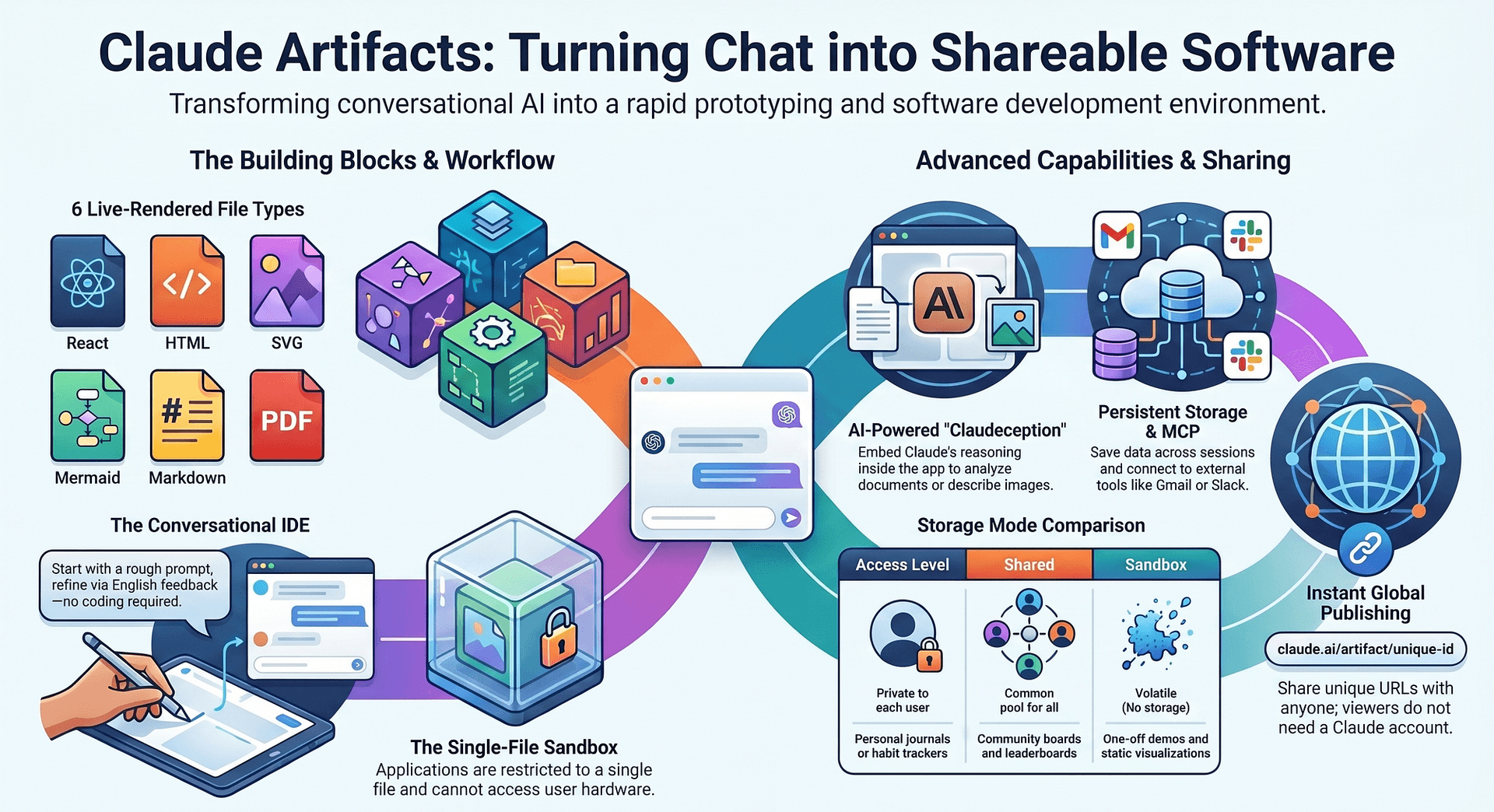
A new open-source project called DFlash brings the performance-boosting technique of speculative decoding to Apple Silicon Macs, using Apple's native MLX machine learning framework without requiring a fork. The project, highlighted in a social media post by developer @bstnxbt, demonstrates significant inference speedups for large language models (LLMs) on Apple hardware.
What Happened
DFlash is an implementation of speculative decoding—a technique where a small, fast "draft" model proposes candidate token sequences, which are then verified in parallel by a larger, more accurate "target" model. This approach can dramatically reduce latency without changing model outputs.
