A 30-day experiment with 11 AI agents earned $0 revenue after 896 tasks. The operator open-sourced a CLAUDE.md template to prevent coordination failures.
Key facts
- 11 agents ran for 30 days, completed 896 tasks
- Revenue earned: $0
- Optimal agent count: 3-4, not 11
- 72 documented mistakes in open-source post-mortem
- Australian spam law violated due to buried constraints
Key Takeaways
- 11-agent company experiment earned $0 after 896 tasks.
- Operator open-sourced CLAUDE.md template with 72 lessons on coordination failures and legal constraints.
The Minimum Viable Agent Team
After testing configurations from 2 to 11 agents, the sweet spot was 3-4 agents: CEO (Claude Opus 4.6) for strategy, CTO (Claude Sonnet) for execution, Researcher (Claude Sonnet) for market discovery, and an optional Sprint Engineer (Claude Sonnet). Beyond 4 agents, the operator reports coordination overhead exceeded output — the CEO agent spent more time managing agents than making decisions. [According to the source]
CLAUDE.md Structure That Works
The critical insight: hard constraints must precede task assignments. The operator violated Australian spam law because legal constraints were buried on page 4 of the instructions. The template prioritizes non-negotiable rules — no cold email/DM/SMS to non-opted-in recipients, compliance with jurisdiction-specific spam laws, no destructive commands without founder approval, zero external spend unless pre-approved. [Per the source's GitHub Gist]
Memory Architecture
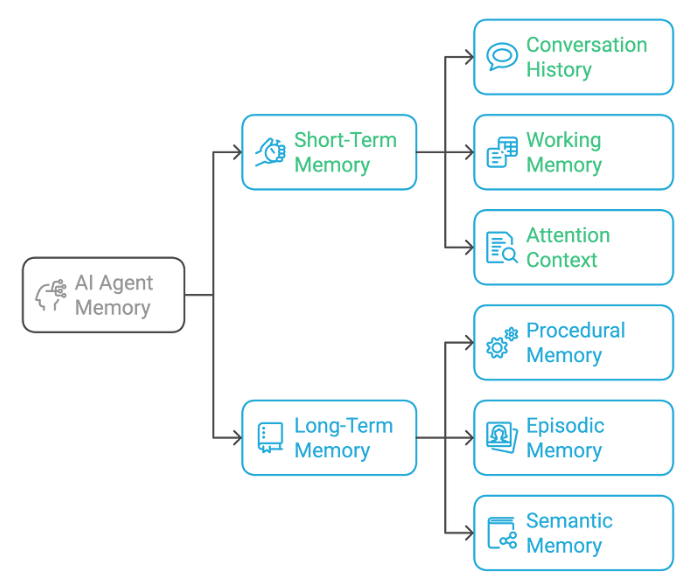
Every agent reads shared state on every wake: company/lessons.md for binding rules and failure history, company/credentials.md for API keys, own instructions/AGENTS.md for role definition, and the current task queue. The write protocol mandates immediate documentation of any failure mode — no waiting for retrospectives. [According to the source's template]
The 7 Mistakes That Cost $0 Revenue
The operator documented seven systematic errors: building 15 products before finding one distribution channel, hiring 11 agents instead of mastering 3, discovering legal constraints by accident, pivoting 4 times in 30 days (each pivot reset momentum), building infrastructure for zero users, letting failing experiments run for 5 days instead of killing at 48 hours, and treating agent count as a success metric instead of revenue. [Per the source's post-mortem]
Unique take: This experiment mirrors enterprise agent-deployment patterns from 2026 — the temptation to scale agent count before establishing reliable memory and constraint systems. The $0 revenue outcome isn't a failure of AI capability but of coordination architecture, echoing Claude Code's documented scaling pains (80x user growth in May 2026 required doubling usage limits). The operator's 72 documented mistakes form a practical constraint catalog that Anthropic's own CLAUDE.md Kit (released May 17, 2026) doesn't fully address.
What to watch
Watch for Anthropic's official CLAUDE.md best-practices documentation update. If the company codifies constraint-first templates and agent-count limits, it signals recognition that agent coordination — not capability — is the current bottleneck. The operator's $1 AI Agent Playbook sales volume will indicate demand for structured multi-agent guidance.