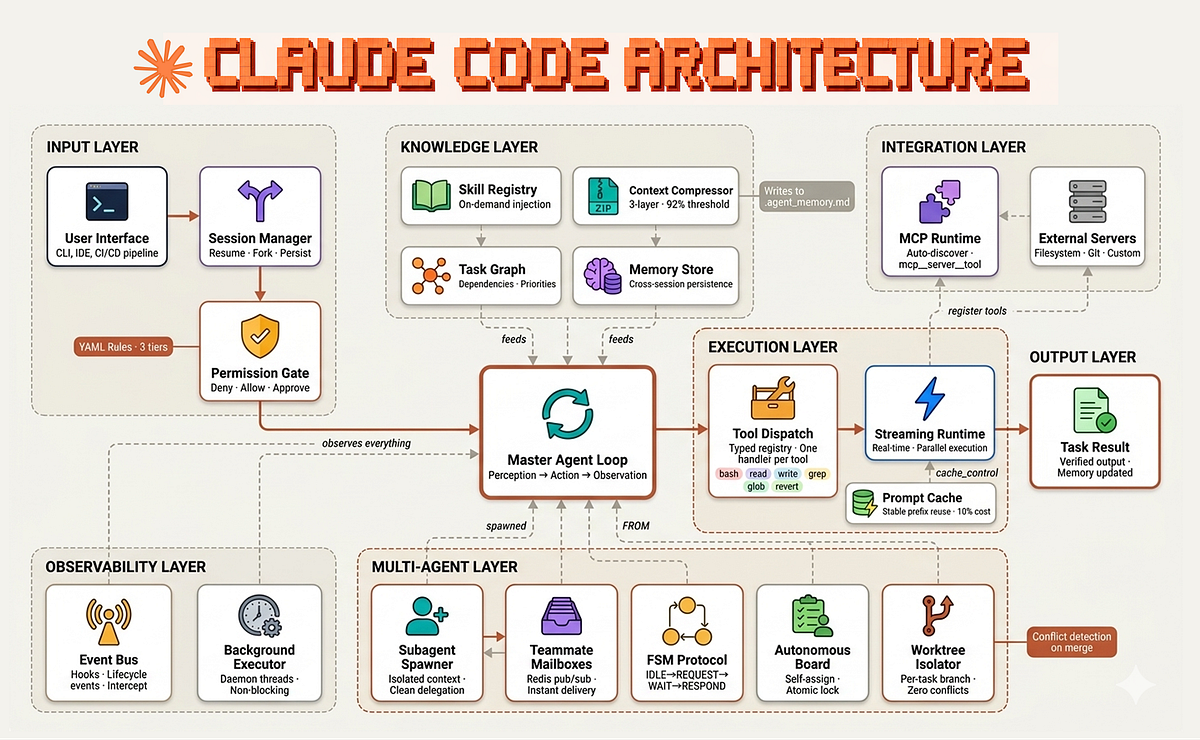
Team-of-agents, a Claude Code plugin, deploys 17 specialist AI agents with an orchestrator. The orchestrator plans tasks, dispatches subagents, and assembles outputs with confidence signals [Show HN].
Key facts
- 17 specialist agents: backend, frontend, data, UX, SRE, etc.
- Orchestrator shows plan for user approval before dispatching.
- Confidence signals: High, Medium, Low, Blocked.
- Independent tasks run in parallel; dependent ones sequential.
- Optional senior-engineer review step checks for errors.
The open-source plugin, published on GitHub by developer pranav8494, turns Claude Code into a multi-role software development lifecycle (SDLC) team. It includes agents for backend, frontend, data, UX, SRE, and other domains — each a distinct expert role.
How the orchestrator works
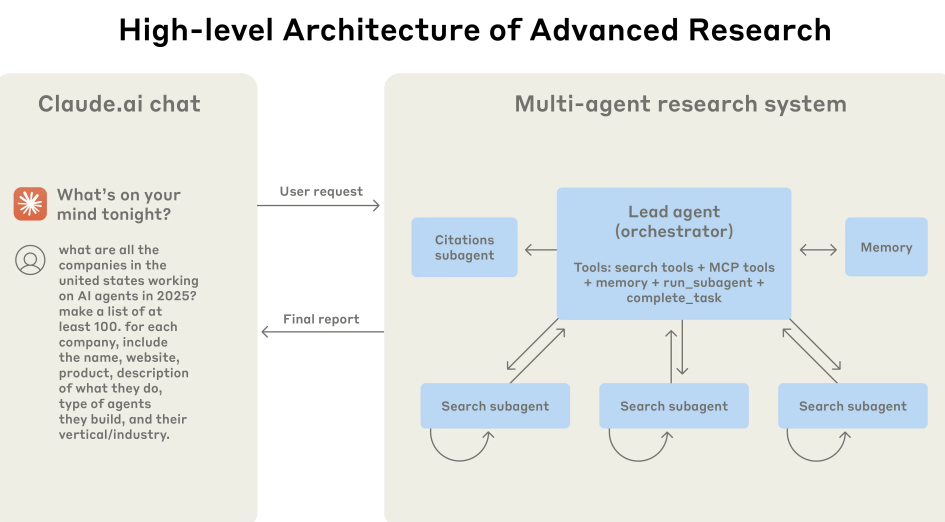
The orchestrator reads a plain-English request, identifies required domains and dependencies, and shows a plan for user approval. Independent subtasks run in parallel; dependent ones run sequentially. Each specialist returns output plus a confidence signal (High / Medium / Low). High-confidence outputs go directly to assembly; Medium signals flag assumptions for user confirmation; Low signals surface gaps and trigger re-dispatch with more context. A blocked status asks the user what's missing before retrying.
A senior-engineer review step optionally checks all outputs for errors or conflicts before final assembly. The orchestrator produces a full trace log of every agent's work.
The unique take: confidence gating replaces brittle prompt engineering
Most multi-agent frameworks assume subagents always produce correct output. Team-of-agents instead gates on confidence — a simple but effective reliability mechanism. Medium or Low confidence triggers human intervention or re-dispatch, preventing cascading errors. This mirrors patterns from Anthropic's own Claude Agent framework [per knowledge graph data], which also uses structured delegation.
Practical examples
A sample workflow: "My checkout conversion is dropping — help me figure out why and fix it" triggers parallel runs of UX research, data analysis, and frontend review agents. Their findings feed into backend and frontend specialists, then a senior-engineer review, producing one coherent plan.
The plugin installs via /plugin marketplace add pranav8494/team-of-agents or /plugin install team-of-agents@team-of-agents. It works with Claude Code, which Anthropic launched in May 2026 as a terminal-based coding tool [knowledge graph]. Claude Code competes with Cursor and GitHub Copilot.
Limitations
The plugin is a Show HN project with 1 point and 0 comments at publication — no independent verification of reliability. The 17 specialists' actual benchmark performance is undisclosed. The confidence signal's accuracy depends on the underlying model; Claude Opus 4.6 [knowledge graph] scores 80.1 on HumanEval but that doesn't guarantee correct confidence calibration.
What to watch
Watch for independent benchmarks comparing Team-of-agents against vanilla Claude Code on SWE-Bench or similar coding benchmarks. Also watch for Anthropic's official response — they may build confidence gating into Claude Agent natively.