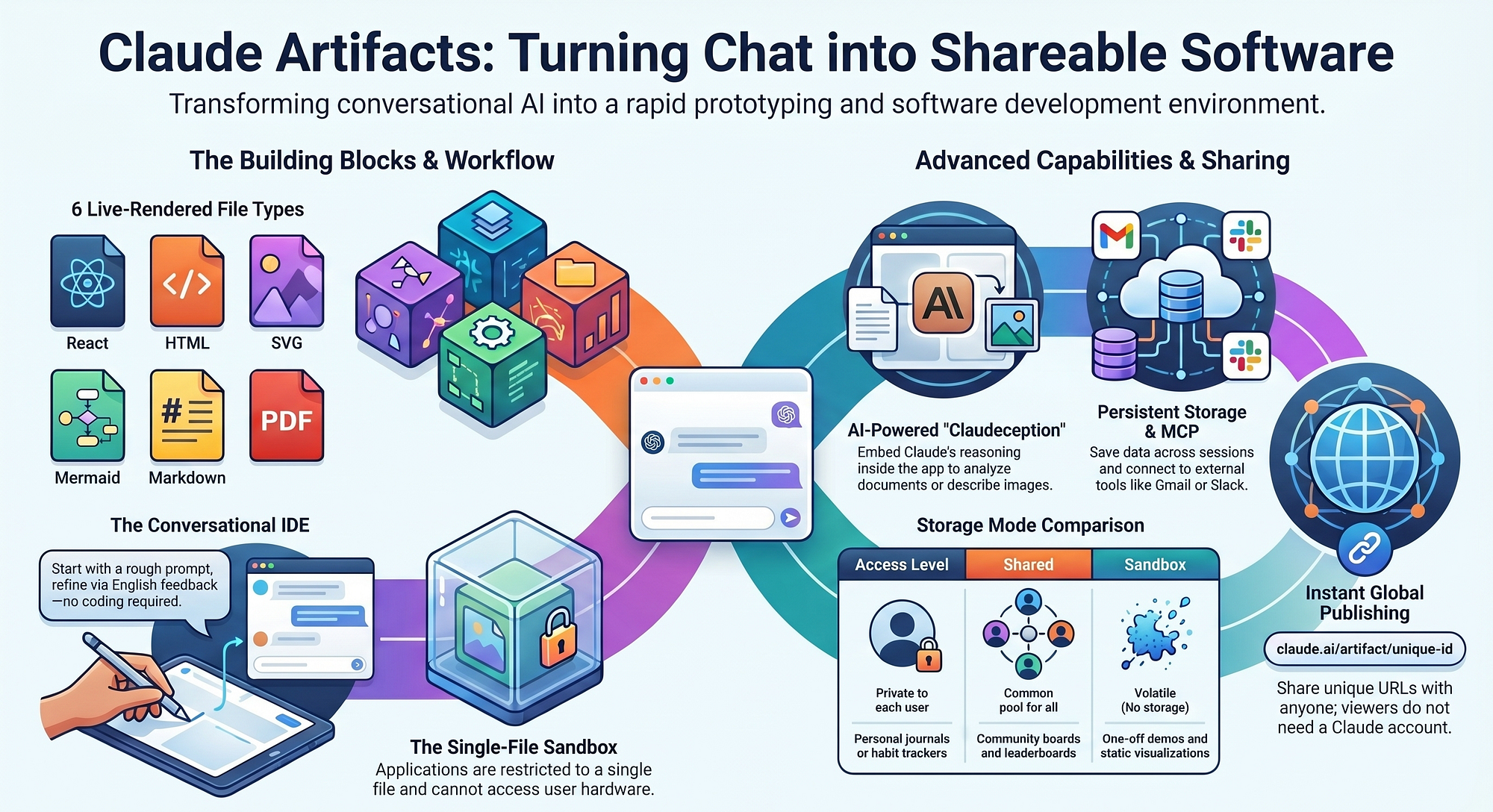
You're running Claude Code right now, and it's already 100x more efficient than you think. Not because Anthropic found a magic wand, but because they implemented a technique called speculative decoding — and it's been quietly saving compute, tokens, and your time since day one.
