In a provocative social media post, developer Gur Singh declared that "Cloud GPU training is a scam," arguing that aggregated consumer Apple Silicon can match the performance of high-end, expensive cloud GPUs like the NVIDIA A100.
What Happened
Singh's core claim is based on a performance-per-dollar comparison. He states that a single M4 MacBook provides 2.9 TFLOPS (Trillions of Floating-Point Operations Per Second). By his calculation, a cluster of seven such machines would theoretically match the compute throughput of a single NVIDIA A100 GPU, which is a standard workhorse for AI training in data centers.
The implication is that a small, decentralized group of individuals pooling their consumer-grade hardware could achieve similar raw compute power to a single high-end cloud instance, but at a potentially much lower total cost of ownership, avoiding the recurring rental fees of cloud providers.
Context
The post taps into a growing undercurrent of frustration among developers and researchers regarding the high and often unpredictable costs of training AI models on cloud platforms like AWS, Google Cloud, and Azure. The dominant paradigm has been to rent access to clusters of GPUs like the A100, H100, or B200, which can cost tens of dollars per hour.
Apple's M-series chips, built on ARM architecture, have gained attention for their impressive energy efficiency and sustained performance in machine learning tasks, particularly for inference. Frameworks like PyTorch and MLX (Apple's machine learning library for Apple Silicon) have made it increasingly feasible to run and fine-tune models locally. However, the assertion that they are a cost-effective substitute for large-scale training on specialized data center GPUs is a more contentious and technically complex claim.
Key Caveats from the Technical Community:
Immediate responses to such claims typically highlight critical differences:
- Memory Bandwidth & VRAM: The A100 features 80GB of ultra-fast HBM2e memory with over 2TB/s of bandwidth, crucial for training large models. An M4 MacBook's unified memory, while impressive, does not match this scale or bandwidth.
- Interconnect Speed: Connecting seven separate laptops with network cables (even 10GbE) introduces massive latency and bandwidth bottlenecks compared to the NVLink connections between GPUs in a server.
- Software & Framework Maturity: NVIDIA's CUDA ecosystem is deeply optimized for distributed training. Efficiently parallelizing a training job across seven independent macOS systems is a significant engineering challenge compared to using a managed cloud cluster.
- TFLOPS Comparison: Comparing peak TFLOPS between different architectures (Apple's Neural Engine vs. NVIDIA's Tensor Cores) is an oversimplification. Real-world training performance depends heavily on memory hierarchy, software stack, and numerical precision support.
What This Means in Practice

For individual developers or small teams, the post reinforces the viability of local fine-tuning and experimentation on Apple Silicon, which can indeed be more cost-effective for certain workloads than spinning up cloud instances. It challenges practitioners to critically evaluate the true necessity of cloud GPUs for every task.
However, for training foundation models from scratch or at massive scale, the infrastructure, reliability, and software advantages of professional cloud and on-premise GPU clusters remain largely unchallenged by this proposed approach. The real cost of the "scam" is often the convenience, speed, and managed infrastructure, not just raw FLOPs.
gentic.news Analysis
This sentiment from Gur Singh is not an isolated take but part of a broader, measurable trend of cost-push innovation and decentralization in AI infrastructure. As cloud GPU costs remain high, developers are actively seeking alternatives, creating a pull for more efficient hardware and frameworks. This aligns with our previous coverage on the rise of Groq's LPUs for inference and the growing developer interest in Cerebras's wafer-scale engines for training, both of which challenge NVIDIA's dominance on different fronts.
The push towards consumer hardware clusters also conceptually dovetails with earlier, albeit less successful, movements like volunteer computing (e.g., Folding@Home). The key difference today is the proliferation of powerful, ML-accelerated chips in consumer devices. Apple, with its vertical integration and MLX framework, is uniquely positioned to capitalize on this trend if it can simplify distributed training across its devices.
However, Singh's argument faces the same fundamental hurdle as many decentralized compute projects: coordination overhead. The historical trend, as seen with rendering farms and scientific computing, is that while hobbyist clusters can be built, professional workflows almost always consolidate into centralized, high-efficiency data centers for reliability and performance. The current AI training boom, led by entities like OpenAI, Anthropic, and Meta, has followed this pattern, investing billions in dedicated GPU clusters. Singh's provocation is less a near-term blueprint and more a critique of a market where alternatives are desperately being sought.
