Key Takeaways
- Towards AI article explains counterfactual evaluation methods (IPS, SNIPS, doubly robust) for ad ranking models.
- These techniques estimate model performance from logged data without A/B tests, critical for recommendation systems in retail.
What Happened
A new article on Towards AI breaks down the challenge every recommendation system team faces: how to evaluate a new ranking model without running a full A/B test. The article focuses on three counterfactual evaluation methods—Inverse Propensity Scoring (IPS), Self-Normalized Inverse Propensity Scoring (SNIPS), and Doubly Robust estimation—that allow teams to estimate model performance from historical logged data.
The core problem is selection bias: the data you have was generated by the old model, not the new one. Comparing outcomes directly would be misleading because the items shown (and not shown) were chosen by a different policy. Counterfactual evaluation corrects for this by reweighting or modeling the missing counterfactuals.
Technical Details
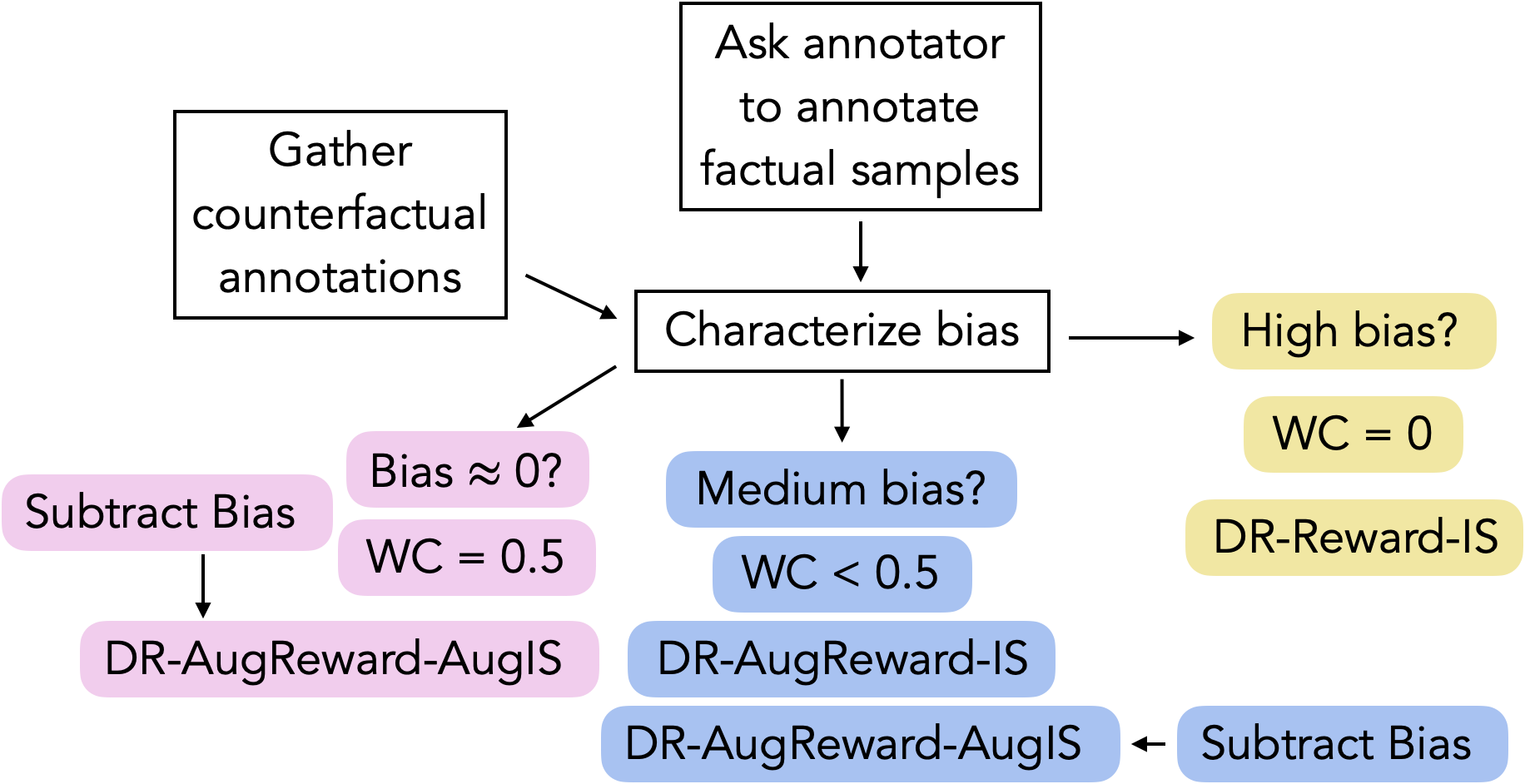
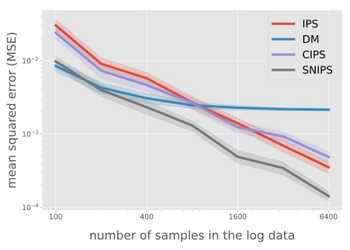
IPS (Inverse Propensity Scoring) reweights each logged observation by the inverse of the probability that the old model would have taken that action. If a recommendation was rare under the old policy, its outcome gets higher weight when evaluating the new policy. The article explains the bias-variance tradeoff: IPS is unbiased but can have high variance when propensity scores are small.
SNIPS (Self-Normalized IPS) addresses this by normalizing the weights so they sum to 1, reducing variance at the cost of a small bias. This makes it more stable in practice, especially when propensity scores vary widely.
Doubly Robust combines IPS with a direct model of the outcome (e.g., a regression model predicting click-through rate). It is unbiased if either the propensity model or the outcome model is correct—hence "doubly robust." The article walks through the math and practical considerations, including how to estimate propensity scores from logged data.
Retail & Luxury Implications
For retail and luxury recommendation systems—whether for e-commerce product ranking, personalized email campaigns, or ad targeting—this is directly applicable. A/B tests are expensive, time-consuming, and risk exposing customers to suboptimal recommendations. Counterfactual evaluation lets teams iterate faster.
