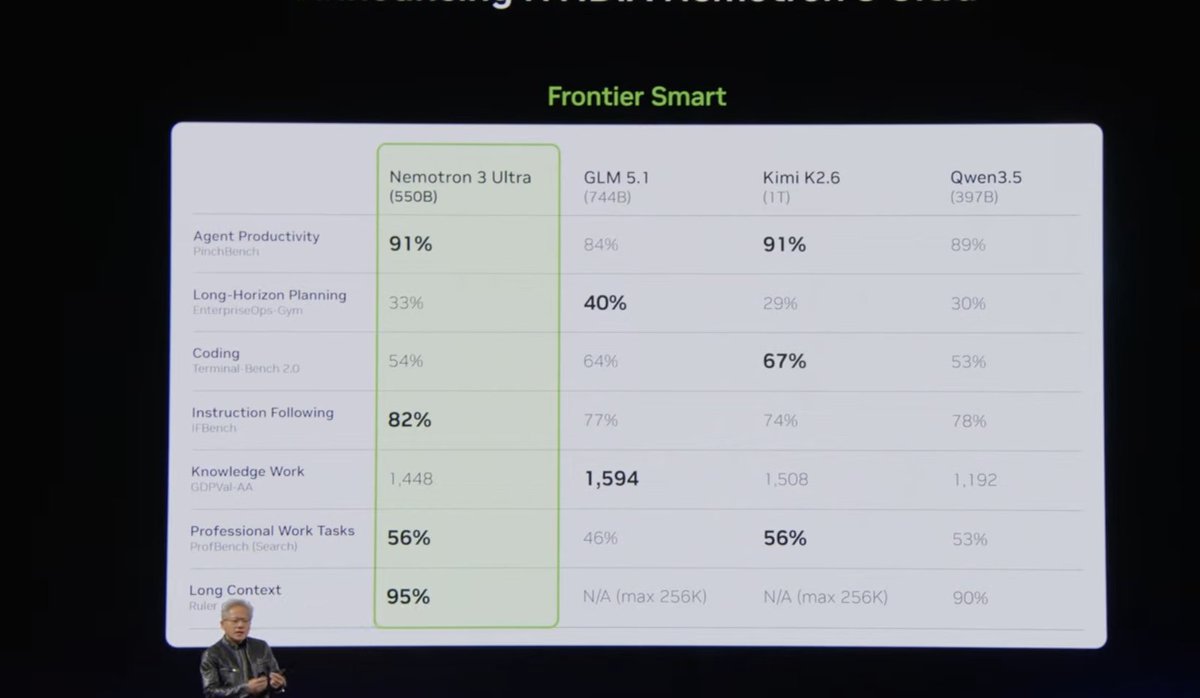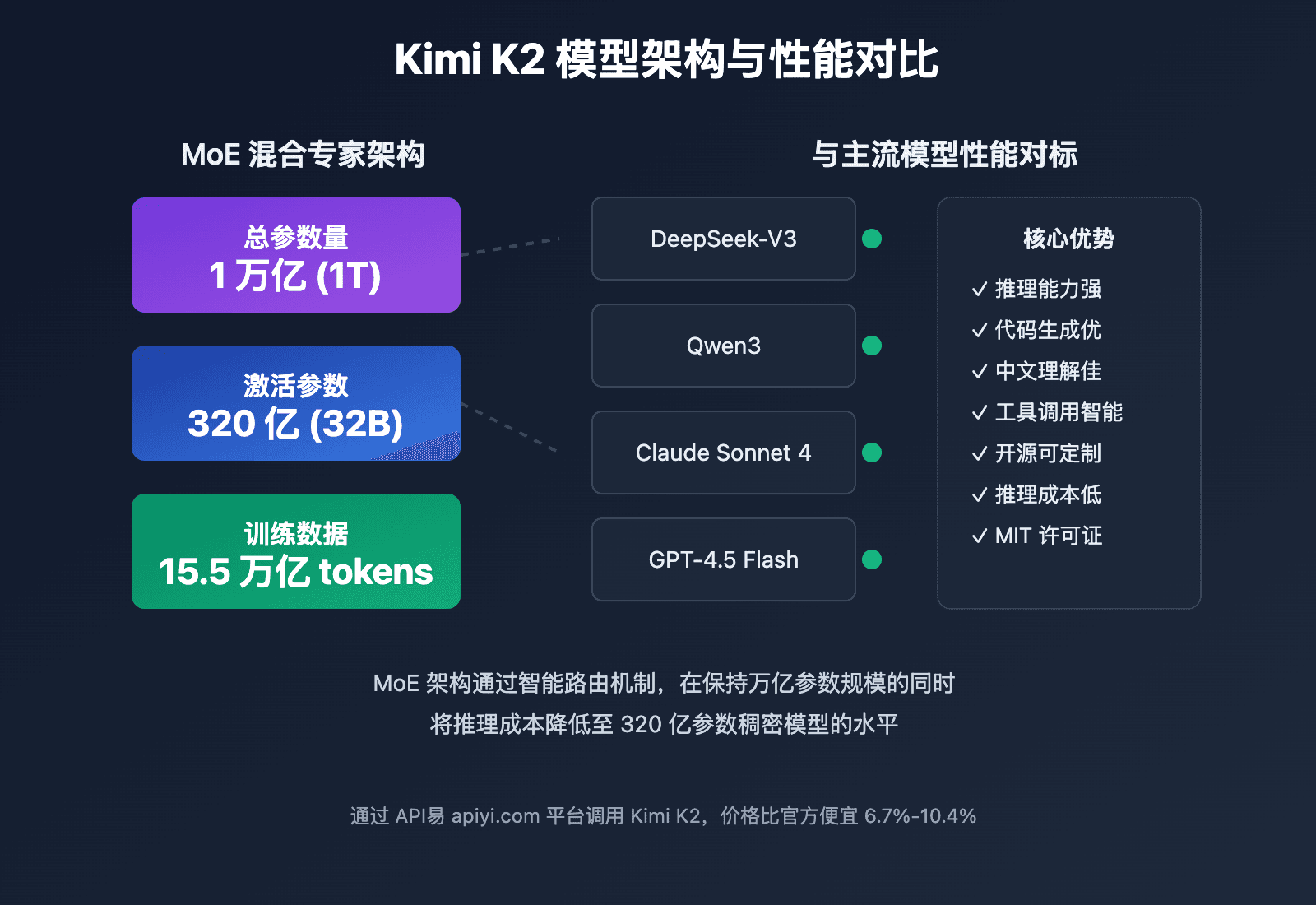
Cerebras reported 981 tokens/sec on the 1T-parameter Kimi K2.6 model. The result claims a 6.7× speedup over the next GPU cloud, validated by an independent third party [According to @rohanpaul_ai].
Key facts
- 981 tokens/sec on 1T-parameter Kimi K2.6
- 6.7× faster than the next GPU cloud
- Validated by independent third party
- Model developed by Moonshot AI
- Cerebras CS-3 wafer-scale chip used
Cerebras Systems published a benchmark result claiming 981 tokens per second on the 1-trillion-parameter Kimi K2.6 model, developed by Moonshot AI. The company asserts this is 6.7× faster than the next GPU cloud, with the performance validated by an independent third party.
The unique angle here is not just the raw speed—Cerebras's wafer-scale architecture eliminates the memory bandwidth bottleneck that plagues multi-GPU inference for large models. While GPU clouds must split a 1T-parameter model across dozens of interconnected GPUs, incurring communication overhead, Cerebras's CS-3 system can hold the full model on a single wafer-scale chip. This structural advantage explains the magnitude of the speedup, which is consistent with prior Cerebras claims on GPT-3-class models.
Cerebras has not disclosed the specific GPU cloud used for comparison, nor the exact model configuration (e.g., batch size, precision). The Kimi K2.6 model itself is a MoE architecture, which may favor Cerebras's deterministic compute fabric over GPU tensor cores. Independent replication would be needed to confirm the claim, but the 6.7× figure aligns with the theoretical memory-bandwidth advantage of wafer-scale integration.