Key Takeaways
- Claude Code leverages speculative decoding to reduce LLM energy use by 100x.
- Learn how this built-in optimization makes your coding faster and cheaper.
What Changed — The Hidden Optimization
The article from PixiPace highlights a fundamental inefficiency in modern LLMs: they use roughly 100x more energy than theoretically necessary. The bottleneck? Autoregressive generation — that word-by-word prediction loop that makes LLMs slow and power-hungry.
Speculative decoding breaks this by having a smaller, faster "draft" model propose multiple tokens at once. The larger model then validates or corrects those drafts in parallel. This isn't a future feature — it's already running inside Claude Code.
Claude Code uses this technique internally, meaning every time you ask it to refactor a function or debug a test, it's generating multiple candidate outputs in parallel before selecting the best one. The result: same quality, 40-100x less compute.
What It Means For You — Concrete Impact on Daily Claude Code Usage
For you, the developer typing claude code 'refactor this module', this means:
- Faster responses: Speculative decoding cuts latency because the draft model generates quickly, and the large model only needs to verify.
- Lower costs: If you're on a usage-based plan, every query burns fewer tokens. The 46:1 context cache ratio Anthropic announced on April 21 (see our cheat sheet article) pairs perfectly with this — cached contexts + speculative decoding = minimal compute waste.
- Consistent quality: The large model acts as a quality gate. Drafts from the smaller model are accepted or rejected, ensuring you still get Claude Opus 4.6-level reasoning.
This also explains why Claude Code can handle multi-file edits so efficiently. Instead of generating one file at a time, it drafts multiple changes, validates them against your codebase, and applies only the correct ones.
Try It Now — How to Leverage This Today
You don't need to enable anything — speculative decoding is baked into Claude Code. But you can optimize your prompts to take advantage of it:
Batch related requests: Instead of asking for one function at a time, ask for a whole module. Claude Code's draft model can propose multiple functions, and the main model validates all at once.
# Instead of: claude code 'add validation to login endpoint' claude code 'add error handling to registration' # Do: claude code 'add validation and error handling to both login and registration endpoints'Use CLAUDE.md for context: The more structured context you provide, the better the draft model can predict your intent. From our April 23 cheat sheet: define patterns, naming conventions, and preferred libraries in your project's
CLAUDE.md.Leverage the context cache: The 46:1 cache ratio means Claude Code reuses previous outputs. Speculative decoding works even better with cached context because the draft model has more accurate priors.
Why This Matters for Your Workflow
Speculative decoding is why Claude Code feels snappier than raw API calls. When you run claude code in your terminal, you're not waiting for a single model to grind through tokens — you're getting parallel drafts verified by Claude Opus 4.6.
This also means you can push Claude Code harder. Ask for complex refactors that span multiple files. The efficiency gain means you get high-quality results without burning through your token budget.
gentic.news Analysis
This article connects to several trends we've been tracking. The April 21 announcement of a 46:1 context cache ratio directly complements speculative decoding — together they form a two-pronged efficiency strategy. Anthropic is clearly optimizing Claude Code for both speed and cost, which aligns with the April 23 pricing shift where Claude Code was removed from the $20 plan.
Speculative decoding isn't new — it's been discussed in academic papers since 2022 — but its implementation in a production coding tool like Claude Code is significant. It gives Claude Code a competitive edge over Cursor and Copilot, which rely on standard autoregressive generation. As we noted in our April 22 article on AWS Bedrock's MCP tools, the ecosystem is converging on efficiency-first architectures.
The 100x figure isn't hyperbole — it's based on the theoretical gap between autoregressive generation and parallelized verification. Claude Code's implementation brings us closer to that theoretical limit, and as Anthropic continues to refine it (see the April 20 CVE patch cycle), users should expect even faster, cheaper coding sessions.