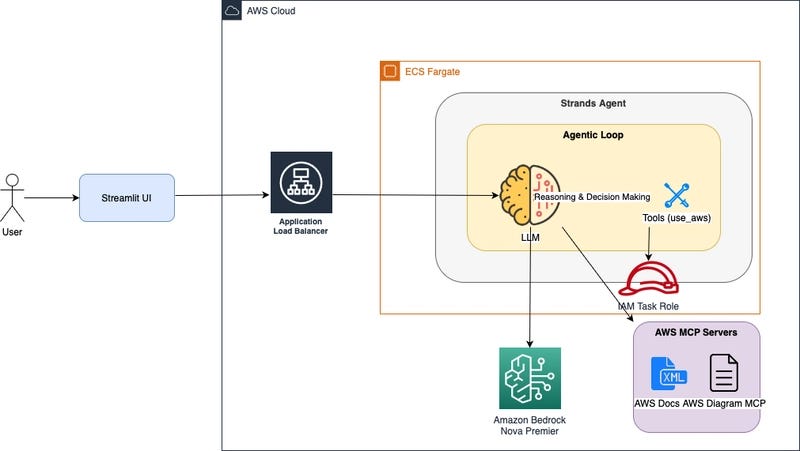
A brief exchange on X (formerly Twitter) has revealed a significant, quiet shift in how OpenAI evaluates its Claude models. In response to a user query, OpenAI engineer Boris Cherny confirmed that the company is actively phasing out the MRCR (Massive Multitask Chain-of-Thought Reasoning) benchmark from Claude's official system card and evaluation suite.
Key Takeaways
- An OpenAI engineer confirmed the company is phasing out the MRCR benchmark from Claude's system card, citing its poor correlation with real-world performance and high evaluation cost.
- This reflects a broader industry move toward more practical, cost-effective evaluation methods.
What Happened
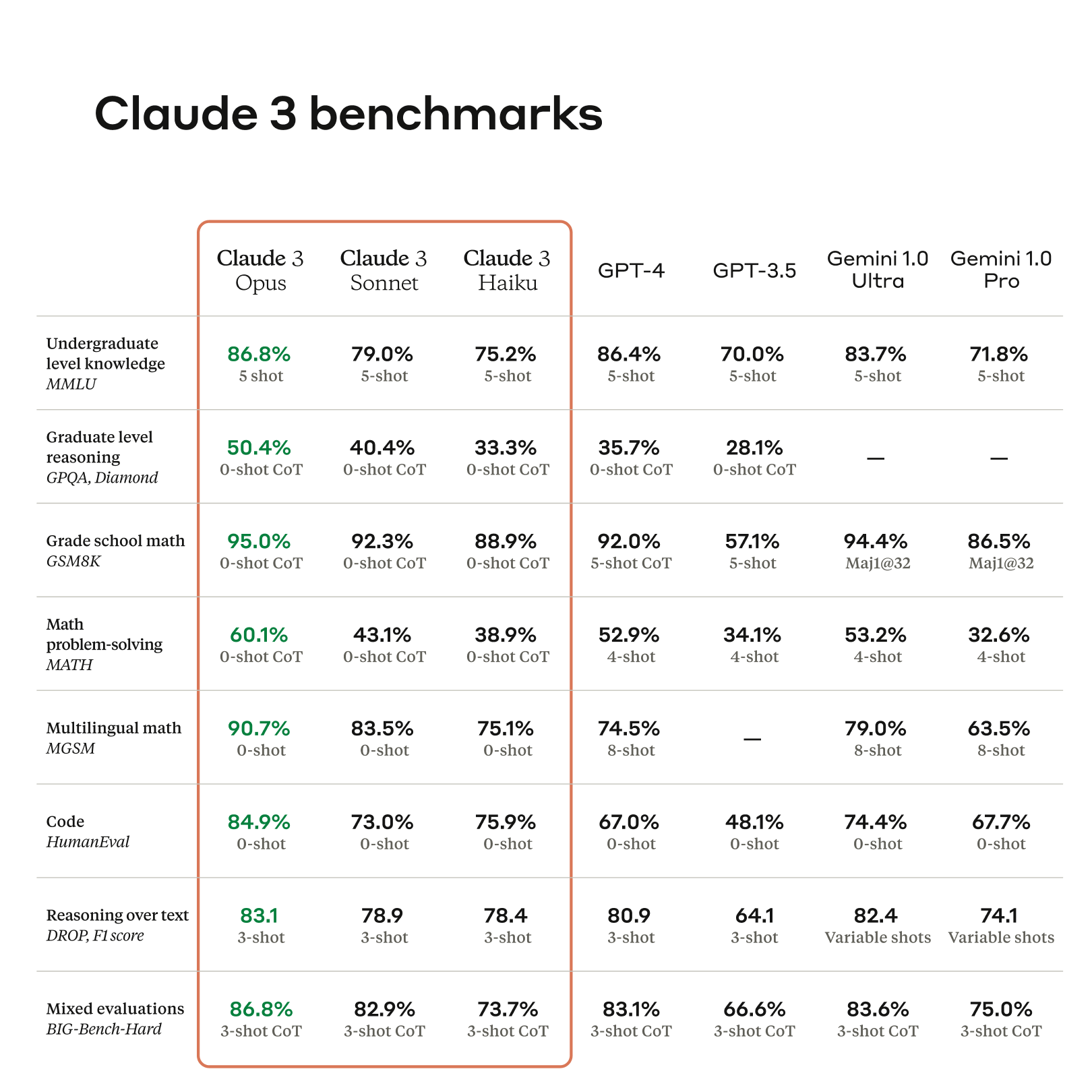
When asked by a user (@kimmonismus) about the inclusion of MRCR scores in Claude's system card—a document detailing model capabilities and evaluations—Cherny replied: "We kept MRCR in the system card for scientific honesty, but we've actually been phasing it out slowly."
He cited two primary reasons for the deprecation:
- Poor Correlation with Real-World Performance: The benchmark's results showed weak alignment with how the model actually performs in practical, production applications.
- High Evaluation Cost: Running the MRCR benchmark is computationally expensive, making it an inefficient use of resources for ongoing model assessment.
This admission indicates that the benchmark, while retained for transparency, no longer informs internal development priorities or is considered a reliable indicator of Claude's capabilities.
Context: The MRCR Benchmark
The Massive Multitask Chain-of-Thought Reasoning benchmark is a synthetic evaluation designed to test a model's complex, multi-step reasoning across a wide range of subjects. It requires models to generate explicit "chain-of-thought" reasoning traces before arriving at an answer. For several years, MRCR and similar reasoning-focused benchmarks have been staples in the system cards and research papers of major AI labs, including Anthropic (Claude), OpenAI (GPT series), and Google DeepMind (Gemini), serving as a public metric for comparing reasoning prowess.
