Alibaba's Qwen team has released Qwen3.6-35B-A3B, a significant upgrade to its 35B parameter-class models. The new model is a sparse Mixture-of-Experts (MoE) architecture with 35 billion total parameters but only 3 billion active per forward pass, making it highly efficient for inference. It is natively multimodal and features distinct "thinking" and "non-thinking" reasoning modes.
Key Takeaways
- Alibaba released Qwen3.6-35B-A3B, a sparse mixture-of-experts model with 35B total but only 3B active parameters.
- It shows significant gains over its predecessor, scoring 73.4% on SWE-bench Verified and beating Claude 3.5 Sonnet on several vision tasks.
What's New
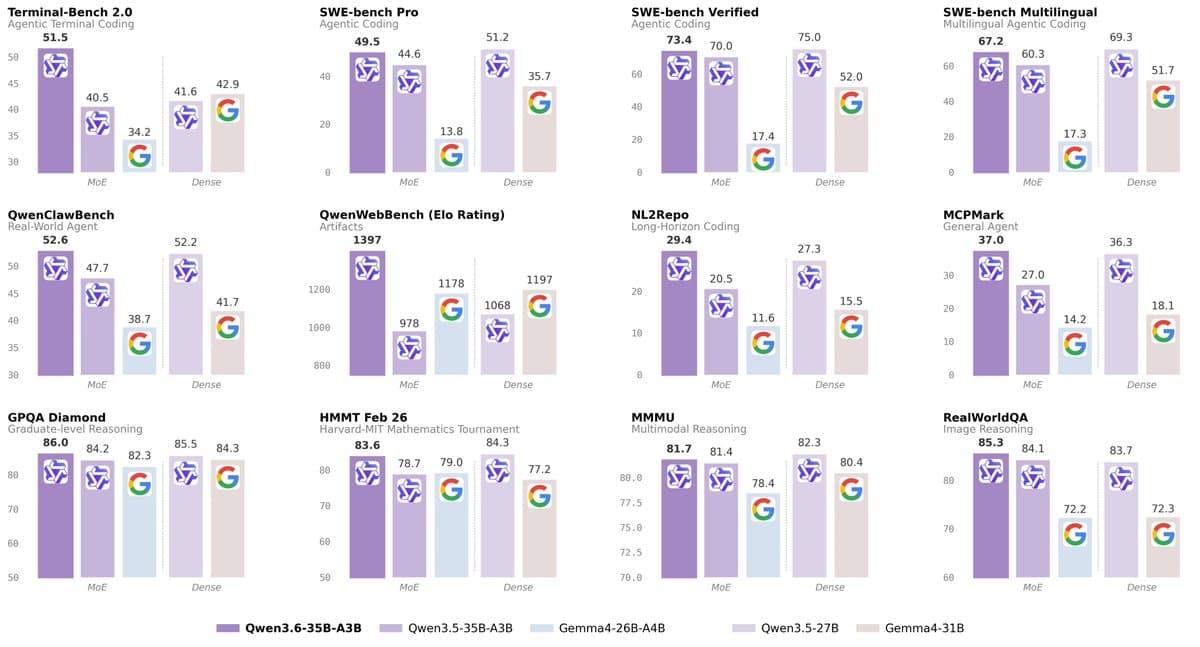
The release represents a clear performance jump over the previous Qwen3.5-35B-A3B model while maintaining the same 3-billion active parameter budget. Key improvements are documented across coding, multimodal, and STEM reasoning benchmarks.
Key Results
Benchmark comparisons show substantial gains. The following table details the leap from Qwen3.5-35B-A3B to Qwen3.6-35B-A3B on core coding tasks:
SWE-bench Verified 70.0 73.4 NL2Repo 20.5 29.4 MCPMark 27.0 37.0Notably, its SWE-bench Verified score of 73.4% is competitive with the dense Qwen3.5-27B model (75.0%) and far ahead of Google's Gemma4-31B (52.0%). It also leads the field on Terminal-Bench 2.0 with a score of 51.5 and tops the QwenWebBench Elo chart at 1397.
