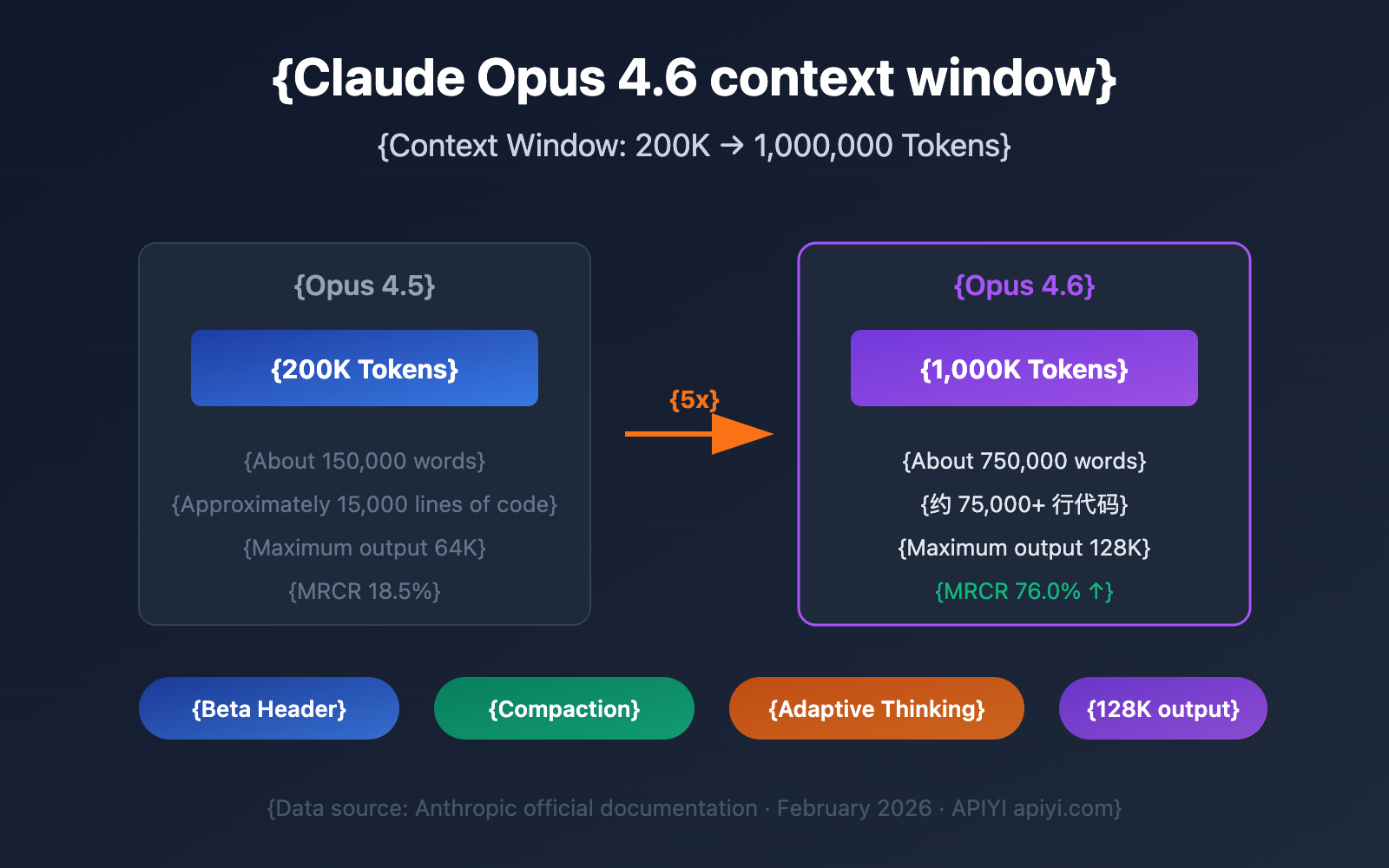
Key Takeaways
- Audit your ~/.claude/skills for temperature, budget_tokens, and 'show your reasoning'.
- Replace 6+ step procedures with goal+constraints.
- Cut MUST/NEVER blocks to only guard money, deletions, or identity.
