AI Research
84
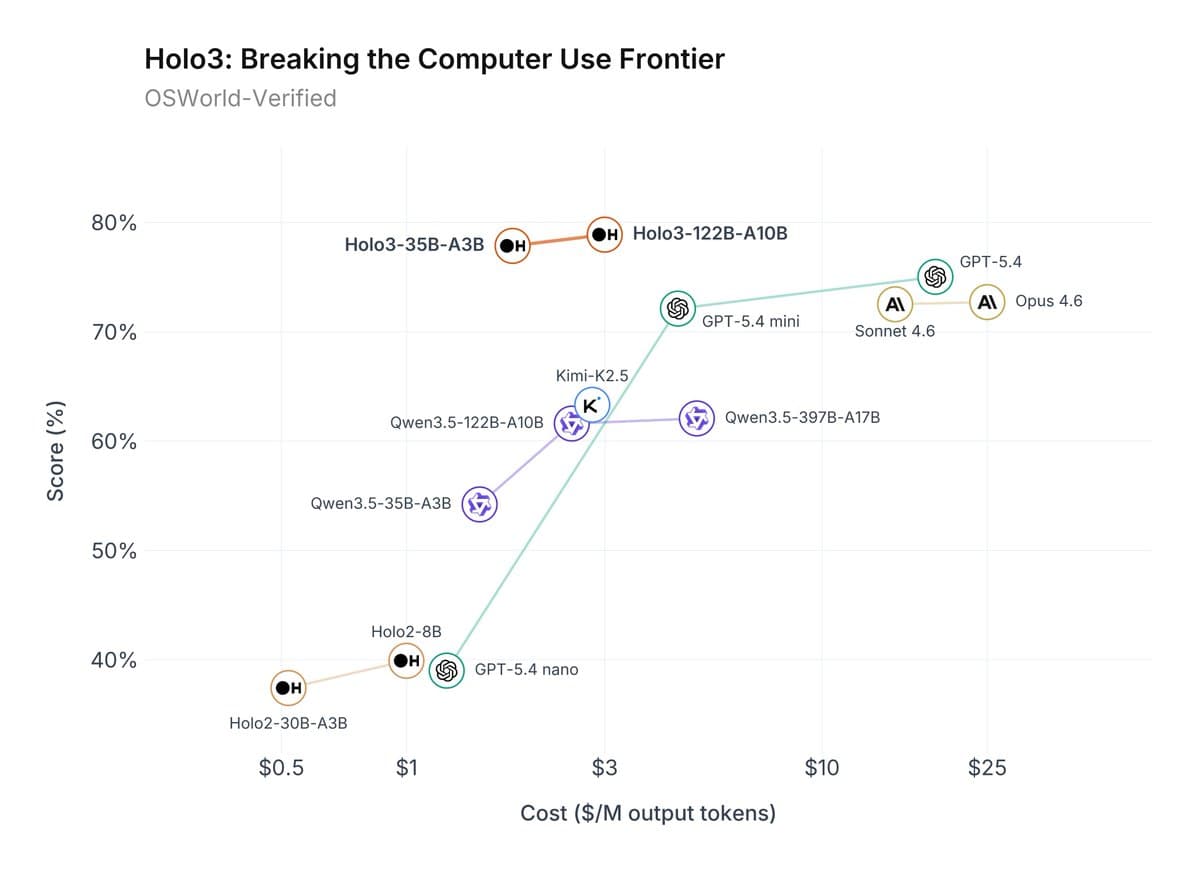
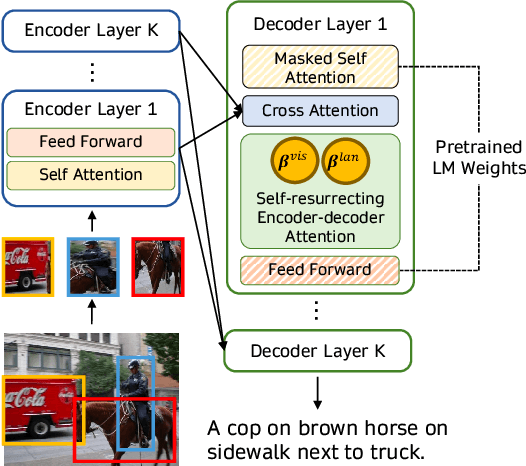
HIVE Framework Introduces Hierarchical Cross-Attention for Vision-Language Pre-Training, Outperforms Self-Attention on MME and GQA
A new paper introduces HIVE, a hierarchical pre-training framework that connects vision encoders to LLMs via cross-attention across multiple layers. It outperforms conventional self-attention methods on benchmarks like MME and GQA, improving vision-language alignment.
arxiv.org/Apr 2, 2026/3 min read
architecturetransformerresearch