ModelBest released BitCPM-CANN, the first 1.58-bit ternary LLM trained end-to-end on Ascend 910B NPUs. The model uses 6× less VRAM than BF16 while retaining most capability, in 4 open-source sizes.
Key facts
- First 1.58-bit ternary LLM on Ascend 910B NPUs.
- 6× less VRAM than BF16.
- 4 model sizes, fully open-source.
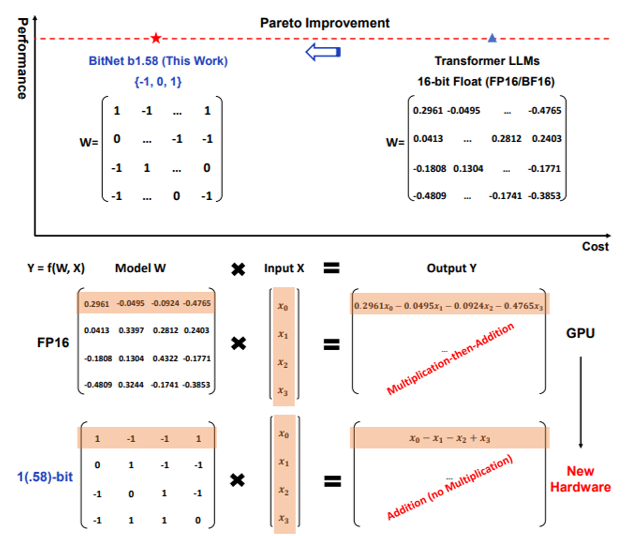
- Weights stored as -1, 0, or +1 (2 bits each).
- Based on BitNet b1.58 (Wang et al. 2024).
ModelBest released BitCPM-CANN, the first 1.58-bit ternary LLM trained end-to-end on Ascend 910B NPUs, according to a post by @hasantoxr on X. The model uses 6× less VRAM than BF16 while retaining the vast majority of capability, and comes in 4 model sizes, all fully open-source.
The 1.58-bit ternary format means each weight is stored as one of three values: -1, 0, or +1, requiring only two bits per parameter. This is an extension of the BitNet b1.58 concept proposed by Wang et al. (2024), which showed that ternary weights can match FP16 performance on language tasks with drastically reduced memory and compute. ModelBest's implementation is the first to train such a model end-to-end on Ascend NPUs, not just quantize a pre-trained model.
Why this matters
The unique angle here is that BitCPM-CANN's training on Ascend 910B NPUs marks a departure from the Nvidia GPU-dominated LLM training landscape. The Ascend 910B, developed by Huawei, is a Chinese AI accelerator that has been subject to US export restrictions. By demonstrating a competitive LLM trained entirely on domestic hardware, ModelBest signals a potential decoupling of Chinese AI development from Western supply chains. The 6× VRAM reduction also makes the model viable on less powerful hardware, lowering the barrier for inference on edge devices.
The company did not disclose exact benchmark scores or the specific model sizes (presumably ranging from 1B to 7B parameters, based on typical CPM model releases). However, the claim of 'vast majority of capability' suggests that BitCPM-CANN may achieve performance comparable to its BF16 counterpart on standard NLP benchmarks like MMLU or C-Eval, though independent verification is pending.
Prior art and context
BitNet b1.58 (Wang et al. 2024) demonstrated that ternary LLMs could match FP16 perplexity on 3B-parameter models. ModelBest's contribution is the training pipeline on Ascend hardware, optimizing for the NPU's instruction set and memory hierarchy. The open-source release includes weights, training code, and inference scripts, making it the first fully reproducible ternary LLM on non-Nvidia hardware.
What to watch
Watch for independent benchmark evaluations on MMLU and C-Eval to verify the capability retention claim. Also monitor whether ModelBest releases inference benchmarks on Ascend 910B vs. Nvidia A100 to quantify the real-world speedup. The broader signal is whether other Chinese AI labs follow suit with Ascend-native training recipes, potentially accelerating the shift away from Nvidia GPUs in China.
What to watch
Watch for independent benchmark evaluations on MMLU and C-Eval to verify capability retention. Also monitor whether ModelBest releases inference benchmarks on Ascend 910B vs. Nvidia A100. The broader signal is whether other Chinese AI labs follow suit with Ascend-native training recipes.