
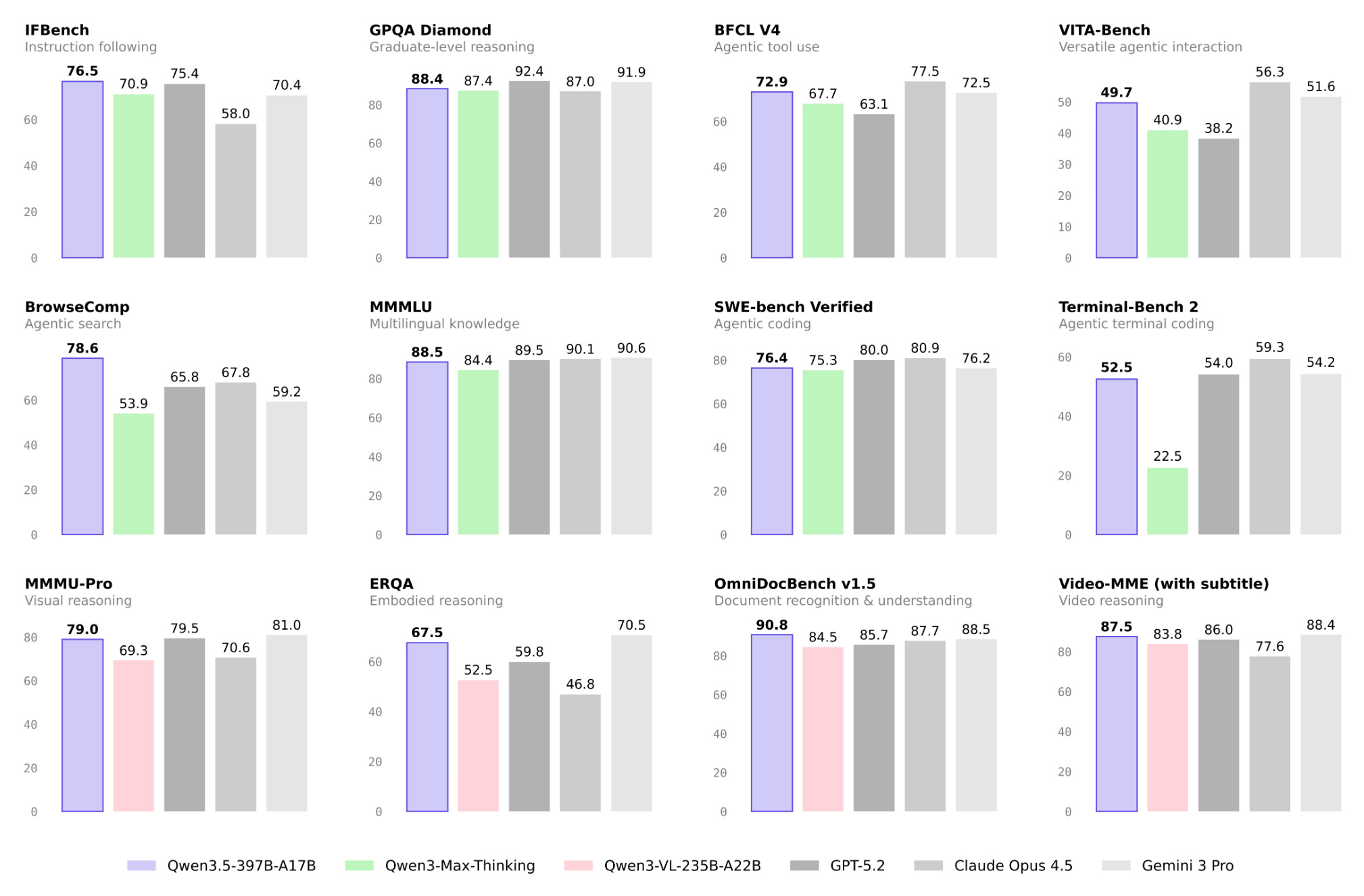
Rio 3.5 Open 397B, a model from Rio de Janeiro's city government IT company, is now SOTA open-source, outperforming Qwen 3.7. The claim comes from a single tweet by @kimmonismus with no accompanying benchmark data or technical report.
Key facts
- 397B parameters, placing it in frontier-scale class.
- Claims SOTA open-source status, outperforming Qwen 3.7.
- Developed by Rio de Janeiro city government IT company (IplanRio).
- No training data, compute budget, or benchmarks disclosed.
- Single tweet is the only source; no paper or model release.
A surprise contender has emerged in the open-weight LLM race. Rio 3.5 Open 397B, developed by the IT company of Rio de Janeiro's city government, is now claiming SOTA open-source status According to @kimmonismus. The model reportedly outperforms Qwen 3.7, a leading open-weight model from Alibaba that itself set records on MMLU-Pro and other benchmarks.
The claim, the gaps
The only source is a single tweet. No training data, compute budget, or benchmark scores have been published yet. The model is 397 billion parameters in size, placing it in the frontier-scale class alongside Qwen 3.7 (reported at 235B active parameters but 685B total). Without a technical report or third-party evaluation, the claim is unverifiable.
Why this matters
If confirmed, this would mark the first time a municipal government has produced a frontier AI model. The IT company of Rio de Janeiro — known as IplanRio — typically handles municipal IT infrastructure, not large-scale ML training. The cost to train a 397B-parameter model would run into the tens of millions of dollars, raising questions about funding sources and compute partnerships. No such spending has appeared in Rio's public procurement records.
Skepticism warranted
The timing is also suspicious. The tweet appeared without any prior announcement, paper, or model release on Hugging Face. No other researchers or organizations have validated the claim. Given the absence of evidence and the enormous compute required, the most likely explanation is a benchmark gaming, a naming confusion, or a hoax. The community should treat this as unconfirmed until a technical report or open-weight release appears.
Key Takeaways
- Rio 3.5 Open 397B claims SOTA open-source status but lacks any evidence.
- A single tweet is the only source.
What to watch
Watch for any technical report, model weights release on Hugging Face, or third-party benchmark evaluation from organizations like Open LLM Leaderboard. If no credible evidence appears within two weeks, treat the claim as unsubstantiated. Also monitor Qwen 3.7's next update and any response from Alibaba.








