A new prompt engineering technique called CLAUDE.md is gaining attention for its claim to dramatically reduce token usage when working with Anthropic's Claude models. According to developer Omar Sar, the method can cut Claude's output tokens by approximately 63% while maintaining functionality, requiring no code changes to implement.
What CLAUDE.md Does
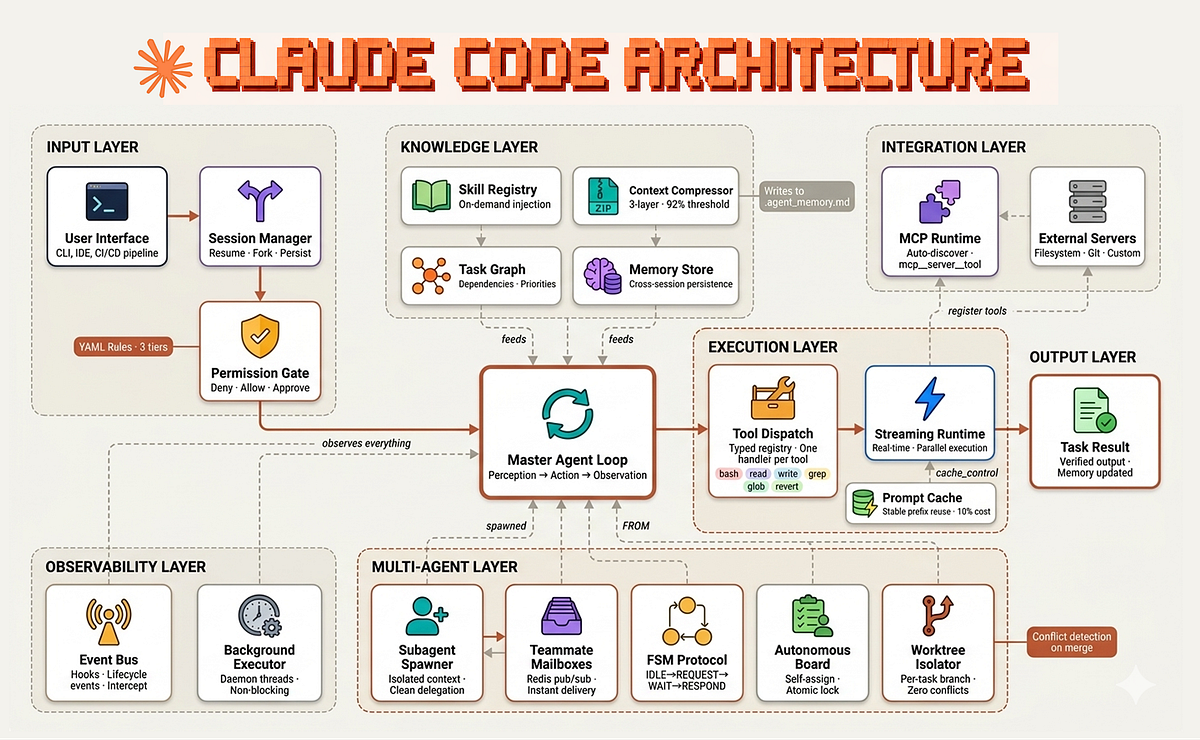
CLAUDE.md is a structured prompt file that users can add to their projects to steer Claude's code generation behavior. The approach appears to work by providing Claude with explicit formatting instructions and response templates that minimize verbose explanations while preserving the essential code output.
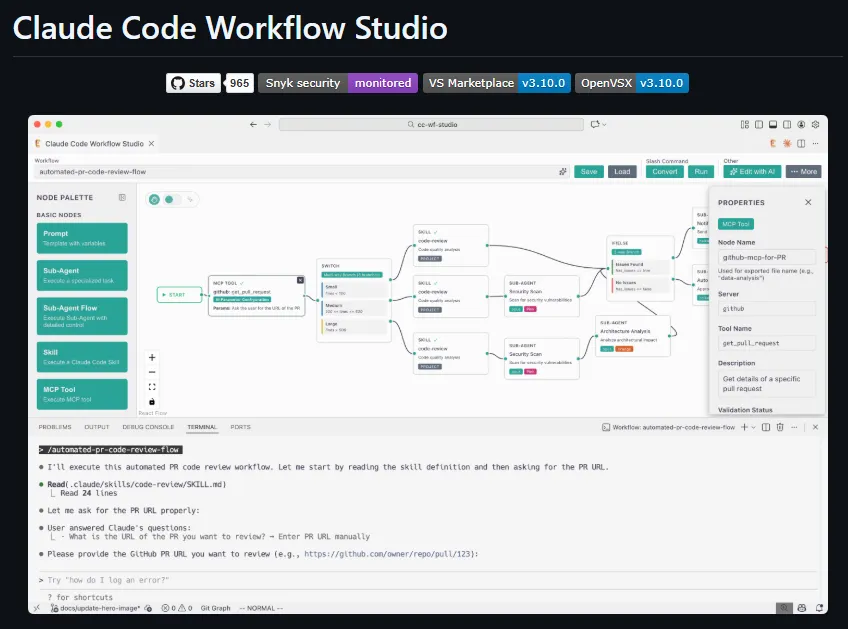
Unlike traditional prompt engineering that requires modifying API calls or implementing complex post-processing, CLAUDE.md functions as a drop-in solution. Users simply include the file in their project directory, and Claude recognizes and follows its formatting guidelines automatically.
