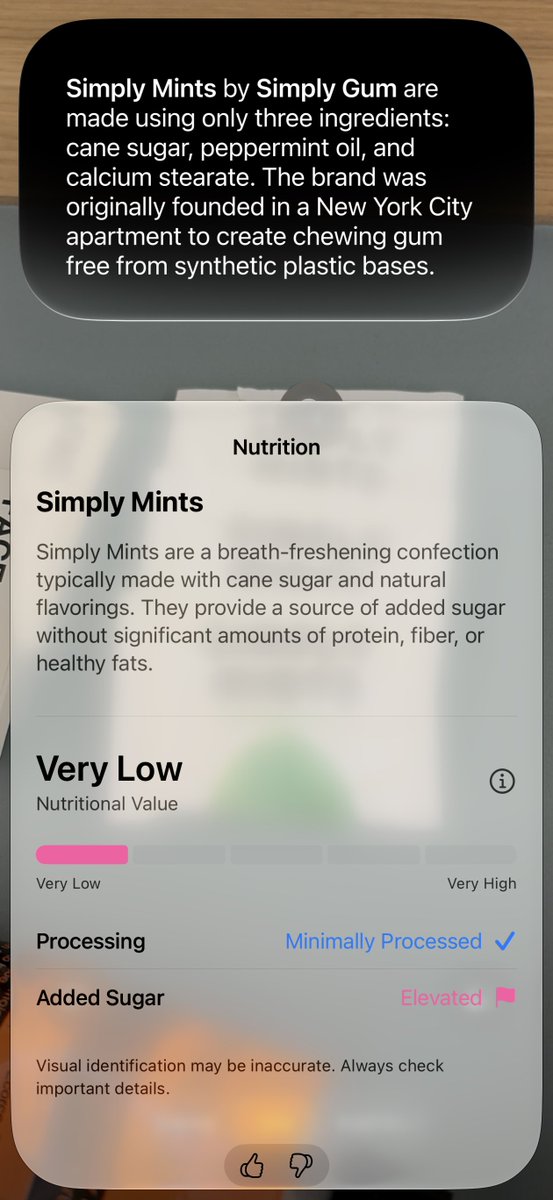
What Happened
A software engineer, after 17 months of unexplained symptoms and consultations with over 15 specialists across neurology, cardiology, and ENT, used ChatGPT-4o and Google to self-diagnose a rare spinal cerebrospinal fluid (CSF) leak. According to a detailed account shared on social media, traditional medical pathways had failed to identify the condition, which causes positional headaches, neck pain, tinnitus, and brain fog when upright.
The engineer, experiencing debilitating symptoms that worsened when standing, began his own research after standard MRI scans returned normal results. He prompted ChatGPT-4o with a detailed list of his symptoms and the fact that they were positional. The AI model suggested a possible spinal CSF leak and recommended specific diagnostic tests—primarily a brain MRI with contrast and, if negative, a spinal MRI.
Armed with this information, he researched the condition on Google, found matching patient stories in online forums like Reddit, and compiled medical literature. He then presented this research to a new neurologist, specifically requesting the tests ChatGPT had suggested. The brain MRI with contrast revealed signs consistent with a CSF leak, leading to a confirmed diagnosis.
Context
Spontaneous intracranial hypotension (SIH) caused by a spinal CSF leak is a rare and often misdiagnosed condition. Diagnosis is challenging as it requires specific imaging protocols not always included in standard neurological workups. The standard initial test is a brain MRI with contrast to look for signs of intracranial hypotension, such as dural enhancement or brain sag. The engineer's case underscores a known gap: patient anecdotes and niche online communities have long discussed the difficulty of obtaining this diagnosis.
This is not the first reported instance of patients or caregivers using AI for diagnostic assistance. However, it is a notable example of an individual systematically using a large language model (LLM) to navigate a complex diagnostic dead-end, moving from a broad symptom list to a specific, testable hypothesis that specialists had missed.
The story, as shared, does not detail the engineer's specific prompts or the exact sequence of ChatGPT's responses. It emphasizes the outcome: a correct hypothesis that led to a confirmatory test.