However, a growing critique within the AI research community questions the validity of these synthetic benchmarks. Concerns include "benchmark contamination" (where models are trained on test data), the lack of correlation with real-world utility, and the high cost of running them. OpenAI's move to phase out MRCR aligns with this critical perspective.
What This Means in Practice
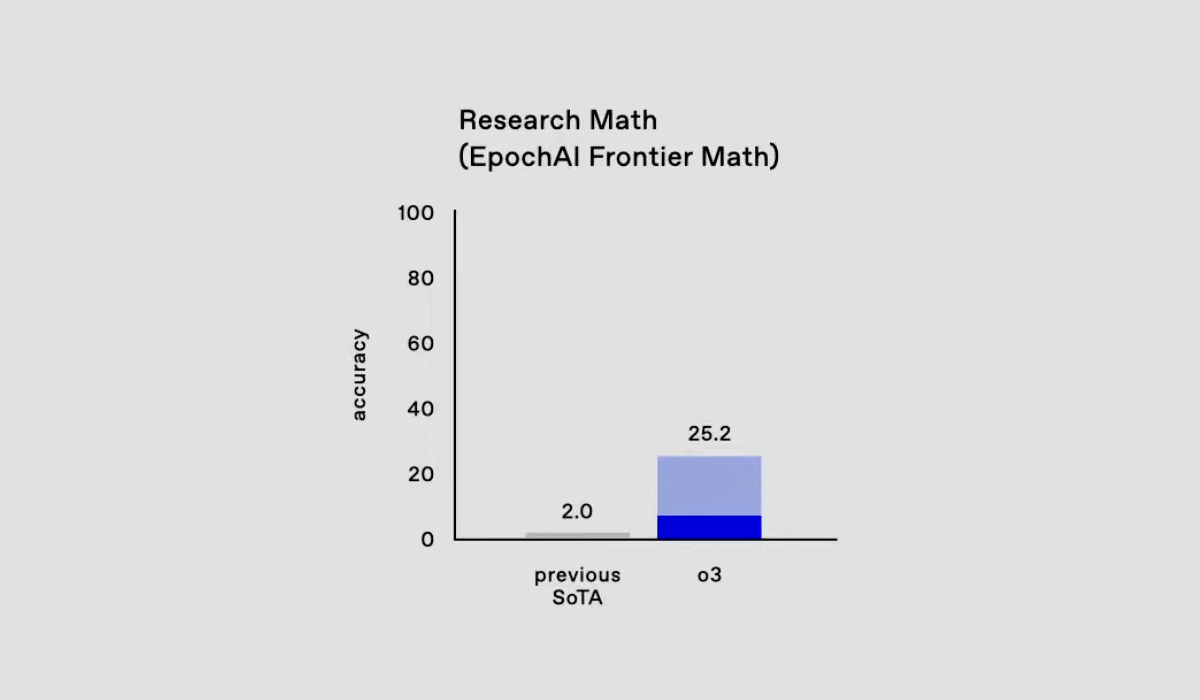
For developers and companies building with Claude's API, this change is a signal to de-prioritize MRCR scores when making decisions. The benchmark's decline suggests that OpenAI's internal evaluation is shifting toward metrics that better reflect performance in actual use cases—such as coding efficiency, agentic task completion, or enterprise workflow integration—rather than abstract reasoning tests.
gentic.news Analysis
This is a concrete example of the ongoing maturation and pragmatization of AI model evaluation. For years, the field has been dominated by a benchmark arms race, with labs touting incremental gains on standardized tests like MMLU, GPQA, and MRCR. OpenAI's quiet deprecation of MRCR is a significant data point in a broader trend we've been tracking: the industry's gradual pivot from synthetic benchmarks to real-world, cost-aware evaluation.
This move is consistent with OpenAI's established pattern of prioritizing product-market fit and developer utility over pure research accolades. It follows their earlier shift in 2025, where they began emphasizing "time to solve" and "user satisfaction" metrics for ChatGPT over raw scores on academic benchmarks. The high cost cited by Cherny is also a key factor; as model inference costs become a primary concern for scaling AI applications, expensive evaluation suites become harder to justify.
The deprecation also subtly challenges competitors who still heavily feature MRCR and similar benchmarks in their marketing. It raises the question: if a leader like OpenAI finds it misaligned, how valuable are these scores for developers choosing a model? This aligns with our previous reporting on "The Great AI Benchmark Reckoning" (Oct 2025), which highlighted growing skepticism toward benchmark leaderboards.