The Structural Advantage

Cerebras's CS-3 system integrates 850,000 cores on a single 7nm wafer, with 44 GB of on-chip SRAM and 20 PB/s memory bandwidth. For a 1T-parameter model, a GPU cluster must use high-bandwidth memory (HBM) with ~2 TB/s per GPU, but inter-GPU communication via NVLink or InfiniBand introduces latency. Cerebras's on-chip memory eliminates this bottleneck, enabling near-linear scaling for inference.
The 981 tokens/sec figure is particularly notable for production use cases: at that rate, a single Cerebras system could serve real-time chat applications with sub-second latency for prompts of several hundred tokens. For comparison, a typical GPU-based deployment for a 1T-parameter MoE model might achieve 100-200 tokens/sec per node.
Caveats and Context
The benchmark was validated by an independent third party, but Cerebras has not named the validator or released the full methodology. The comparison GPU cloud is also unnamed, making it difficult to assess fairness. Prior Cerebras benchmarks on smaller models (e.g., GPT-3 175B) showed 2-3× speedups over NVIDIA H100 clusters, so the 6.7× figure for a 1T-parameter model suggests the advantage grows with model size—consistent with the communication overhead thesis.
The Kimi K2.6 model is a mixture-of-experts architecture, which may benefit from Cerebras's deterministic scheduling. MoE models require careful load balancing across experts, and Cerebras's fine-grained compute fabric can allocate compute precisely to active experts, avoiding the idle-GPU problem in GPU clusters.