Frequently Asked Questions
Can you really train AI models on a cluster of MacBooks?
Technically, yes, for smaller models or specific tasks, using frameworks like PyTorch with distributed data parallel (DDP) or Apple's MLX. However, efficiently coordinating training across multiple independent machines over a network is far more complex and prone to bottlenecks than using a multi-GPU server. It is practical for experimentation and learning but not for state-of-the-art foundation model training.
Is an M4 MacBook's 2.9 TFLOPS comparable to an A100's TFLOPS?
Not directly. The A100's TFLOPS are measured on its Tensor Cores for specialized matrix math (e.g., FP16/BF16) critical for AI. The M4's figure likely includes its CPU, GPU, and Neural Engine performance across different operations. Real-world AI training throughput on an A100 will be vastly higher due to its memory system, interconnects, and mature software stack.
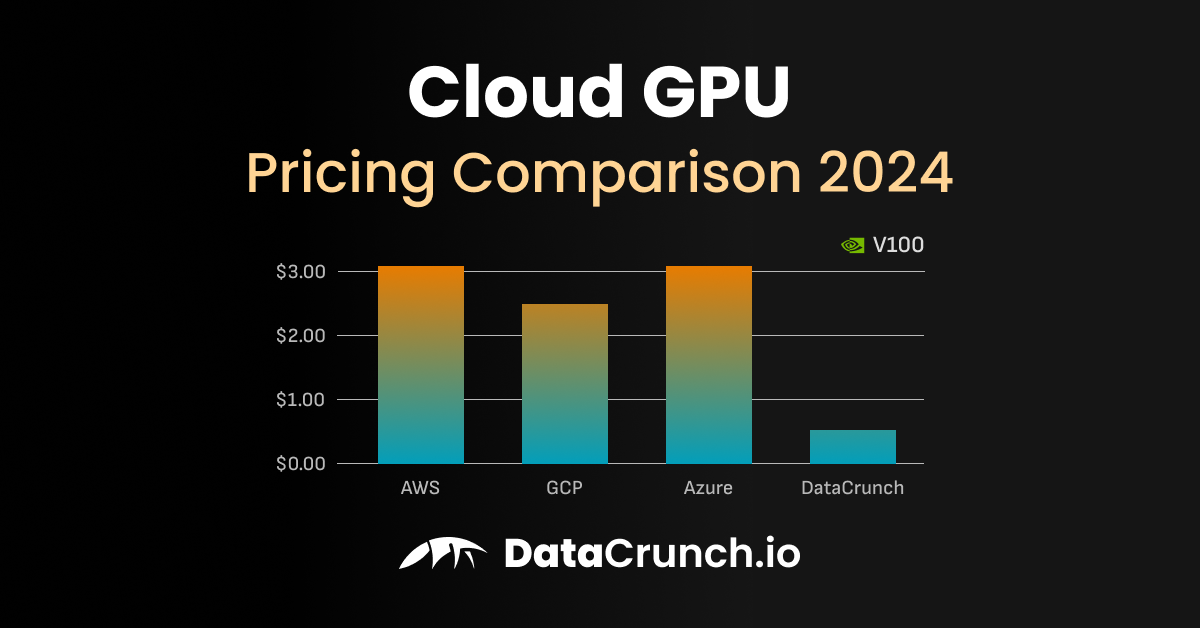
What are the real costs of cloud GPU training versus buying hardware?
Cloud GPUs (e.g., an A100 instance) can cost $3-$40+ per hour. The upfront cost of 7 high-end M4 MacBook Pros is significant (likely $20,000+). The cloud offers flexibility, no maintenance, and immediate scaling. The MacBook cluster is a capital expense with depreciation, but no recurring rental fee. The "breakeven" point depends entirely on usage hours and whether the local hardware can complete the job in a comparable timeframe.
Are there any projects actually doing distributed AI training on consumer devices?
Yes, but they are largely in the research or hobbyist phase. Projects like TensorFlow Federated and PySyft explore federated learning across decentralized devices. Petals allows running large language models collaboratively across consumer GPUs. However, these focus more on inference or specialized privacy-preserving training, not competing directly with centralized cloud training for large-scale model development.