- Product recommendation ranking: A luxury fashion retailer can evaluate a new ranking model using historical click and purchase data, without running a live test that might show less relevant products to high-value customers.
- Ad creative optimization: IPS can estimate which ad creative would have performed better under a different targeting policy, using past campaign data.
- Personalization for VIP segments: For small but high-value segments (e.g., VIC customers), A/B tests may not have enough statistical power. Counterfactual methods can provide faster, more reliable estimates.
However, the article acknowledges a key limitation: these methods rely on accurate propensity estimation. If the old model's logging policy is not well understood, estimates can be biased. For luxury brands with complex, multi-stage personalization, this requires careful implementation.
Business Impact
- Faster iteration: Teams can evaluate dozens of model variants per week instead of running sequential A/B tests.
- Lower risk: No live exposure to potentially worse recommendations.
- Cost savings: Reduces infrastructure costs for running and monitoring A/B experiments.
- Better for long-tail items: Counterfactual methods can surface insights for rare products (e.g., limited-edition luxury goods) that never get enough traffic in A/B tests.
Implementation Approach
- Logging infrastructure: Ensure you log the action taken, the probability of that action under the old policy (propensity score), and the outcome (click, purchase, etc.).
- Propensity estimation: If the old policy is deterministic or unknown, you may need to train a model to estimate propensities from logged data.
- Metric selection: Choose the right estimator (IPS, SNIPS, or doubly robust) based on your data characteristics and tolerance for bias vs. variance.
- Validation: Use synthetic data or holdout experiments to validate that your counterfactual estimates align with actual A/B test results.
Governance & Risk Assessment
- Bias risk: If propensity models are inaccurate, estimates can be misleading. Regular validation against live A/B tests is recommended.
- Data privacy: Logged data must be anonymized and stored securely, especially for luxury customers.
- Maturity: These methods are well-established in academic literature but require skilled ML engineers to implement correctly in production.
Source: pub.towardsai.net