What to Watch
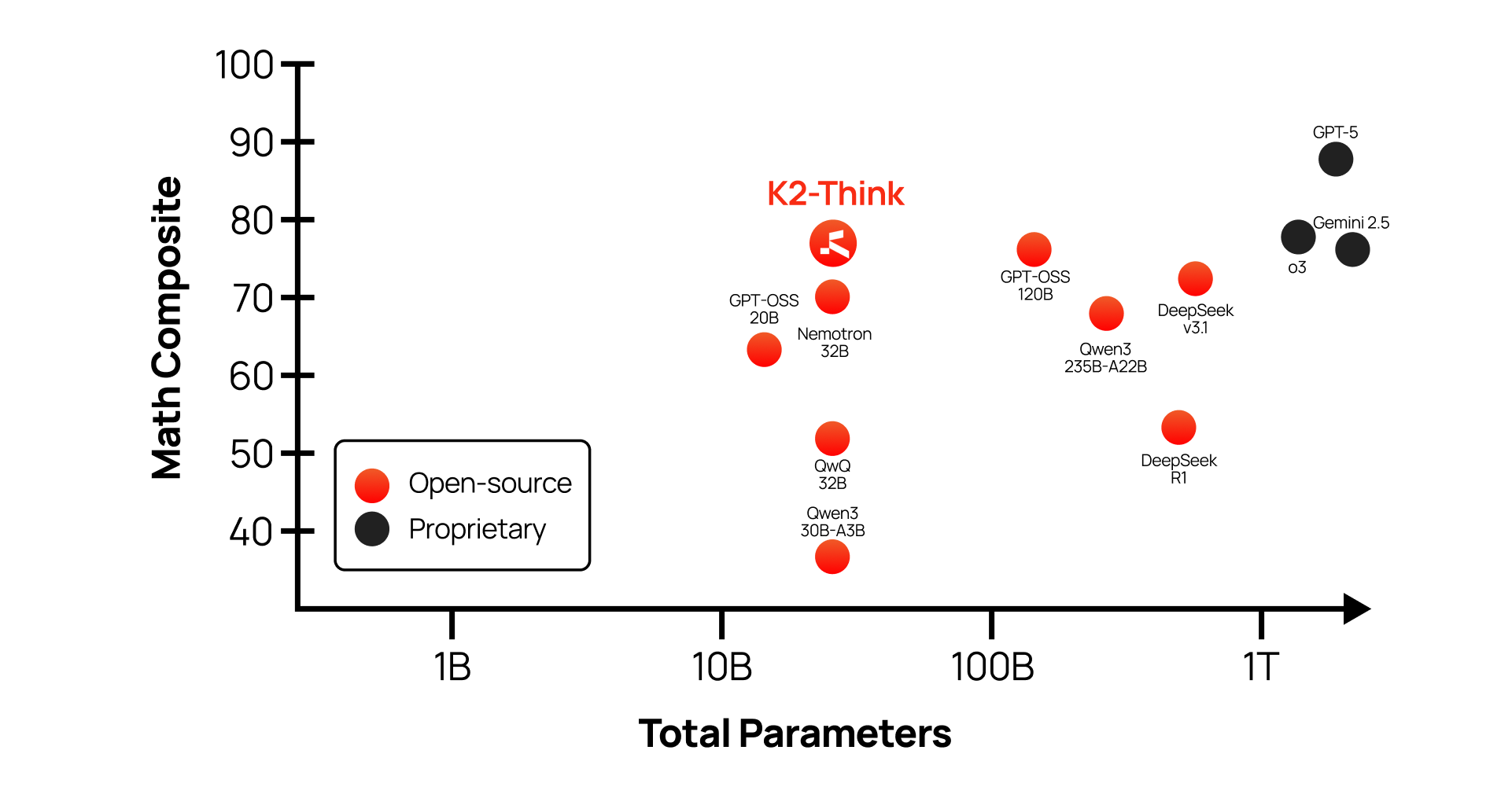
The key test will be whether Cerebras can maintain this speedup on dense models (non-MoE) and at varying batch sizes. Watch for Cerebras to publish a follow-up benchmark on a dense 1T-parameter model like Meta's LLaMA-3.1 405B or a similar dense model, ideally with a named GPU comparison (e.g., H100 or B200 clusters). Also watch for Moonshot AI to confirm production deployment of Kimi K2.6 on Cerebras hardware, which would validate the real-world viability of wafer-scale inference for frontier models.
What to watch
Watch for Cerebras to release a follow-up benchmark on a dense 1T-parameter model (e.g., LLaMA-3.1 405B) with a named GPU comparison, and for Moonshot AI to confirm production deployment of Kimi K2.6 on Cerebras hardware. Independent replication by MLPerf Inference would be the strongest validation.