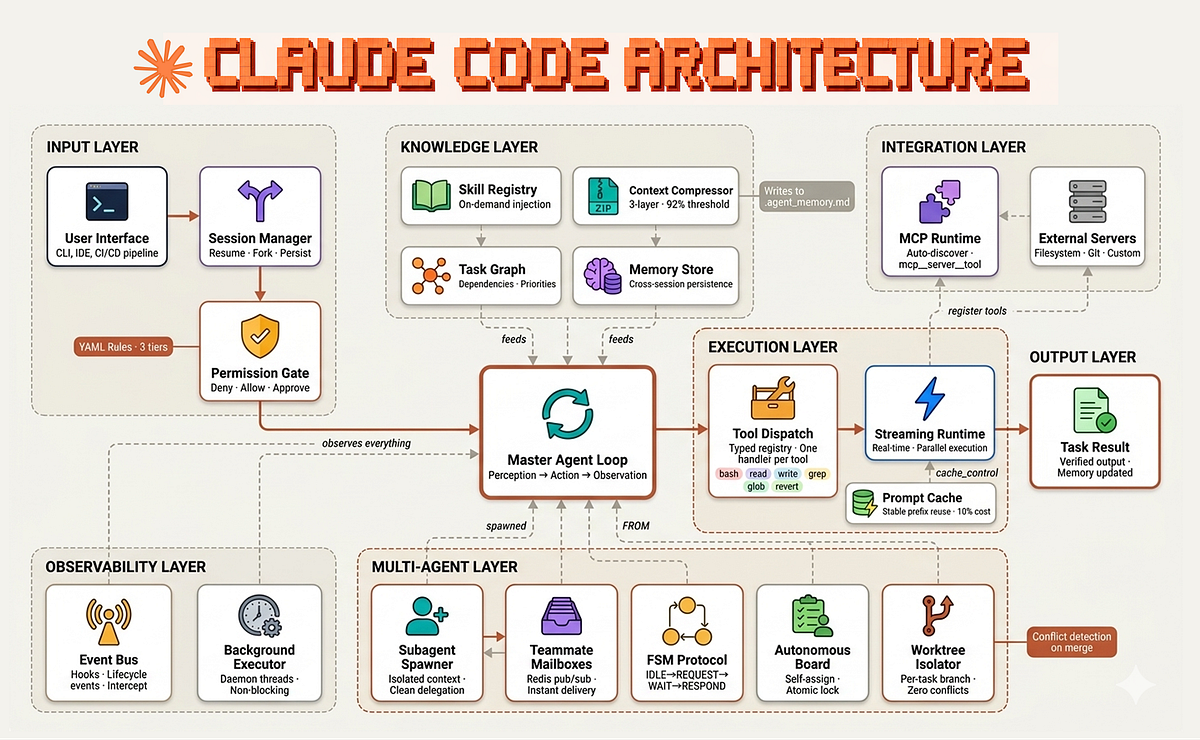
What the Analysis Found
Independent testing by SitePoint reveals potential quality regressions in Claude Sonnet 4.5 compared to Sonnet 4.0. While Anthropic's official documentation positions 4.5 as an upgrade across all metrics, real-world testing suggests the newer model may perform worse on certain coding and reasoning tasks that Claude Code users rely on daily.
This isn't about raw benchmark scores—it's about practical performance on the types of tasks developers actually use Claude Code for: code generation, debugging, refactoring, and system design.
What This Means for Your Claude Code Workflow
When you run claude code commands, you're typically using the latest available model by default. If you've noticed:
- More verbose but less precise code suggestions
- Increased need for follow-up prompts to correct logic errors
- Less consistent adherence to project conventions
You might be experiencing the regression effects documented in the analysis.
How to Test and Adapt
First, verify if you're affected. Create a simple test:
# Test with Sonnet 4.5 (likely your default)
claude code "Write a Python function that validates email addresses with regex"
# Test with Sonnet 4.0 explicitly
claude code --model claude-3-5-sonnet-20241022 "Write a Python function that validates email addresses with regex"
Compare the outputs for:
- Code quality - Which produces more correct, production-ready code?
- Reasoning - Which better explains edge cases and limitations?
- Conciseness - Which gives you what you need without unnecessary commentary?
Practical Workarounds for Claude Code Users
1. Pin Your Model Version
If you find Sonnet 4.0 performs better for your specific use cases, pin it in your CLAUDE.md:
# CLAUDE.md
## Model Preferences
- Default model: claude-3-5-sonnet-20241022 (Sonnet 4.0)
- Use 4.5 only for creative brainstorming tasks
2. Adjust Your Prompting Strategy
Sonnet 4.5 may require more explicit constraints. Instead of:
"Refactor this function to be more efficient"
Try:
"Refactor this function to improve time complexity. Provide only the code changes with minimal explanation. Use the existing naming conventions."
3. Use the Right Model for the Right Task
Consider this workflow:
- Sonnet 4.0 for: Code generation, debugging, refactoring
- Sonnet 4.5 for: Documentation, brainstorming, high-level design
- Opus 4.6 for: Complex system architecture or when accuracy is critical
4. Monitor Anthropic's Updates
Add this to your development checklist:
# Check for model updates monthly
claude code --list-models | grep sonnet
The Bottom Line for Developers
Model upgrades aren't always linear improvements. The Sonnet 4.5 regression analysis serves as a reminder: test before you trust. Claude Code gives you the flexibility to choose models—use it strategically based on performance, not just version numbers.
Until Anthropic addresses these regressions, smart Claude Code users will:
- Know which model version they're actually using
- Have fallback options for critical coding tasks
- Adjust prompting strategies based on model behavior
- Share specific regression examples with the community
Your productivity depends on reliable AI assistance. Don't let automatic upgrades degrade your workflow without your consent.