How It Works
The exact contents of CLAUDE.md aren't fully detailed in the announcement, but based on similar prompt engineering techniques, it likely includes:
- Response templates that constrain output format
- Token optimization instructions that tell Claude to prioritize concise responses
- Code generation patterns that eliminate unnecessary commentary
- Structured output requirements that reduce formatting tokens
Sar describes it as "one of the best ways to steer Claude Code," suggesting the file has been optimized specifically for programming tasks where verbosity adds cost without value.
Practical Implications
For developers using Claude API, a 63% reduction in output tokens translates directly to cost savings. Claude 3.5 Sonnet currently costs $3 per million input tokens and $15 per million output tokens, making output optimization particularly valuable for code generation workflows.
A typical code generation session that might produce 1,000 tokens of output would drop to approximately 370 tokens with CLAUDE.md, reducing the output cost from $0.015 to $0.0055 per request.
Limitations and Considerations
The announcement doesn't specify which Claude models the technique works with, though it's likely optimized for Claude 3.5 Sonnet given its current popularity for coding tasks. The 63% reduction claim also needs independent verification, as prompt engineering results can vary significantly based on:
- Specific use cases and programming languages
- Model versions and updates
- Initial prompt quality before optimization
- Task complexity and requirements
Implementation
Users can reportedly implement CLAUDE.md by:
- Adding the CLAUDE.md file to their project directory
- Including reference to it in their initial prompt
- Letting Claude adapt its output format accordingly
No API changes, parameter adjustments, or post-processing code is required, making it accessible even for developers with minimal prompt engineering experience.
gentic.news Analysis
This development fits into the growing trend of prompt optimization tools that emerged throughout 2025 as AI API costs became a significant consideration for production applications. Following the release of Claude 3.5 Sonnet in June 2024, which set new benchmarks for coding assistance, developers have been seeking ways to reduce the operational costs of integrating these models into their workflows.
The CLAUDE.md approach aligns with similar prompt engineering techniques we've covered, such as the "System Prompt Optimization" methods that gained popularity in late 2024. However, its claim of 63% token reduction is notably higher than the 20-40% improvements typically seen with general prompt optimization.
What makes this approach particularly interesting is its drop-in nature. Unlike more complex optimization frameworks that require integration work, CLAUDE.md appears designed for immediate adoption. This could accelerate its uptake among developers who want cost savings without implementation overhead.
The timing is significant as we enter 2026 with AI development costs under increased scrutiny. With major players like OpenAI, Anthropic, and Google continuing to refine their pricing models, third-party optimization tools like CLAUDE.md fill an important niche in the ecosystem.
Frequently Asked Questions
How does CLAUDE.md actually reduce token usage?
CLAUDE.md provides Claude with structured response templates that minimize unnecessary words, formatting, and explanations. By constraining the output format and eliminating verbose commentary that often accompanies code generation, it reduces the total tokens Claude produces while maintaining the essential code output.
Will CLAUDE.md work with all Claude models?
The announcement doesn't specify model compatibility, but prompt engineering techniques typically work across model families with varying effectiveness. It's likely optimized for Claude 3.5 Sonnet, which is currently the most popular model for coding tasks, but may provide benefits with other Claude models as well.
Is there any risk to code quality with token reduction?
Any token reduction technique carries some risk of removing useful context or explanations. However, CLAUDE.md appears focused on eliminating verbose commentary rather than essential code, aiming to preserve functionality while reducing cost. Users should test thoroughly with their specific use cases.
How does this compare to other prompt optimization methods?
CLAUDE.md's claimed 63% reduction is significantly higher than typical prompt optimization gains of 20-40%. Its drop-in implementation also differs from more complex frameworks that require API modifications or post-processing. The approach seems specifically tailored for Claude's code generation patterns rather than general-purpose optimization.