The key technical achievement of DFlash is its integration with MLX, Apple's array framework for machine learning on Apple Silicon. The project works with "stock MLX," meaning developers can use it without modifying or forking the core MLX library—a significant advantage for maintainability and compatibility.
Performance Claims
According to the initial report, DFlash achieves notable speedups on Apple's latest hardware:
- Up to 2.5x speedup on an M5 Max chip
- Tested at 2048 token context length
- Uses standard MLX without modifications
The project appears to be in early development, with the source code available via the shared link. The implementation suggests Apple Silicon developers now have access to one of the most effective inference optimization techniques previously more common in cloud and NVIDIA GPU environments.
Technical Context: Speculative Decoding on Apple Silicon
Speculative decoding has become a standard optimization for LLM inference, popularized by techniques like Google's Medusa and NVIDIA's vLLM implementations. The approach works particularly well when:
- The draft model is significantly faster than the target model
- The draft model has high prediction accuracy for the next tokens
- The verification step can be parallelized efficiently
Apple's MLX framework, introduced in late 2023, provides a unified framework for machine learning across Apple Silicon chips (M-series). It offers NumPy-like arrays with GPU acceleration and a familiar API for PyTorch users. DFlash's use of "stock MLX" means it should work with existing MLX model implementations with minimal changes.
What This Means for Developers
For AI engineers working on Apple Silicon:
- Potential for faster local inference – The 2.5x speedup claim, if validated across more benchmarks, could make local LLM deployment more practical
- No framework fork required – Using stock MLX simplifies integration and maintenance
- Open-source availability – The code appears to be publicly accessible for experimentation and improvement
However, developers should note that these are early results. The performance gains will depend on specific model pairs (draft vs. target), batch sizes, and prompt characteristics. The project's maturity, documentation, and community support remain to be seen.
gentic.news Analysis
This development represents a natural evolution in the Apple Silicon AI ecosystem. Since Apple introduced the MLX framework in December 2023, the community has been building out the optimization toolkit that makes NVIDIA's CUDA ecosystem so productive. Speculative decoding was a notable gap—until now.
DFlash aligns with the broader trend of inference optimization moving from research papers to production-ready implementations. As we covered in our February 2026 analysis of the MLX ecosystem, Apple's strategy has been to provide the core framework while relying on the open-source community for specialized optimizations. DFlash fits this pattern perfectly.
The timing is particularly interesting given Apple's increased focus on on-device AI throughout 2025 and early 2026. With the M5 chip family now established and developers seeking ways to run larger models locally, techniques like speculative decoding become essential. If DFlash's performance claims hold up under broader testing, it could significantly impact the economics of local AI deployment on Macs.
However, the real test will be in adoption. The MLX ecosystem, while growing, still lacks the breadth of optimizations available for PyTorch/TensorFlow with CUDA. Projects like DFlash need to demonstrate not just speedups in controlled tests but also robustness across diverse models and workloads. The "no fork" approach is smart—it lowers the barrier to entry—but may limit how deeply the optimization can be integrated compared to forked frameworks.
Frequently Asked Questions
What is speculative decoding?
Speculative decoding is an inference optimization technique where a small, fast "draft" model proposes several future tokens in sequence. These proposals are then verified in parallel by the larger, more accurate "target" model. If the draft model's predictions are correct, the target model accepts them all at once, bypassing its normal sequential processing. This can provide 2-3x speedups with identical outputs to standard decoding.
Does DFlash work with any MLX model?
Based on the available information, DFlash should work with models implemented using the standard MLX framework. However, optimal performance likely requires careful pairing of draft and target models—the draft model needs to be significantly faster while maintaining reasonable prediction accuracy. Developers may need to experiment with different model pairs to achieve the best results for their specific use case.
How does this compare to speculative decoding on NVIDIA GPUs?
The core algorithm is the same, but the implementation is optimized for Apple's Metal Performance Shaders and memory architecture. NVIDIA implementations typically use CUDA and might have more mature optimizations due to longer development time. However, DFlash represents Apple Silicon catching up in terms of available optimization techniques.
Is DFlash production-ready?
The project appears to be in early development based on the social media announcement. While the performance claims are promising, developers should conduct their own benchmarking and testing before deploying it in production applications. The open-source nature suggests it will evolve based on community feedback and contributions.