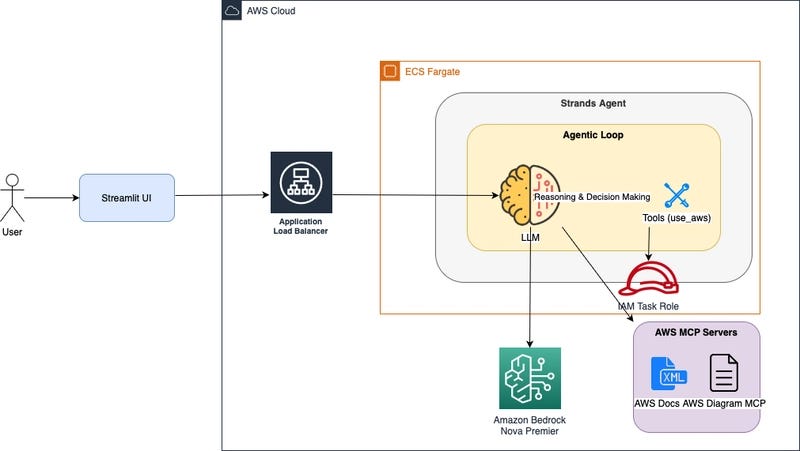
Tencent has released HY-World 2.0, a state-of-the-art 3D world model, on Hugging Face. The model generates real, navigable 3D worlds—not just videos—from text or image prompts and can reconstruct scenes from photos in a single forward pass.
What the Model Does

HY-World 2.0 represents a significant step beyond previous 3D content generation models. Instead of producing static 3D assets or video sequences, it creates interactive, navigable 3D environments. This means the generated worlds have spatial coherence and can be explored from multiple viewpoints, similar to environments in game engines or virtual reality applications.
The model accepts two types of input:
- Text descriptions: Users can describe a scene (e.g., "a medieval castle courtyard at dusk")
- Reference images: Users can upload a photo, and the model reconstructs it as a 3D scene
Critically, the generation happens in one forward pass, suggesting an efficient architecture that avoids iterative refinement steps common in some 3D generation pipelines.
Technical Significance
While the source tweet doesn't provide detailed benchmarks, the description as "SOTA" (state-of-the-art) and the focus on "navigable 3D worlds" indicates several technical advancements:
- Spatial Consistency: Generating coherent 3D geometry that holds up from multiple angles is more challenging than producing 2D images or videos.
- Single-Pass Generation: The "one forward pass" claim suggests the model uses a feed-forward architecture rather than slower iterative methods like score-based diffusion.
- Multi-Modal Understanding: The ability to work from both text and images indicates robust cross-modal representation learning.
This release follows Tencent's established pattern of contributing to open-source AI research, particularly in computer vision and generative models. The company's previous work includes various vision-language models and 3D reconstruction techniques.
Potential Applications
HY-World 2.0's capabilities suggest several immediate use cases:
- Game Development: Rapid prototyping of game environments
- Virtual Production: Creating background scenes for film and television
- Architectural Visualization: Generating 3D representations from sketches or descriptions
- Virtual Reality: Populating VR environments with custom scenes
- Training Data Generation: Creating synthetic 3D environments for robotics and autonomous system training
The model's availability on Hugging Face means researchers and developers can immediately experiment with it, potentially leading to rapid iteration and application development.
Limitations and Considerations

Without published benchmarks or a detailed paper, several questions remain:
- Resolution and Detail: The tweet doesn't specify the fidelity or polygon count of generated worlds.
- Scene Complexity: It's unclear what scale of environments the model can handle (room-scale vs. landscape-scale).
- Navigation Constraints: "Navigable" suggests walkable surfaces, but the extent of physical simulation isn't specified.
- Training Data: The dataset used for training hasn't been disclosed, which affects understanding of potential biases.
gentic.news Analysis
Tencent's release of HY-World 2.0 represents a strategic move in the increasingly competitive 3D generative AI space. This follows the company's April 2025 launch of their Hunyuan-DiT architecture, which demonstrated significant improvements in image generation quality. The progression from 2D image generation to 3D world creation shows Tencent's systematic approach to building a comprehensive generative AI stack.
The timing is notable given NVIDIA's recent advances in 3D Gaussian Splatting and Google's ongoing work with NeRF-based reconstruction. While those approaches focus on reconstruction from multiple views, HY-World 2.0 appears to prioritize generation from minimal inputs (single image or text), positioning it for different use cases.
From a market perspective, this aligns with Tencent's broader investments in metaverse infrastructure and gaming technology. As we reported in February 2026, Tencent has been aggressively expanding its AI capabilities across entertainment and social platforms. A robust 3D world generation model could significantly reduce content creation costs for their massive gaming portfolio and emerging virtual social spaces.
The "single forward pass" architecture is particularly interesting from an efficiency standpoint. Most high-quality 3D generation methods today require multiple optimization steps or iterative refinement. If HY-World 2.0 delivers comparable quality with substantially lower computational cost, it could make 3D content generation accessible to a much wider range of developers and creators.
However, the true test will come when independent researchers benchmark HY-World 2.0 against established 3D generation methods. Key metrics to watch will include geometric accuracy, texture quality, and the realism of lighting and materials—all crucial for practical applications.
Frequently Asked Questions
What is HY-World 2.0?
HY-World 2.0 is a 3D world generation model developed by Tencent that creates navigable 3D environments from text descriptions or single images in one computational pass.
How is this different from previous 3D AI models?
Previous models typically generated either static 3D objects or 2D videos. HY-World 2.0 creates complete 3D environments that can be explored from multiple viewpoints, making them suitable for interactive applications like games and VR.
Can I try HY-World 2.0 myself?
Yes, the model is available on Hugging Face, meaning researchers and developers can download and experiment with it immediately, though computational requirements haven't been specified.
What are the main limitations of this technology?
Without published benchmarks, limitations around scene complexity, generation quality, and computational requirements remain unclear. The model likely works best with certain types of scenes and may struggle with highly complex or specific architectural details.