Claude Code quality dropped significantly after version 4.6, with users reporting ~25% of instructions missed and code review failures, per a Hacker News post. OpenAI's Codex is praised for 95% reliability but less creativity.
Key facts
- ~25% of instructions missed in Claude Code post-4.6.
- Codex 5.3 reported 95% reliability by the same user.
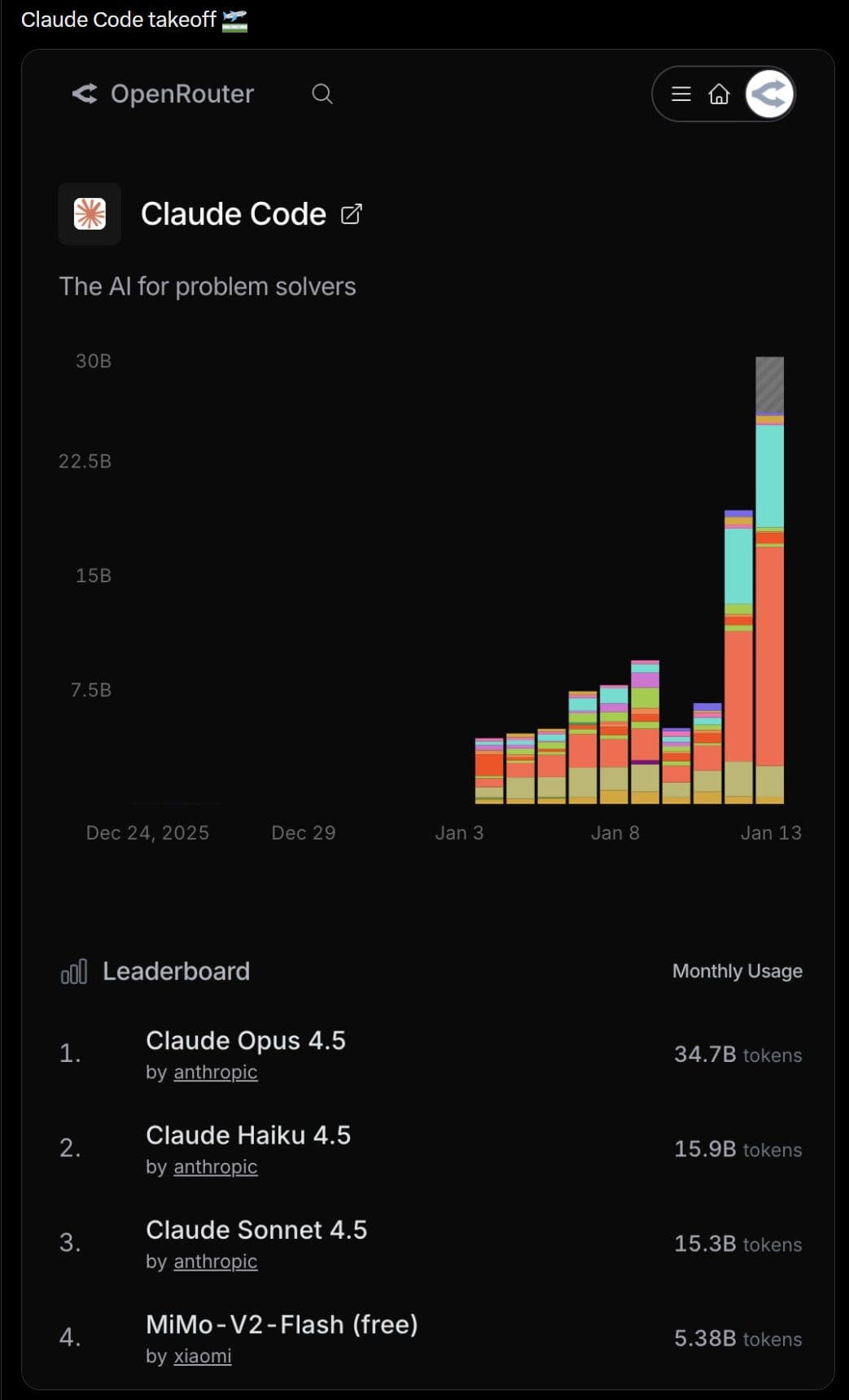
- Claude Code usage limits doubled after 80x growth.
- OpenAI merged Codex into ChatGPT on June 2, 2026.
A long-time Claude Code user posted on Hacker News that the tool's performance has "immensely worse" since the 4.7 and 4.8 releases. The user, who claims to identify model switches by output style alone, reports two key failures: the agent consistently misses close to a quarter of the ask, which cascades into bloat over time, and it literally fails to read existing code or use tools properly during review.
The user tried OpenAI's Codex as an alternative, finding it "remarkably precise about the exact changes I need, reliable nearly 95% of the time." However, Codex lacks Claude's "flair" and creative presentation, such as ascii block diagrams and idea generation. The user now splits workflows: Claude for brainstorming, Codex for execution.
The reliability-creativity tradeoff
This complaint aligns with a broader pattern in coding agents: the tension between precision and exploration. Claude Code, built on Claude Opus 4.6 and later models, prioritizes conversational breadth and tool use (e.g., MCP, Playwright). Codex 5.3, per OpenAI's documentation, is optimized for deterministic code generation. The user's experience suggests that as Anthropic pushed for more features and creative outputs post-4.6, reliability suffered — a tradeoff that may be inherent to the model's architecture or the agent's tool-use loop.
Community sentiment and historical context
The HN post has only 5 points and 0 comments as of writing, indicating this is an early signal, not a consensus. However, it echoes our earlier reporting on Claude Code usage limits doubling after 80x growth, suggesting rapid adoption may have strained quality. The user's advice — "Don't trust Claude when it says it finished something" — mirrors a common developer mantra: always review AI-generated code.
Notably, the user pins the regression to the 4.7 and 4.8 releases, not the underlying model. Claude Code is a product layer atop Claude Opus 4.6 (and later models), so the issue may be in the agent's instruction-following or tool-use logic, not the LLM itself. Anthropic has not publicly acknowledged the problem.
What Codex's rise means
This anecdote arrives as OpenAI merges Codex into ChatGPT, discontinuing the standalone API. If Codex becomes the default coding agent inside ChatGPT, its reliability advantage could attract users frustrated with Claude Code's post-4.6 drift. Conversely, Anthropic may need to tighten Claude Code's instruction adherence to retain its base.
What to watch
Watch for Anthropic's response to this quality regression and whether Claude Code 4.9 or a model update addresses instruction-following. Also track Codex adoption inside ChatGPT post-merger, which could accelerate if Claude Code reliability doesn't improve.
Source: news.ycombinator.com