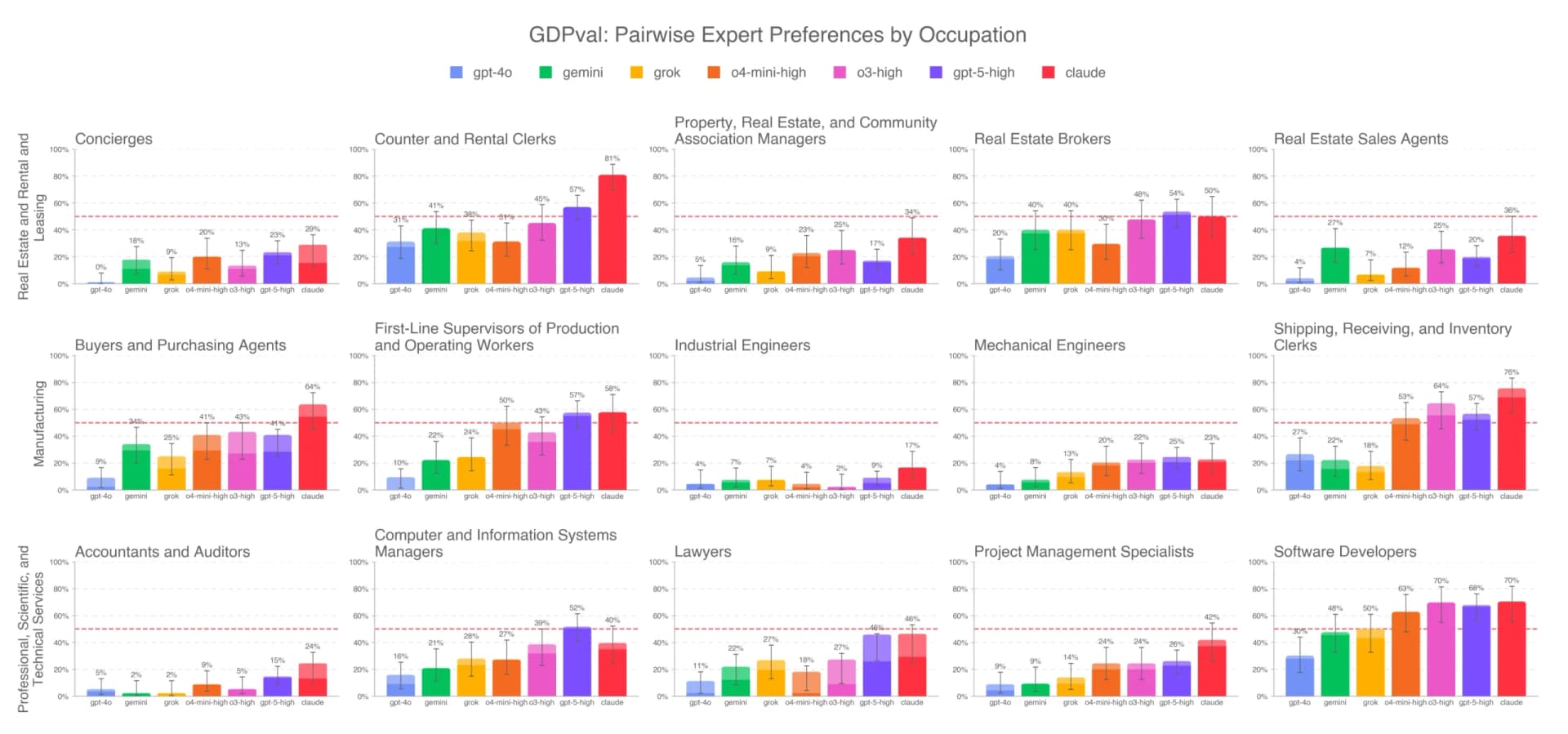
In a recent public critique, Ethan Mollick, a professor at the Wharton School and a prominent voice on AI adoption, singled out a specific AI model benchmark for being uninformative. While praising the benchmarking platform Artificial Analysis for its overall transparency, Mollick stated that the GDPval-AA benchmark is "not a good benchmark and needs to stop being reported."
