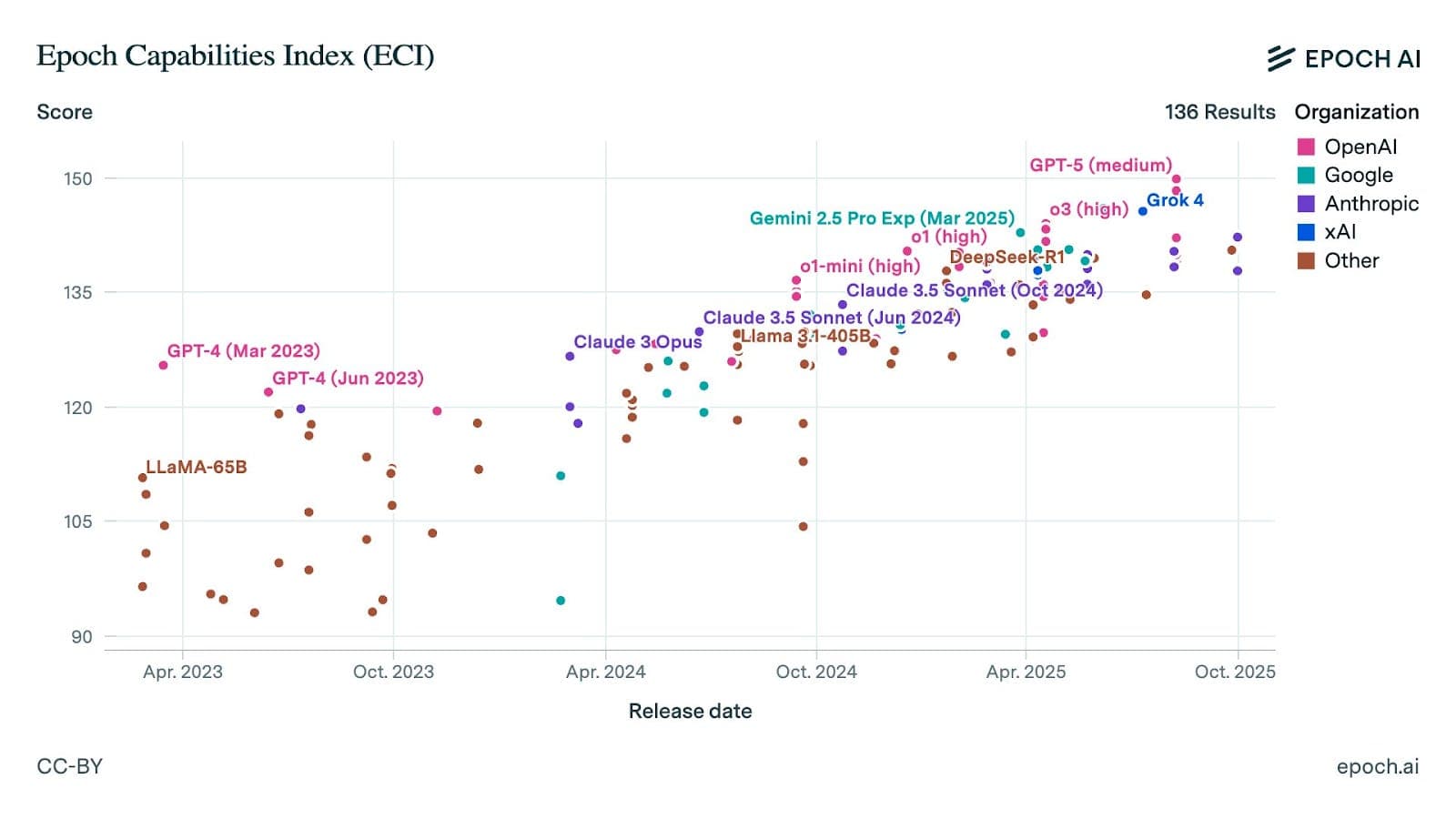
A developer was reportedly fired on the spot after his manager discovered he had used Anthropic's Claude AI to build a full-stack project over four months. According to a viral post on X (formerly Twitter) by the account @_vmlops, the manager then used the same AI to "vibe code" a replacement version in a matter of days and terminated the developer's employment.
The developer attempted to explain that large language models (LLMs) like Claude can hallucinate—generate plausible but incorrect or non-functional code—especially when dealing with complex, nuanced requirements. The manager reportedly dismissed this concern, choosing to believe the LLM's capability over the developer's firsthand experience building the original system.
The incident highlights a growing tension in software engineering management: the perceived efficiency of AI code generation versus the deep, contextual understanding required for production-ready software. The term "vibe coding" refers to a rapid, iterative process of prompting an AI to generate code, often without rigorous specification or testing.
Key Takeaways
- A developer was fired after his manager discovered he used Claude AI to build a project, then had the AI 'vibe code' a replacement in days.
- The manager dismissed the developer's warnings about AI hallucinations on complex requirements.