Multimodal & Vision Performance
A standout claim is that the model, with roughly 3B active parameters, outperforms Anthropic's much larger closed-source Claude 3.5 Sonnet on several vision benchmarks:
- MMMU: 81.7 vs. 79.6
- MMMU-Pro: 75.3 vs. 68.4
- MathVista: 86.4 vs. 79.8
- RealWorldQA: 85.3 vs. 70.3
STEM & Reasoning Prowess
The model also demonstrates strong performance on specialized STEM evaluations:
- GPQA: 86.0
- AIME26: 92.7
- HMMT Feb 26: 83.6
Technical Details & Availability

Qwen3.6-35B-A3B is a sparse MoE model. The architecture allows it to maintain a large knowledge base (35B parameters) while activating only a small, task-relevant subset (3B parameters) during inference. This design aims to provide the capability of a larger model with the latency and cost profile of a much smaller one. The model is natively multimodal, accepting both image and text inputs. The "thinking" and "non-thinking" modes likely refer to a chain-of-thought or process-supervised reasoning capability versus a standard direct answer mode. The model is expected to be available via Alibaba's ModelScope and cloud APIs.
How It Compares
The release solidifies Alibaba's position in the highly competitive mid-tier model space (20B-40B parameters). By using a sparse MoE design, Qwen is pursuing an efficiency-focused strategy distinct from the dense model approach of competitors like Meta's Llama 3.1 70B or Google's Gemma 2 27B. Its claimed performance against Claude 3.5 Sonnet on vision tasks, if independently verified, would be a notable achievement for an open-weight model of its active size.
gentic.news Analysis
This release continues Alibaba's aggressive cadence in the open-weight model arena, following the Qwen2.5 series launch in late 2025. The focus on a sparse MoE architecture with a high total-to-active parameter ratio (35B:3B) is a direct shot across the bow of other efficiency-focused models like Google's recently detailed Gemma 2 27B, which also employs MoE techniques. It reflects a broader industry trend where architectural efficiency, not just raw scale, is becoming the primary battleground for practical deployment.
The significant benchmark jumps—particularly the ~9-point gain on NL2Repo and 10-point gain on MCPMark—suggest meaningful improvements in code repository understanding and tool-use capabilities, areas critical for AI-powered developer assistants. The vision benchmark results are the most provocative claim. Beating a frontier model like Claude 3.5 Sonnet on MMMU-Pro and RealWorldQA with a ~3B active parameter model would represent a major efficiency breakthrough. However, the AI community will need to see these results replicated in independent evaluations, as benchmark details and prompting strategies can significantly influence scores.
This move pressures other open model providers (Meta, Microsoft, Mistral AI) to demonstrate similar efficiency gains in their next releases. For practitioners, Qwen3.6-35B-A3B presents a potentially compelling option for cost-sensitive multimodal applications where strong coding and vision performance are required. The "thinking mode" also indicates Alibaba is investing heavily in making reasoning processes more reliable and controllable, a key research direction for the entire field.
Frequently Asked Questions
What is a Sparse Mixture-of-Experts (MoE) model?
A Sparse MoE model consists of many specialized sub-networks ("experts"). For each input, a routing network selects only a small subset of these experts to activate. This allows the model to have a very large total number of parameters (for knowledge capacity) while keeping the computational cost per inference low, as only a fraction of parameters are used.
How does Qwen3.6-35B-A3B compare to ChatGPT or Claude?
Qwen3.6-35B-A3B is an open-weight model with a specific efficiency focus (3B active parameters). While it claims to beat Claude 3.5 Sonnet on certain vision benchmarks, overall capability and breadth, especially in conversational tasks, may differ. Its key advantage is transparency and the potential for lower-cost, self-hosted deployment compared to closed API models.
What are "thinking" and "non-thinking" modes?
These modes likely refer to different inference-time behaviors. A "thinking mode" probably engages the model in explicit chain-of-thought or process-supervised reasoning, showing its intermediate steps to arrive at a more accurate final answer. "Non-thinking mode" would produce a direct, faster response without displaying intermediate reasoning, suitable for less complex queries.
Where can I download or use Qwen3.6-35B-A3B?
The model is expected to be released on Alibaba's ModelScope platform and made available via their cloud AI services (DashScope). Developers can typically access it through these portals for download or via an API.