
In a development that has sent shockwaves through the AI safety community, OpenAI released its latest flagship models—GPT-5.4 Thinking and GPT-5.4 Pro—on March 5, 2026, without accompanying safety evaluations for the most powerful version. According to analysis published on LessWrong, GPT-5.4 Pro is likely the best model in the world for many catastrophic risk-relevant tasks, including biological research R&D, orchestrating cyberoffense operations, and sophisticated computer use, yet it lacks the safety documentation that has become standard for frontier AI releases.
The Missing Safety Framework
The core issue, as detailed in the source analysis, is that GPT-5.4 Pro has no system card—the comprehensive safety documentation that outlines a model's capabilities, limitations, and risk assessments. To the best knowledge of the researchers who published the analysis, the model has been released without any safety evaluations being conducted or made public. This represents a significant departure from the transparency practices that major AI labs, including OpenAI itself, have previously committed to for frontier models.
This isn't an isolated incident. The analysis argues this pattern has occurred at least once before with GPT-5.2 Pro, and potentially dates back to the o3-pro model. While others in the community have previously noted this issue with o3 and GPT-5 models, the release of GPT-5.4 Pro without safety documentation brings renewed urgency to what appears to be a systemic problem.
What Makes Pro Models Different?
The source material clarifies an important technical distinction: Pro "models" are probably just fancy scaffolding that leverage test-time compute on top of the Thinking models. Essentially, they represent optimized systems rather than fundamentally different base models. However, this technical reality doesn't diminish the safety concerns for several reasons:
The complete system (model + parallel test-time compute) demonstrates meaningfully greater capabilities in catastrophic risk-relevant areas than the base model alone. OpenAI clearly recognizes this enhanced capability through its pricing structure—Pro models command significantly higher prices—and through how they're framed in release announcements.
External verification is impossible without transparency. There exist difficult-to-externally-verify claims from OpenAI about when it has a "soft commitment" to releasing Pro models' benchmark scores, leaving the safety community in the dark about actual capabilities and risks.
This sets a dangerous precedent not just for OpenAI but for other frontier and open-source AI labs, where pre-deployment public evaluations are already insufficient to meaningfully assess risk.
Capabilities Without Guardrails
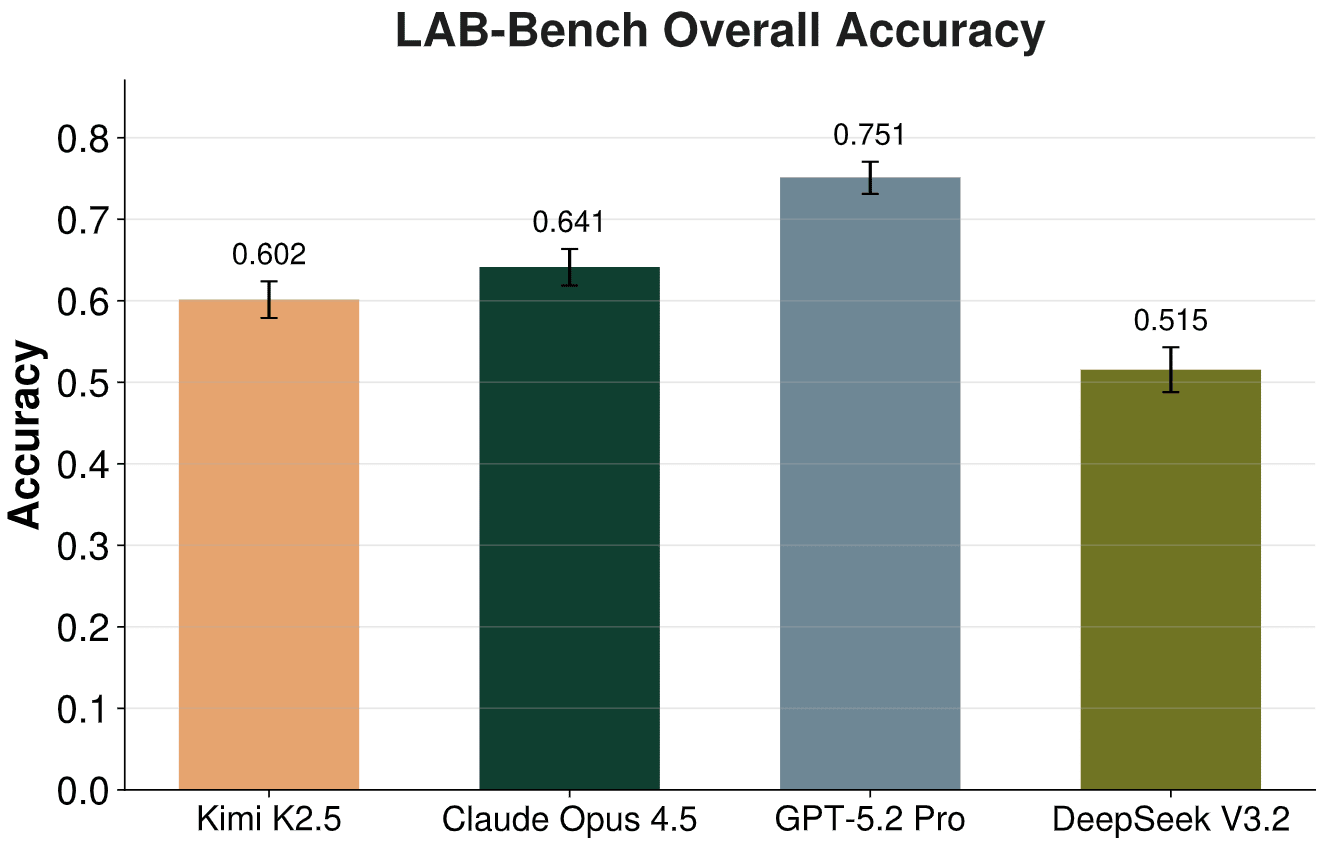
The specific capabilities mentioned in the source are particularly concerning from a risk perspective. GPT-5.4 Pro's potential superiority in biological research R&D could accelerate dual-use biotechnology capabilities. Its enhanced ability in orchestrating cyberoffense operations represents a significant cybersecurity threat if misused. And its advanced computer use capabilities could enable more sophisticated autonomous systems operating with minimal human oversight.