What Changed — The Fable 5 Breaking Patterns

Anthropic's Fable 5 migration docs contain a warning that should stop every Claude Code skill maintainer cold:
"Skills developed for prior models are often too prescriptive for Claude Fable 5 and can degrade output quality."
Not "may need updates." Degrade output quality. The instructions you carefully wrote to make older models behave are now actively making the new model worse.
API-level hard breaks:
temperature/top_p/top_k→ rejected outright- Extended-thinking budgets (
budget_tokens) → rejected; Fable 5 is adaptive-thinking only - Assistant prefill → removed from the API
- "Show your reasoning in the response" → can now trip the
reasoning_extractionrefusal category, which silently falls back to Opus 4.8. Your skill keeps "working" — at different quality and 2× the price, with no error message.
Quality degraders (the sneaky ones):
- Enumerated 6+ step procedures — the #1 pattern Anthropic calls out. State the goal and constraints; the model derives the steps.
- Dense MUST/ALWAYS/NEVER blocks — "you can steer most behaviors with a brief instruction rather than enumerating each behavior by name."
- Permission gates on every step — pause only for destructive/irreversible actions or input only the user has.
- "List all possible options" demands — produces overplanning. Ask for a recommendation with the main tradeoff.
- Token-countdown surfacing — makes the model prematurely summarize and bail.
What It Means For You — The Silent Degradation Trap
If you maintain Claude Code skills, the risk is invisible. Your skills will keep running — but with degraded output quality, potentially at 2× the cost if reasoning_extraction triggers a fallback to Opus 4.8. No error message. No alert. Just worse results.
One developer audited their 31-skill fleet after Fable 5's release:
- 0 API-breaking patterns — lucky, but only known after scanning
- 13 skills with quality-degrading prescription — including a 9-step enumerated procedure and a skill with 11 MUST/NEVER directives
- 18 long-run skills missing new patterns — no self-verification cadence, no progress-grounding
The fix wasn't rewriting everything. It was deletion, mostly. A skill that took a week to write needed 20 minutes of cutting.
Try It Now — Audit Your Skills in 5 Minutes
Run this to find breaking patterns immediately:
# Find API-breaking patterns
grep -r 'temperature\|budget_tokens\|show your reasoning' ~/.claude/skills
# Find quality-degrading patterns
grep -rn 'MUST\|ALWAYS\|NEVER\|^[0-9]\. ' ~/.claude/skills | head -30
# Count step procedures
grep -c '^[0-9]\.' ~/.claude/skills/*.md
Migration checklist for each skill:
- Delete any
temperature,budget_tokens, or "show your reasoning" lines - Replace 6+ step procedures with: "Goal: [what to achieve]. Constraints: [what to avoid]."
- Cut MUST/NEVER blocks to only guard real invariants: money, deletions, identity
- Remove permission gates on non-destructive steps
- Remove "list all options" demands — ask for a recommendation instead
- Remove token countdown references
- Add a self-verification cadence for long-running tasks
Example before/after:
Before (prescriptive):
1. Analyze the codebase structure
2. Identify all files containing API endpoints
3. List all possible error handling approaches
4. MUST check each file for security vulnerabilities
5. NEVER modify production code without approval
6. ALWAYS include unit tests for each change
7. Report progress after every 3 files
After (goal-oriented):
Goal: Identify and fix API error handling gaps across the codebase.
Constraints: Never modify production code without explicit approval. Include unit tests for each change.
Pause for confirmation before: destructive operations, production changes.
The model will handle the rest better than your checklist ever could.
Source: news.google.com
[Updated 10 Jun via gn_claude_community]
The new source reveals concrete benchmark data: Claude Fable 5 scores 80.3% on SWE-Bench Pro against GPT-5.5's 58.6% and Gemini 3.1 Pro's 54.2%, while on Cognition's FrontierCode it achieves 29.3% versus GPT-5.5's 5.7% [per Dev.to]. Pricing is $10/$50 per million tokens (input/output), double Opus 4.8 but well under GPT-5.5 Pro at $30/$180. Anthropic's Boris Cherny discussed Claude Code's flexible AI workflows in a separate interview, though no new migration-specific guidance emerged.