Oracle founder Larry Ellison has ignited a crucial conversation about the future of artificial intelligence competition. In recent remarks, the tech billionaire argued that as AI models trained on the same public data converge and become commoditized, the true competitive advantage shifts to companies with exclusive proprietary datasets. This perspective challenges the current obsession with model architecture and parameter counts, suggesting we're entering a new phase of AI development where data exclusivity becomes the primary differentiator.
The Convergence Hypothesis
Ellison's argument rests on what might be called the "convergence hypothesis" - the idea that as leading AI companies train their models on essentially the same publicly available internet data, their capabilities will naturally converge toward similar performance levels. This phenomenon is already observable in benchmark comparisons where top models from different companies show remarkably similar capabilities across many tasks.
This convergence creates what economists call a "commoditization" problem. When products become functionally identical, competition shifts from features to price, and profit margins collapse. In the AI context, this could mean that foundation models become utilities - powerful but undifferentiated tools that anyone can access at low cost.
The Proprietary Data Advantage
Ellison's solution to this commoditization threat is proprietary data. Companies that control unique, high-quality datasets that aren't available to competitors could train models with specialized capabilities that can't be easily replicated. This could include everything from proprietary scientific research and financial transaction data to unique customer behavior patterns and specialized industry knowledge.
Oracle itself exemplifies this strategy through its vast enterprise software ecosystem. The company's databases, enterprise resource planning systems, and customer relationship management platforms generate terabytes of unique business data that competitors cannot access. This positions Oracle to potentially create AI systems with unparalleled understanding of business operations, supply chains, and organizational dynamics.
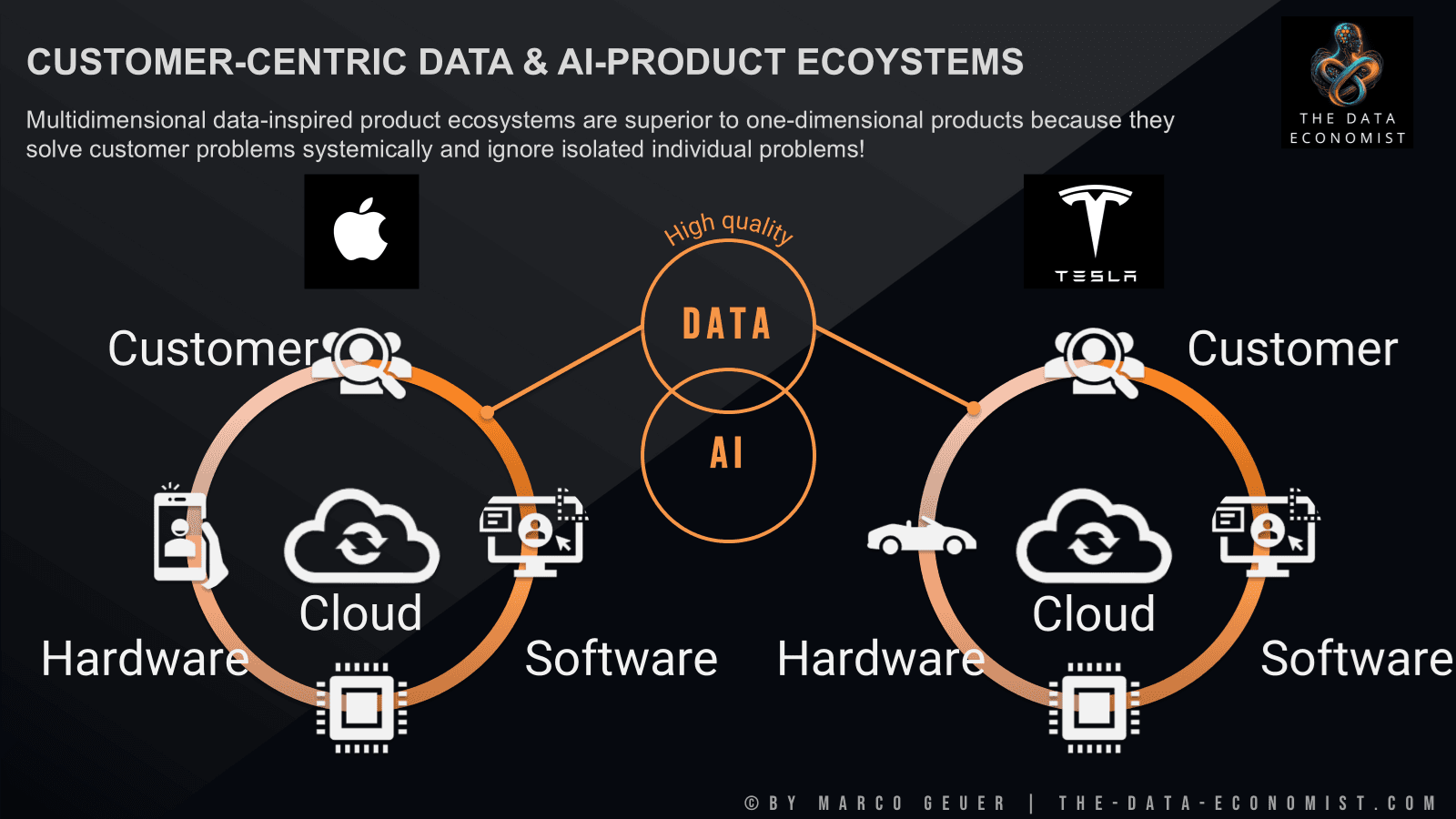
Beyond Data: The Ecosystem Moats
While Ellison focuses on proprietary data, industry analysts suggest the competitive advantage may be even more complex. As noted in responses to Ellison's argument, the strongest moat isn't merely proprietary data, but rather proprietary feedback loops, distribution channels, and environments that generate reinforcement learning signals and keep AI systems continuously improving.
This perspective suggests that data alone isn't enough - what matters is creating systems where AI can learn from real-world interactions in ways that competitors cannot replicate. Companies like Google, with its search ecosystem; Amazon, with its e-commerce platform; and Apple, with its device ecosystem, create these virtuous cycles where their products generate unique data, which improves their AI, which makes their products more valuable, which generates more data.
