
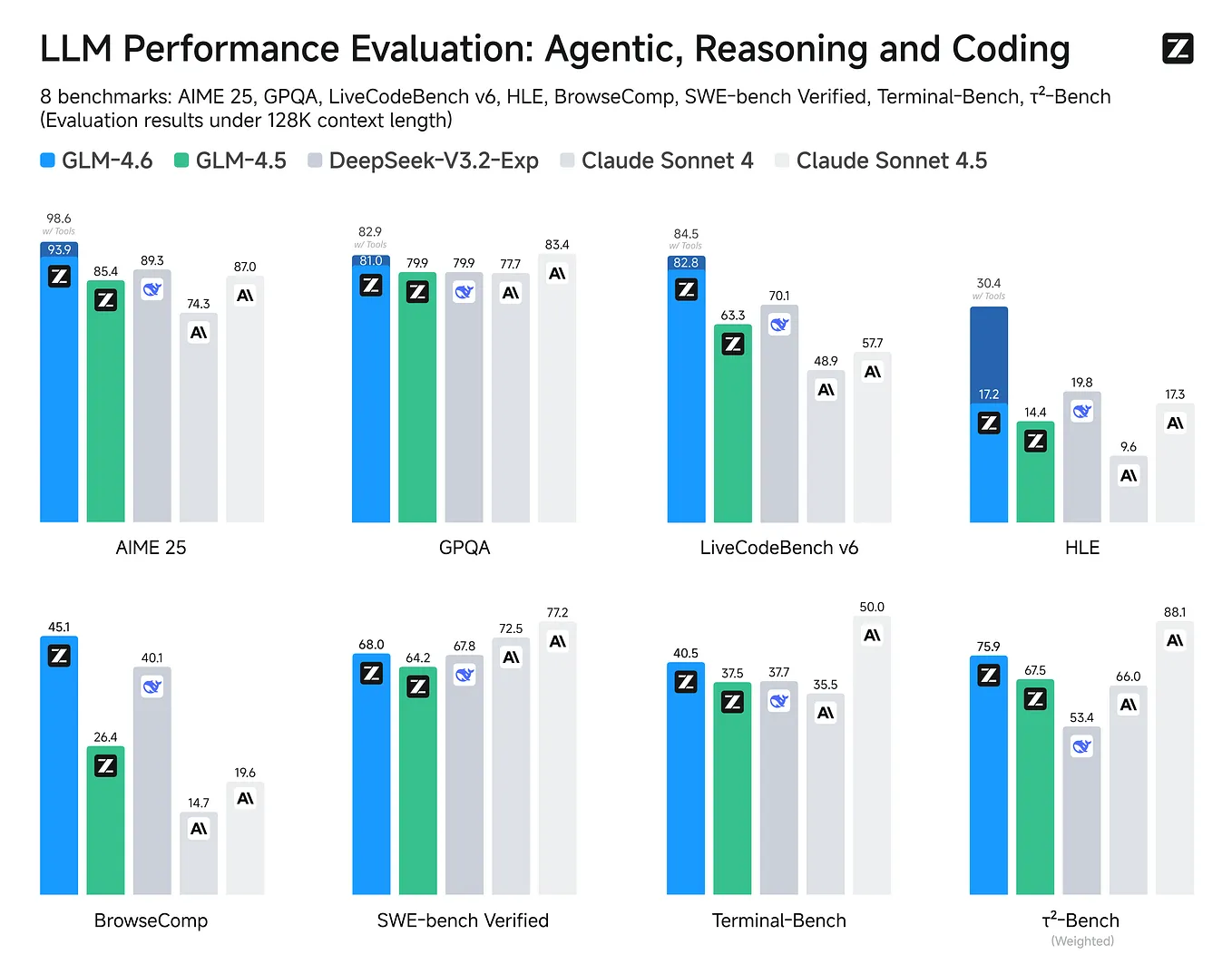
Claude Code generates HTML output that LLMs parse more accurately than Markdown, per a May 2026 analysis by developer Thariq. The technique exploits HTML's structural semantics to reduce ambiguity for downstream AI readers.
