
A brief social media post from a developer has hinted at an upcoming release aimed at improving the efficiency of large language model inference. The post states that "Dflash + continuous batch is coming" and notes that current draft models work best with text-only inputs.
What Happened
The post, from a developer account, is a teaser for an upcoming tool or method called "Dflash." The key promised feature is the integration of "continuous batch" processing. This terminology is commonly associated with inference servers (like vLLM or TGI) that dynamically batch incoming requests to maximize GPU utilization, as opposed to static batching.
The developer also contextualized the announcement by stating that "the current draft models are best with text-only inputs." This is a direct reference to the prevailing technique of speculative execution (also called assisted generation), where a small, fast "draft" model proposes a sequence of tokens, which are then verified in parallel by a larger, more accurate "target" model. This method, pioneered by projects like Google's Medusa and popularized by frameworks like NVIDIA's TensorRT-LLM, can significantly increase inference speed.
The mention of "text-only" suggests that the current generation of draft model implementations may be optimized for or limited to pure text modalities, as opposed to multimodal inputs.
Context
Speculative execution has become a critical optimization for deploying large language models in production since 2024. The core challenge is maintaining the quality and acceptance rate of the draft model's proposals while minimizing latency. Efficient batching is paramount for achieving high throughput in server environments.
The term "Dflash" does not correspond to a widely known public project as of April 2026. It could be an internal code name, a new open-source tool, or a feature within an existing inference framework. The promise of "continuous batch" support specifically for draft model workflows suggests a focus on improving the scalability and efficiency of speculative execution systems.
gentic.news Analysis
This teaser points to the next layer of optimization in the LLM inference stack. The initial wave of speculative execution research (e.g., Medusa, EAGLE) focused on the algorithm itself—designing better draft models and verification mechanisms. The subsequent industrial implementation phase, led by inference engines like vLLM and SGLang, integrated these techniques. Now, the focus appears to be shifting to orchestration efficiency: how to manage continuous, dynamic batches of requests that are each using a two-model speculative execution pipeline.
This development aligns with the broader trend we've tracked of inference engineering becoming increasingly specialized and modular. In 2025, we covered the release of SpecDec, a decoding-only architecture that separated drafting from verification into distinct, optimized components. A tool like Dflash could be the runtime scheduler that manages these components at scale. The explicit callout of "text-only" draft models also hints at an impending need for multimodal speculative execution, as models like GPT-4o and Gemini 1.5 Pro become standard. Optimizing for text-first is a logical stepping stone.
For practitioners, the key metric to watch will be how Dflash impacts the total cost of ownership for high-throughput LLM endpoints. The theoretical speedups of speculative execution can be eroded by poor batching and scheduling overhead. A dedicated continuous batching solution for this paradigm could make the difference between a lab benchmark and a viable production deployment.
Frequently Asked Questions
What is speculative execution in LLMs?
Speculative execution is an inference optimization technique where a small, fast "draft" model generates several candidate tokens in sequence. These tokens are then passed as a batch to the larger, primary "target" model, which verifies them in a single forward pass, rejecting incorrect ones. This allows the slower target model to generate multiple tokens per step, significantly increasing decoding speed.
What is continuous batching?
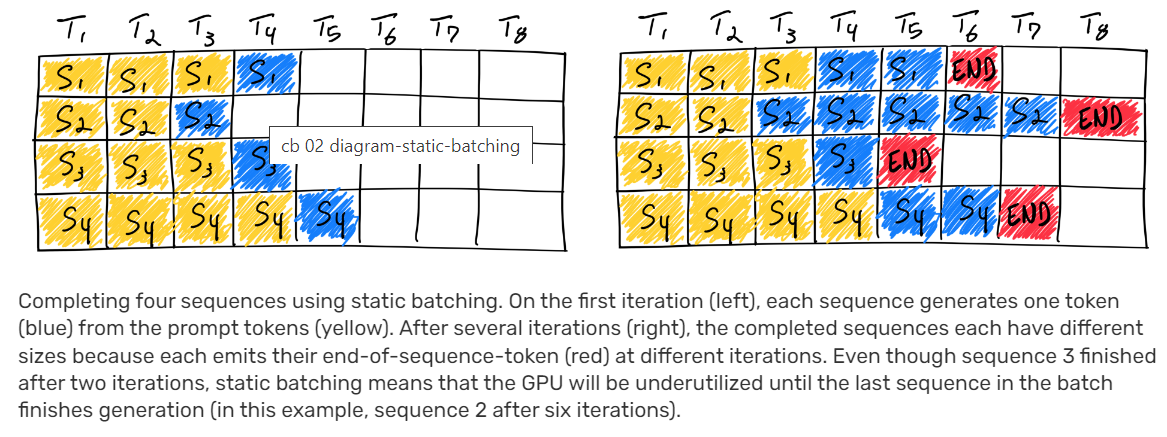
Continuous batching (also known as iterative or dynamic batching) is a method used in inference servers to improve GPU utilization. Instead of waiting for a fixed batch size to be collected or for an entire request to finish, the scheduler continuously adds new requests to the running batch and removes finished ones at each decoding step. This is crucial for handling variable-length requests in production environments.
What are draft models?
Draft models are small, fast language models (often distilled from the larger target model) used specifically for the proposal phase of speculative execution. Their sole purpose is to generate plausible token sequences quickly, sacrificing some accuracy for speed. Their performance is measured by their "acceptance rate"—how often their proposed tokens are verified by the target model.
Why does the post mention 'text-only' inputs?
Most publicly available implementations and research on speculative execution for LLMs has focused on text generation. Multimodal models (which process images, audio, and text) have more complex inference graphs and attention patterns, making it harder to design an effective, small draft model. The note suggests current draft model technology is most mature and effective for pure text modalities.