Looking forward, we expect this to accelerate the adoption of alternative evaluation frameworks. These include live, continuous evaluation on platforms like LMSys's Chatbot Arena, performance on curated real-world task suites like SWE-Bench, and cost-adjusted performance metrics. The era of relying on a single number from a synthetic test to gauge a model's worth is ending.
Frequently Asked Questions
What is the MRCR benchmark?
MRCR stands for Massive Multitask Chain-of-Thought Reasoning. It is a standardized test designed to evaluate an AI model's ability to perform complex, multi-step reasoning across diverse subjects like science, history, and logic. Models are prompted to "think out loud" (chain-of-thought) before providing a final answer.
Why is OpenAI phasing it out?
According to an OpenAI engineer, the company is phasing out MRCR for two main reasons. First, the benchmark's scores showed a poor correlation with how the Claude model actually performs in real-world, practical applications. Second, running the benchmark is computationally expensive, making it an inefficient use of resources for ongoing evaluation.
What should developers use to evaluate models instead?
Developers should focus on metrics that align with their specific use case. Instead of generic reasoning benchmarks, consider evaluating a model on:
- Domain-specific tasks: Code generation, document analysis, or customer support simulation.
- Real-world platforms: Performance on live evaluation platforms like LMSys's Chatbot Arena.
- Practical benchmarks: Verified, hands-on benchmarks like SWE-Bench for coding or agentic task completion rates.
- Cost-adjusted metrics: Performance per dollar of inference, which factors in both capability and operational expense.
Does this mean Claude's reasoning capabilities are getting worse?
No. Phasing out a benchmark is a change in measurement, not necessarily a change in the underlying model capability. OpenAI's statement suggests they believe MRCR was not a good measure of real-world reasoning to begin with. The company is likely shifting its evaluation focus to metrics it finds more meaningful, which could lead to improvements in the reasoning abilities that matter most to users.