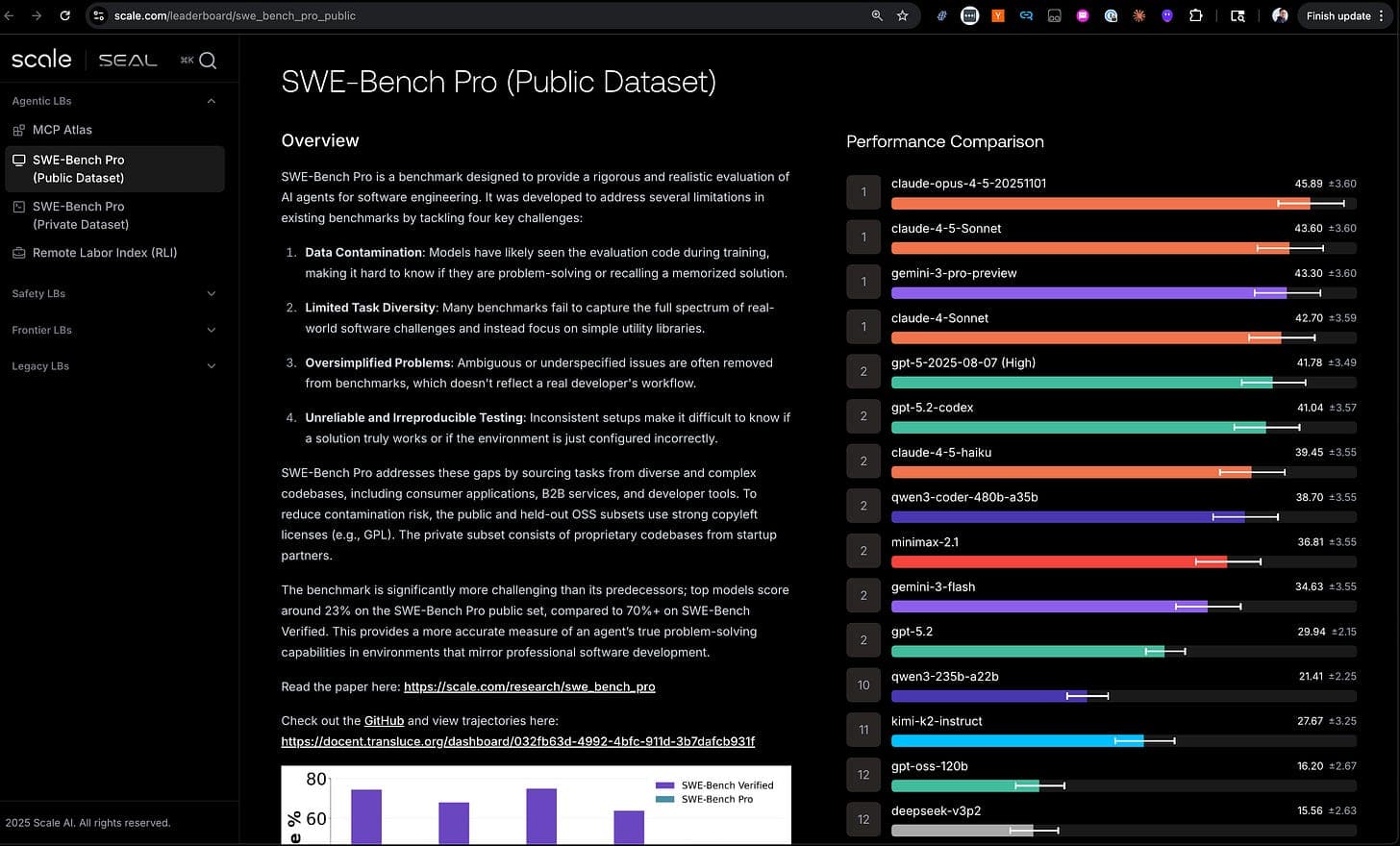
Alibaba and Nanjing University published a paper claiming a 9.36X speedup for million-token prefill compared against FlashAttention-2. The work targets the prefill phase of long-context LLM inference, where attention computation scales quadratically with sequence length.
Key facts
- 9.36X speedup claimed over FlashAttention-2
- Targets million-token prefill phase
- Alibaba DAMO Academy and Nanjing Univ collaboration
- Measured on A100 GPUs
- FlashAttention-2 baseline from 2023
The prefill phase—the initial pass where an LLM processes the entire input prompt before generating tokens—has become the dominant latency bottleneck for applications like document analysis, codebase reasoning, and retrieval-augmented generation. For a million-token prompt, standard attention requires O(N²) compute, making it impractical even on high-end hardware.
FlashAttention-2, released by Stanford and Tri Dao in 2023, already achieved up to 2X speedups over standard attention via tiling and IO-aware algorithms. FlashAttention-3 extended this to H100 GPUs with FP8 support, but prefill remains the primary latency constraint for sequences over 100K tokens.
The new method, detailed in a preprint [According to @rohanpaul_ai], claims to reduce prefill time by an order of magnitude. The paper's authors include researchers from Alibaba Group's DAMO Academy and Nanjing University's NLP lab. The 9.36X figure is measured against FlashAttention-2 on A100 GPUs for a 1M-token sequence.
Why this matters more than the press release suggests
The claim is notable not just for the raw speedup but for what it implies about the architectural direction. FlashAttention-2 and -3 are general-purpose kernels optimized for arbitrary attention patterns. A 9.36X improvement over a well-tuned baseline like FlashAttention-2 suggests the new method makes structural assumptions—likely sparsity, locality, or hierarchical compression—that trade generality for speed.
This is a pattern seen in other recent efficiency papers: DeepSeek's MLA (Multi-head Latent Attention) achieved 2-3X speedups by compressing the KV cache, and Google's Mixture-of-Depths (2024) dynamically pruned computation. The Alibaba/Nanjing approach may follow a similar vein, exploiting the observation that long-context prompts have redundant or predictable attention patterns.
If the method is validated with open-source code and reproducible benchmarks, it could make million-token inference economically viable for real-time applications. Without code release, however, the claim remains a preprint signal—impressive but unverified.
What to watch
Watch for code release and third-party reproduction on Hugging Face or GitHub. If the method uses sparsity or compression, expect follow-ups from NVIDIA or Meta applying similar ideas to their inference stacks. Also monitor whether the paper is accepted at a major venue (NeurIPS 2026 or ICML 2026).