Key facts
- Claude Code generates HTML for LLM-readable docs over Markdown.
- HTML semantic tags reduce ambiguity for AI consumers.
- Hacker News thread: 515 points, 270 comments.
- Simon Willison amplified the finding on his blog.
Key Takeaways
- Claude Code generates HTML docs that LLMs parse more accurately than Markdown, per Thariq's analysis.
- Trade-off: harder for humans to edit.
What the analysis shows
Developer Thariq published a set of examples demonstrating Claude Code producing HTML documentation instead of Markdown [According to Using Claude Code]. The key insight: HTML's explicit semantic tags — <table>, <code>, <section> — reduce ambiguity for downstream AI readers. An LLM consuming a Markdown table must infer column boundaries from pipe characters; an HTML <table> with <th> and <td> leaves no room for misinterpretation.
Simon Willison, a prominent Python developer and LLM commentator, amplified the finding on his blog, calling it "unreasonable effectiveness" [per Simon Willison's blog]. The phrase echoes Andrej Karpathy's 2023 observation about GPT-2's tokenization — a pattern where a simple format choice yields disproportionate gains in machine comprehension.
The trade-off
Hacker News commenters flagged the downside: HTML is harder for a human to open and edit directly compared to Markdown [Hacker News, 515 points, 270 comments]. The top comment noted that for collaborative specs — spec sheets, design documents, anything requiring human co-authorship — Markdown remains preferred. "If it's just an explainer for your consumption, that's not a concern," the commenter wrote.
This mirrors a broader tension in AI-generated content: optimizing for machine readability versus human editability. Claude Code, an Anthropic agentic coding tool with direct file system and shell access, has been trending toward structured output formats. In April 2026, Anthropic published a post-mortem on Claude Code quality issues, acknowledging that verbosity and context retention regressions needed fixing [per Anthropic's post-mortem].
The unique angle
The story isn't that HTML works — it's that the LLM-as-consumer market is large enough to justify abandoning human-first formats. For Markdown, the primary consumer has always been a human reading rendered text. For HTML, the primary consumer is increasingly another LLM: a retrieval-augmented generation pipeline, an agentic workflow, or a future Claude instance re-reading its own output. This is a structural shift in how we think about document formats.
Prior art
Vision Transformers have long relied on structured representations for visual data [Knowledge Graph]. Claude Code uses the Model Context Protocol (MCP) to interact with GitHub repositories and file systems, meaning it already operates in a world where structured data exchange is the norm [55 sources confirm Claude Code uses MCP]. The HTML output pattern is a natural extension: if your tool already thinks in structured protocols, why output flat text?
What to watch
Watch for Anthropic to formalize this into a recommended output mode — perhaps a --format html flag — and for Cursor and GitHub Copilot to adopt similar strategies. The key metric: whether HTML-generated documentation reduces retrieval errors in RAG pipelines by a measurable margin, say 5-10% on a benchmark like MRR or NDCG.
What to watch
Watch for Anthropic to add a --format html flag to Claude Code, and for Cursor or GitHub Copilot to adopt similar structured output strategies. The key metric: whether HTML-generated docs reduce RAG retrieval errors by 5-10% on MRR or NDCG benchmarks.
[Updated 13 May via hn_claude_code]
Meanwhile, Claude Code itself has evolved in a complementary direction: on May 12, 2026, Anthropic shipped a /goal command that lets developers set a completion condition (e.g., "all tests pass and the PR is ready") and then walk away while Claude Code works autonomously across multiple turns [per Reddit r/ClaudeAI]. The new claude agents view tracks every running session — working, blocked, or done — turning the tool into a fire-and-forget loop. This asynchronous mode aligns with the HTML output strategy: both optimize for machine-driven workflows where the human sets objectives, not formats.