What Happened

On X (formerly Twitter), Mollick explained the core issue with the GDPval-AA benchmark. The benchmark uses Google's Gemini 3.1 model to judge the outputs of other AI models on questions from the public GDPval dataset. According to Mollick, this methodology "tells us nothing" meaningful about the actual performance or capabilities of the models being evaluated.
The critique centers on a fundamental problem in AI evaluation: using one model (an "AI judge") to score another. If the judge model has specific biases, limitations, or simply a different interpretation of quality, its scores may reflect the judge's characteristics more than the capabilities of the model being tested. When the test questions are also public, the benchmark becomes even less reliable for measuring genuine reasoning or knowledge.
Context: The Benchmarking Landscape
The call highlights the ongoing challenges and debates within the AI community regarding how to properly evaluate large language models (LLMs). As models become more capable, creating benchmarks that are robust, unbiased, and truly measure intelligence or usefulness is increasingly difficult.
Platforms like Artificial Analysis aggregate scores from multiple public benchmarks (like MMLU, GPQA, and HumanEval) to provide a composite view of model performance. The GDPval-AA appears to be one component of this aggregation. Mollick's criticism suggests that including this particular metric may distort the overall picture presented to developers and researchers who rely on these scores for decision-making.
The Implication for Practitioners
For AI engineers and technical leaders, benchmark scores are a key data point for model selection, whether for prototyping, production use, or research comparison. A flawed benchmark can lead to suboptimal choices or misallocated resources. Mollick's public call to stop reporting GDPval-AA is a direct recommendation to the community to refine its evaluation criteria and focus on metrics that provide actionable, trustworthy signals.
gentic.news Analysis
Mollick's critique taps into a critical and persistent tension in AI development: the benchmark arms race versus real-world utility. As we've covered extensively, including in our analysis of the Vibe-Eval benchmark's attempt to measure "vibes" and the controversies surrounding data contamination in training sets, the community is grappling with evaluation methodologies that keep pace with model capabilities. When a benchmark like GDPval-AA relies on another LLM as a judge on public data, it risks measuring benchmark-specific optimization rather than generalizable skill.
This aligns with a broader trend of increased scrutiny on evaluation integrity. In recent months, we've seen similar discussions around the SWE-bench coding benchmark and its "verified" versus "unverified" scores, where the method of answer verification drastically changes the leaderboard. Mollick, whose work focuses on how professionals actually integrate AI into workflows, is effectively arguing for benchmarks that correlate with practical performance, not just circular, model-on-model grading.
The entity relationship here is also notable. Artificial Analysis (the benchmarking platform) aggregates data, while Google's Gemini is the judge model in question. Mollick's criticism isn't of Gemini's capabilities per se, but of its use as an evaluation tool in this specific, flawed configuration. This serves as a reminder that even outputs from top-tier models should not be uncritically treated as ground truth, especially when they form the basis of competitive scoring.
Frequently Asked Questions
What is the GDPval-AA benchmark?
GDPval-AA is a benchmark score reported by the platform Artificial Analysis. It uses Google's Gemini 3.1 model to evaluate the responses of other AI models to questions from the public GDPval dataset.
Why does Ethan Mollick say GDPval-AA is a bad benchmark?
Mollick argues it "tells us nothing" because it uses one AI model (Gemini 3.1) to judge others on public questions. This creates a circular evaluation where the scores may reflect the judge model's biases and the benchmark's susceptibility to contamination, rather than measuring true model capability or reasoning.
What is Artificial Analysis?
Artificial Analysis is a platform that aggregates performance scores from multiple public AI benchmarks to provide composite rankings and comparisons of large language models (LLMs).
How should developers evaluate AI models if some benchmarks are flawed?
Developers should rely on a suite of benchmarks, prioritize those with robust, human-verified evaluation methods, and—critically—conduct their own task-specific evaluations on private datasets that reflect their actual use cases. No single public benchmark score should be the sole criterion for model selection.