The User Experience Convergence
Perhaps the most provocative insight emerging from this discussion is that for 95% of users, it makes absolutely no difference which large language model they use. Most people interacting with AI through chatbots, writing assistants, or search enhancements don't notice or care about the subtle differences between models that score slightly higher on academic benchmarks.
This user experience convergence reinforces the commoditization argument. When users can't tell the difference between products, competition shifts to distribution, integration, and ecosystem advantages rather than raw capability differences.
Implications for the AI Industry
Ellison's perspective has significant implications for how we think about AI investment and strategy:
Enterprise AI Advantage: Companies with deep industry-specific data may have more sustainable advantages than pure AI research firms
Vertical Integration: The most defensible AI positions may belong to companies that control both the data generation and the user interface
Open Source Dynamics: The convergence hypothesis suggests open source models might catch up to proprietary ones more quickly than expected
Regulatory Considerations: Data exclusivity could raise antitrust concerns if it creates insurmountable barriers to competition
The Future of AI Competition
Looking forward, we're likely to see several developments:
- Specialized AI Ecosystems: Companies will compete less on general intelligence and more on specialized capabilities within particular domains
- Data Partnership Networks: Strategic alliances around data sharing may become more valuable than technology licensing agreements
- Privacy-Preserving AI: Techniques like federated learning that allow model training without centralizing data could become crucial competitive tools
- Synthetic Data Generation: Companies without proprietary data may invest heavily in creating high-quality synthetic training data
Conclusion
Larry Ellison has identified a critical inflection point in AI development. As models converge in capability, the competition shifts from who has the best algorithms to who controls the most valuable learning environments. This doesn't diminish the importance of technical innovation, but rather recontextualizes it within broader business ecosystems.
The most successful AI companies of the next decade may not be those with the largest models, but those with the most valuable feedback loops - systems where every user interaction makes their AI slightly better in ways competitors cannot replicate. This suggests a future where AI advantage comes not from hoarding data, but from creating valuable experiences that generate unique learning opportunities.
Source: Analysis based on Larry Ellison's remarks as discussed by @kimmonismus on X/Twitter