Anthropic deployed protective measures for Claude Mythos 5 despite concluding it did not cross the CB-2 novel bioweapons threshold. The gap between threshold-triggered governance and actual decisions exposes a structural flaw in biorisk frameworks.
Key facts
- Anthropic concluded Mythos 5 met CB-1 but not CB-2 bioweapons thresholds.
- Protective measures were deployed for both thresholds regardless of CB-2 status.
- Anthropic activated ASL-3 protections for Opus 4 in 2025 despite threshold uncertainty.
- The measurement gap creates a structural downward bias toward 'not crossed'.
- Intermediate warning levels would invert the evidence asymmetry toward caution.
In the Claude Mythos/Fable 5 system card, Anthropic states that the model meets non-novel (CB-1) but falls short of novel (CB-2) biological/chemical weapons development capability thresholds. Despite this difference in conclusions, they introduce protective measures in response to both.
This is not the first time there's been a gap between threshold-triggered and actual governance decisions. In 2025, Anthropic activated AI Safety Level 3 (ASL-3) protections with the release of Claude Opus 4 despite being uncertain whether capability thresholds had been met. Anthropic's Responsible Scaling Policy (RSP) v3 discussion further elaborates that capability evaluations may not produce a clean line between "safe" and "dangerous" and labs may spend significant time in what it calls a "zone of ambiguity."
Key Takeaways
- Anthropic deployed protections for Mythos 5 despite CB-2 not being crossed.
- The gap reveals a structural bias in biorisk thresholds that intermediate warning levels could fix.
The Measurement Gap Creates a Downward Bias
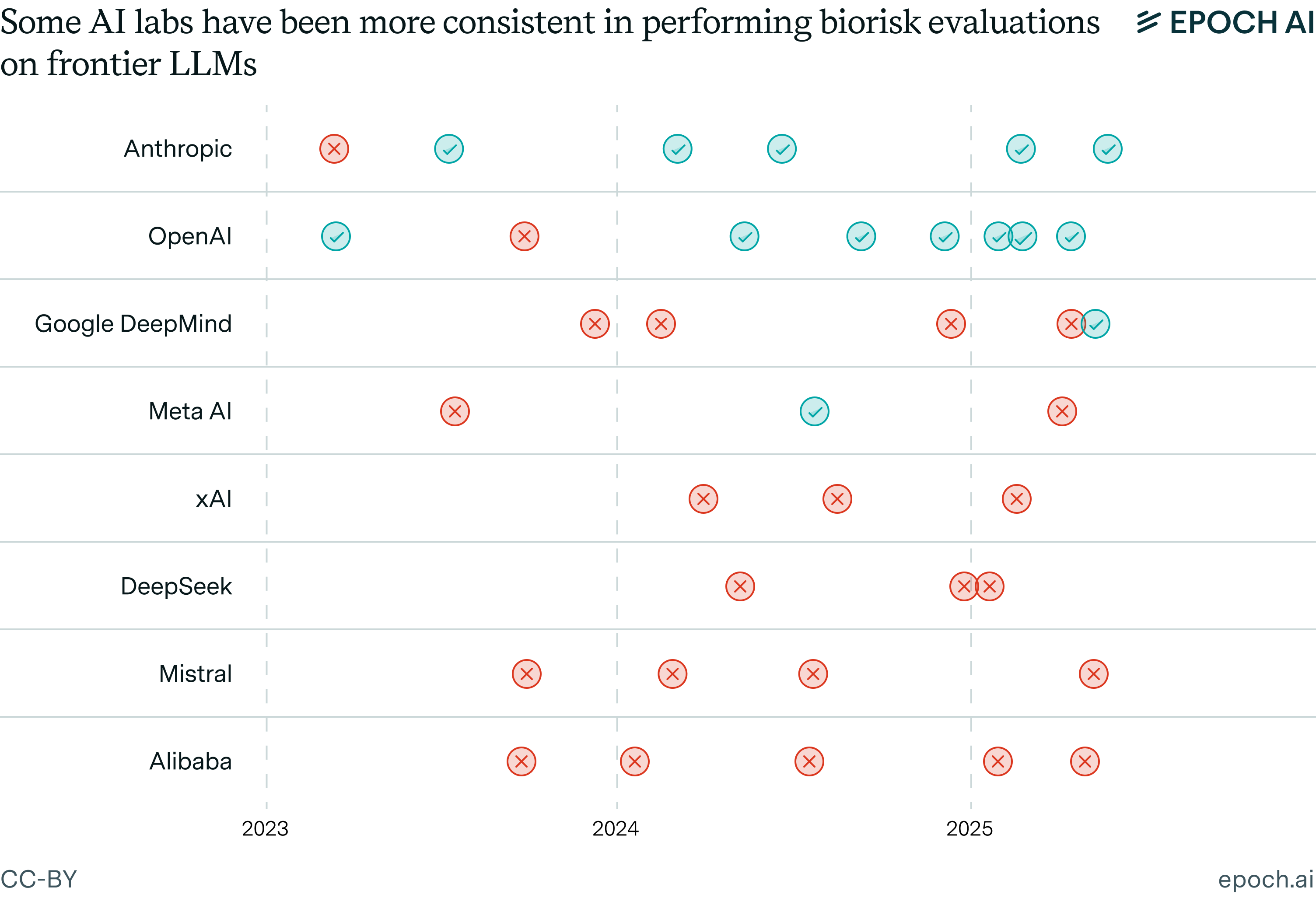
The core problem is an asymmetrical burden of evidence. To say that the model crosses the CB-2 threshold and should trigger associated protections, you need evidence that it's close to end-to-end weapons development. To conclude that it doesn't cross the threshold, you only need to cite one missing or uncertain part of the process. This measurement gap is unavoidable in biorisk—it would be highly unethical for a lab to test end-to-end whether their model is able to design, validate, formulate, and deploy novel biological weapons.
So proxy evidence can always be framed as suggestive but insufficient if thresholds are defined around terminal end states. This creates a downward bias towards "not crossed" conclusions, even if the lab may still decide to deploy protective measures. Any such deployments would also happen at the lab's discretion and would not be associated with any pre-committed trigger.
Intermediate Warning Levels: A Proposal
The proposal is that frontier labs should keep those thresholds as red lines but add intermediate warning levels between them focused on bottleneck reduction rather than demonstrated end-to-end weaponization. The key design property should be that triggers for protective measures map to data a lab can actually collect, like time-to-completion in uplift trials or the degree of human correction required. The intermediate triggers shouldn't aim to prove definitive safety or danger, but should instead focus on specific bottlenecks of the decomposed end-to-end process, perhaps segmented by knowledge vs. execution.
Tying the triggers to measurable outcomes mapped to substeps of the end-to-end process would also help invert the asymmetry. With terminal thresholds, missing-piece evidence argues for "not crossed." With intermediate warning levels, evidence argues for escalation and the burden shifts to justifying why not to escalate. Labs would commit to the margins that'd trigger escalation in advance, removing room for motivated reasoning after seeing the results.
What to watch
Watch for Anthropic's next RSP update or system card—if they introduce intermediate warning levels, it would signal a structural shift in biorisk governance. Also monitor whether other frontier labs like OpenAI or Google DeepMind adopt similar tiered warning frameworks in their safety policies.
Source: lesswrong.com