What Happened
The source material describes a specific sequence of events:
- A developer spent four months building a full-stack software project.
- The manager discovered the developer had used Claude AI during development.
- The manager prompted Claude ("vibe coded") to create a similar project, which reportedly produced a result in days.
- The manager fired the developer immediately.
- The developer's warning about AI hallucinations on complex requirements was disregarded.
Context: The AI Coding Tool Landscape
This incident occurs against the backdrop of widespread adoption of AI coding assistants. Tools like GitHub Copilot, Amazon CodeWhisperer, Replit AI, and advanced models like Claude 3.5 Sonnet, GPT-4, and DeepSeek-Coder are integrated into daily developer workflows. Their primary promise is increased productivity, with some studies suggesting they can help developers code 10-55% faster.
However, a consistent caveat from researchers and experienced engineers is that these tools are assistants, not replacements. They excel at boilerplate, common patterns, and well-defined tasks but struggle with novel architecture, complex business logic, and ensuring system-wide correctness. The phenomenon of "hallucination"—where the AI generates confident but incorrect code—is a well-documented and unsolved problem.
The Management Literacy Problem

The core argument of the original post is that this is "a management literacy problem." The manager's decision conflates the speed of generating code snippets with the comprehensive process of building software. The latter includes:
- Understanding Requirements: Translating vague business needs into precise specifications.
- System Design: Creating scalable, maintainable architecture.
- Integration: Ensuring new code works with existing systems and data.
- Testing & Validation: Writing unit, integration, and end-to-end tests; checking for edge cases.
- Debugging & Optimization: Identifying and fixing bugs, performance issues, and security vulnerabilities.
- Deployment & Maintenance: Managing builds, deployments, monitoring, and future updates.
An AI can accelerate pieces of this workflow, but it cannot autonomously own or guarantee the integrity of the entire process. A manager who sees only the initial code generation speed may fundamentally misunderstand the scope, risk, and skill involved in software engineering.
gentic.news Analysis
This anecdote is a stark, real-world example of a trend we've been tracking: the growing pains of AI integration into professional disciplines. It's less a story about AI's capabilities and more about human systems failing to adapt to them responsibly.
This aligns with our previous reporting on the limitations of AI coding. In our analysis of SWE-Bench, a benchmark that evaluates AI models on real-world GitHub issues, even the best models like Claude 3.5 Sonnet and GPT-4o only achieve resolution rates around 70-80% on verified tasks. This leaves a significant gap—20-30% of the time, the generated solution is incorrect or incomplete. In a production environment, that failure rate is catastrophic. The developer in this story was likely acting as the essential verifier and integrator for that other 20-30%, a role the manager failed to value.
The incident also reflects a broader management and business trend we've noted: the pressure to demonstrate AI-driven efficiency gains can lead to reckless implementation. When a tool like Claude is framed primarily as a cost-saving or speed-enhancing technology, rather than a skill-amplifying one, it incentivizes the kind of decision-making described here. The manager saw a chance to replace a perceived four-month cost with a days-long AI task, fundamentally misjudging the underlying work.
Looking forward, this case underscores the urgent need for AI literacy at all levels of an organization, especially for those making resource and personnel decisions. Technical teams have been rapidly upskilling on prompt engineering and AI-assisted workflows, but non-technical leadership often lacks the framework to assess the outputs and risks critically. This creates a dangerous asymmetry of understanding, where the promise of AI is taken at face value, and the experts warning of its limits are ignored.
Frequently Asked Questions
What is "vibe coding"?
"Vibe coding" is an informal term for using an AI assistant to generate code through iterative, conversational prompting. Instead of writing detailed specifications upfront, a developer or user provides high-level descriptions and refines the AI's output through follow-up prompts (e.g., "make it faster," "add error handling here"). It prioritizes rapid prototyping but can lack the rigor of traditional software design.
Can an AI like Claude build a full production-ready application?
No, not autonomously. While AI models can generate large volumes of code and even create simple, standalone applications, a production-ready system requires integration with specific infrastructure, databases, APIs, and security protocols. It needs comprehensive testing, documentation, deployment pipelines, and ongoing maintenance—tasks that require human oversight, architectural understanding, and contextual knowledge of the business environment. AI is a powerful assistant within this process but not a substitute for it.
What are AI hallucinations in coding?
In the context of coding, a hallucination occurs when an AI generates code that is syntactically correct (looks like real code) but is logically flawed, uses non-existent libraries or APIs, or implements algorithms incorrectly. The AI "confidently" presents this code as a solution. Detecting these hallucinations requires expert review and testing, which is why human developers remain essential.
How should managers evaluate AI-generated code?
Managers should treat AI-generated code with the same scrutiny as human-generated code, if not more. It must go through standard software development lifecycle (SDLC) gates: code review by senior engineers, integration testing, security scanning, and performance benchmarking. The metric should not be "how quickly was the first draft of code produced?" but "how quickly was a correct, secure, and maintainable feature shipped to users?" The former is often misleading, as this story illustrates.