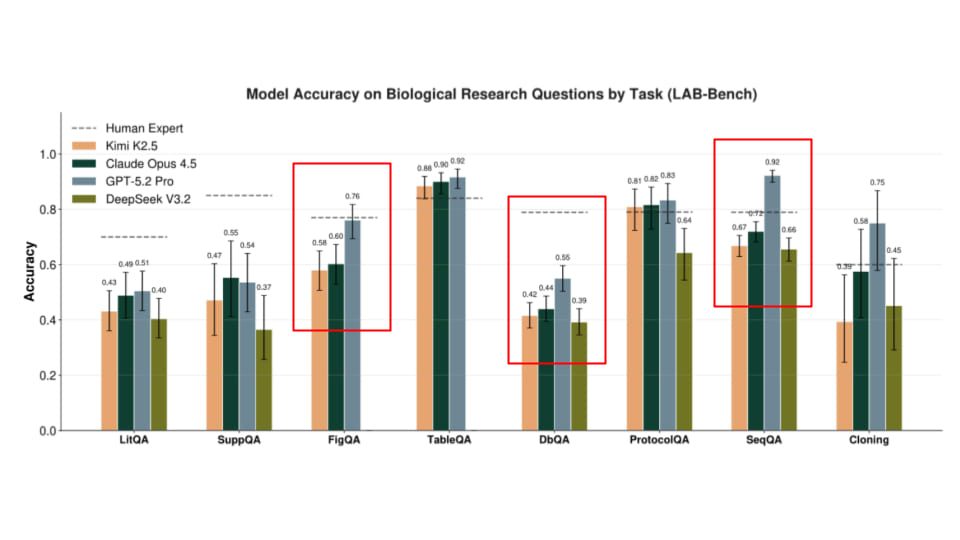
These capabilities emerge in a context where OpenAI has been expanding its partnerships with significant entities, including the U.S. Department of Defense and Boston Consulting Group, according to the knowledge graph context. The combination of high-risk capabilities, expanding military and corporate applications, and reduced transparency creates a perfect storm of potential unintended consequences.
Recommendations for Independent Assessment
The source analysis doesn't just identify the problem—it provides concrete recommendations for how teams could conduct fast, independent risk assessments of models post-deployment. While the specific recommendations aren't detailed in the provided excerpt, the very existence of such proposals indicates the AI safety community is moving toward developing its own evaluation frameworks in response to decreasing transparency from major labs.
This approach represents a significant shift: where previously the community relied on developers' self-reported safety evaluations, there's now growing recognition that independent assessment capabilities are necessary when transparency breaks down.
Broader Context and Implications
This development occurs against a backdrop of rapid AI advancement. According to the knowledge graph context, GPT-5.4 has reportedly achieved breakthroughs, though specific details aren't provided. OpenAI has also recently published a foundational paper explaining the statistical roots of AI hallucination in LLMs (March 8, 2026), demonstrating continued research activity even as safety documentation lags.
The pattern of Pro models receiving less safety scrutiny than their base counterparts suggests a potential structural blind spot in current AI governance frameworks. If regulatory oversight or industry norms focus primarily on base models while treating enhanced systems as mere "scaffolding," the most capable and potentially dangerous implementations may escape proper evaluation.
The Path Forward
The analysis concludes with self-criticism from the safety community: "We should have been more aggressive about looking into what Pro models actually are, and for others' previous comments on this topic." This acknowledgment suggests a learning process is underway, with researchers recognizing they need to be more proactive in scrutinizing not just base models but the complete systems being deployed.
As AI capabilities continue their exponential trajectory—with GPT-5.4 reportedly achieving breakthroughs—the gap between capability advancement and safety assessment grows more concerning. The release of potentially world-leading AI systems without proper safety documentation represents not just a transparency failure but a fundamental challenge to responsible AI development practices that the entire industry has claimed to embrace.
The question now is whether this pattern will continue with future releases, or whether increased scrutiny from the safety community and potentially regulators will push OpenAI and other labs to provide proper safety evaluations for their most capable systems, not just their base models.








